【Python PuLP版】包絡分析法(DEA)モデル【CCRモデル】

【はじめに】
このnoteでは「包絡分析法(DEA)モデル」について、「Python PuPL」でプログラムを作ってみる。
※PuLP
内容としては「Python MIPで書いた記事」を「PuLP」でやるものだが、サンプルデータにはPandasで作成したDataFrameを使用したり、PuLPの使い方、全体的な説明や図を追加をしたり等、少しアレンジを入れている。
【実行環境について】
今回は「Google Colab」上で実行してみる。
【例題】
以下の「店舗0~5」について「店員数、稼働時間、売上」のデータが次の通りになっている。
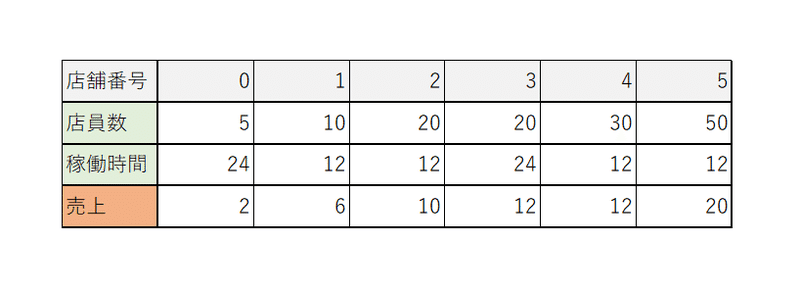
・入力データ:「店員数」「稼働時間」
・出力データ:「売上」
として、「店舗番号4」について「DEAに基づいた効率性の評価」をせよ。
※詳しい考え方などは以下参照。
【1】ライブラリのインストール
!pip install pulp【2】ソルバーセットアップ
import pulp
# 対応ソルバー一覧を出力
pulp.list_solvers(onlyAvailable=False)【実行結果例】
['GLPK_CMD', 'PYGLPK', 'CPLEX_CMD', 'CPLEX_PY', 'GUROBI', 'GUROBI_CMD', 'MOSEK', 'XPRESS', 'PULP_CBC_CMD', 'COIN_CMD', 'COINMP_DLL', 'CHOCO_CMD', 'MIPCL_CMD', 'SCIP_CMD']
# 利用可能なソルバー
pulp.list_solvers(onlyAvailable=True)【実行結果例】
['PULP_CBC_CMD']
今回はデフォルトのソルバーを使っていくが、必要に応じて追加でソルバーをインストール、パスを追加する。
(※例えば「GLPK(Gnu Linear Programming Kit)」を追加する場合は以下参照ください)
【3】サンプルデータ作成(DataFrame作成)
サンプルデータは「pandas」を使って「DataFrame」として用意してみる。
※作成するDataFrameのイメージ
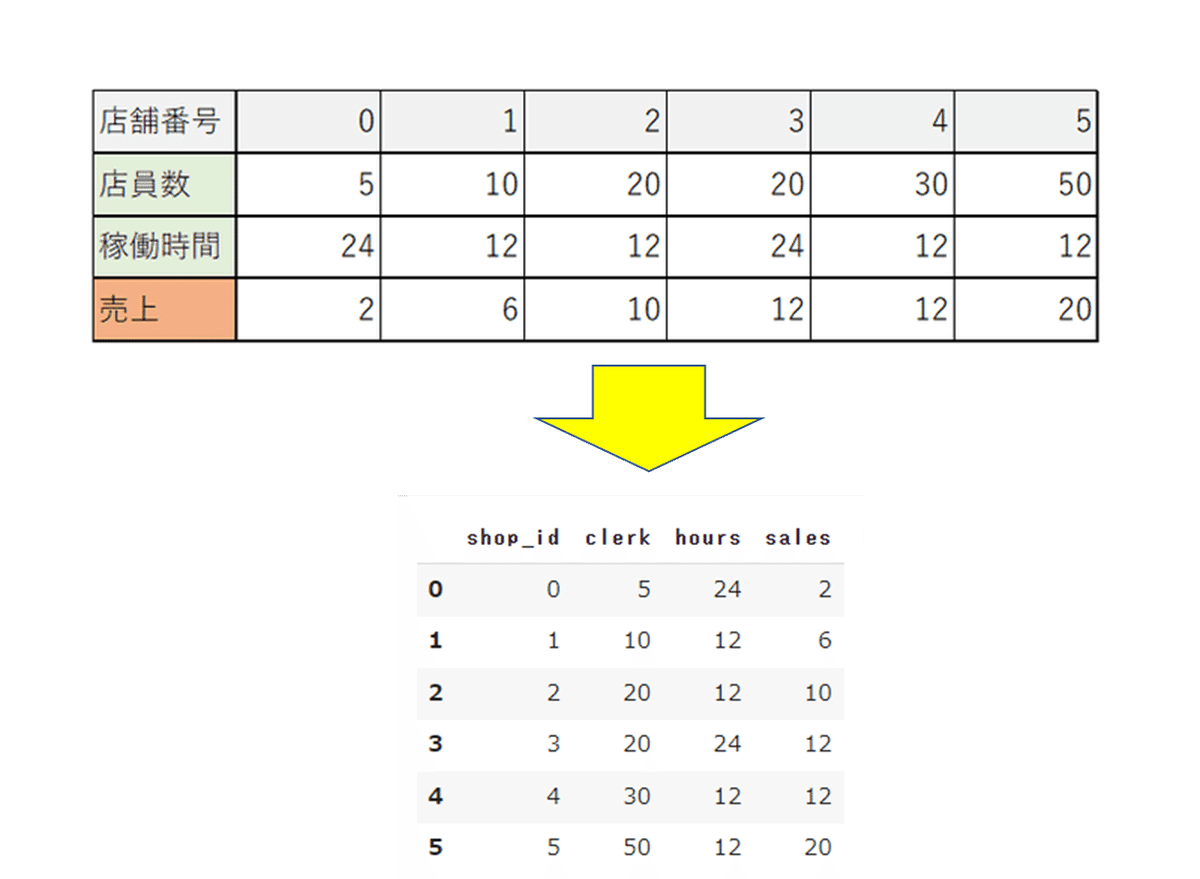
サンプルデータをDataFrame化するにあたり、今回は「pandas.DataFrame.from_dict()」を使っていく。
ここから先は
¥ 100
もっと応援したいなと思っていただけた場合、よろしければサポートをおねがいします。いただいたサポートは活動費に使わせていただきます。