
Vision Transformer(ViT)の革新性とビジネスへの応用

先日、画像認識に関するプロジェクトに関わる機会を頂きましたが、そこで用いた手法の話を簡単に解説することにしました。
Vision Transformer(ViT)とは何か?
Vision Transformer(ViT)は、画像認識分野において、従来のConvolutional Neural Network(CNN)に代わる画期的なアプローチです。このモデルは、画像を小さなパッチ(16x16ピクセルなどの小領域画像)に分割し、それぞれのパッチを一つの単語(Token)として扱います。これにより、画像内の広範囲の情報を捉える能力を持ち、CNNでは困難だった画素間の遠隔関係も把握可能です。
どのように機能するのか?
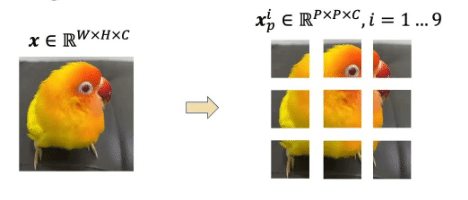
Vision Transformer(ViT)は、もともと自然言語処理(NLP)で革新をもたらしたトランスフォーマー(Transformer)という技術を基にしています。トランスフォーマーは、文章の各単語間の関係を理解するために開発され、特に生成AI技術であるChatGPTなどに応用されています。ViTはこのトランスフォーマー構造を画像認識に転用することで、各画像パッチ間の関連性を詳細に捉え、より洗練された画像理解を実現しています。この技術的転換は、画像データを処理する新しいアプローチとして注目され、高い認識精度と効率性を提供します。
具体的に言うと、各画像パッチはまず特徴ベクトルに変換され、さらにTransformerのEncoderに入力されます。ここでは、Self-Attentionメカニズムがパッチ間の関連性を分析し、全体としての画像認識を行います。ViTの大きな特徴は、学習可能なClass Tokenを用いたクラス識別であり、これにより画像分類の精度が飛躍的に向上します。
ビジネスへの応用
ViTの技術はAI製品やサービスの質を向上させる要素として重要です。たとえば、商品画像の自動分類や、顧客からの画像データを基にしたカスタマイズサービスの提供が考えられます。また、ViTは大規模データセットでの学習が得意であり、膨大な画像データからのインサイト抽出に非常に有効です。
まとめ
Vision Transformerは、画像全体の広範な情報を活用することで、従来のCNNよりも高い精度を達成しています。
ご興味のある方は、Furious GreenのAI技術トレーニングや製品戦略コンサルティングサービスを通じて、Vision Transformerの潜在力をご自身のビジネスでどのように活用できるかを探求してみませんか?ぜひ私たちにご相談ください。
この記事が気に入ったらサポートをしてみませんか?