
その2「農業生態系のデジタル化」ってなんだろう

前回の投稿に引き続き、以下のプレスリリースの研究について整理していきたいと思います。
前回の投稿では、どのようなデータを使って解析したのだろう?という点をまとめました。そこでは、”土壌–土壌微生物–作物の3つの階層で、網羅的なデータ(オミクスデータ)を取ってきて、そして階層を超えてそれらのデータの関係性を解析しようとした”ということが、この研究の新しい点であるという風に述べました。
では次に、ここで言う階層を超えたデータの関係性の解析、つまり表題の「農業生態系のデジタル化」とは一体どのようなものかという話に入っていきます。この部分が恐らくこの研究の一番理解しがたい部分だと思います。一言で表すと「(相関)ネットワーク解析」というものになるのですが、
①ネットワークとは何か?
②どのようにネットワークの解析を行うのか?
という点についてゆっくり整理していきます。
ネットワークとは何か?
ネットワークとは何でしょうか?私自身”インターネット”というネットワークに日常的に触れていますので、何となくイメージはできます。が、改めてネットワークとは何なのか?と聞かれると難しいところはあります。
ネットワークとは、点(頂点、ノード)とそこから伸びる枝(エッジ、リンク)の集合のことを言います。非常にシンプルな定義です。確かにインターネットというものを考えても、ウェブサイトやパソコン・ルーターといったものを頂点とすると、今言ったネットワークを描くことができるのかなと思います。実体のないインターネットを例にすると私は少し分かりにくいので、現実的な例を挙げます。例えば、交通網(鉄道網や高速道路網、航空網)が身近なネットワークの例と言えるでしょう。鉄道網であれば駅が”頂点”、線路が”枝”に該当します。また、人間の作ったものだけでなく、生物の神経系や生態系(食物連鎖や生物と環境の関係性など)などもネットワークの様相を示しています。今でこそインターネットというイメージが強いネットワークという言葉ですが、案外身の回りのあらゆるものにネットワークの構造を見つけることができるのではないかなと思います。

高速道路路線図
(https://www.mlit.go.jp/common/001193162.pdfより)

航空路線図(JAL)
(https://www.jal.com/ja/csr/report/pdf/index_2014_19.pdfより)
さて、少し余談にはなるのですが、今回対象にしている「農業生態系のネットワーク」とはどのような形・特徴を持っているのでしょうか。例えば、上に示した高速道路網と航空網では、どちらがより農業生態系のネットワークに近いと言えるしょうか?
答えは航空網の方です。航空網をよく観察してみると、羽田空港や大阪国際(伊丹)空港など枝(路線)が非常にたくさん出ている点(飛行場)と、広島空港や仙台空港のように2〜3本しか枝の出ていない点があるのが分かります。このように一部の頂点は沢山の頂点のつながっている一方で、残り多数の頂点はわずかな数の頂点としか繋がっていないようなネットワークを、スケールフリー・ネットワークと呼びます。また、スケールフリー・ネットワークの中で多くの頂点とつながっている点(羽田空港や大阪国際空港のような点)をハブという風に呼びます。ハブ空港のハブです。細かい説明は省略しますが、生態系など多くの現実のネットワークは、このスケールフリー・ネットワークの特徴を持っている、と言うのが現在の複雑ネットワークの主流な認識となっているようです。
どのようにネットワークを描くのか?
前回の記事にあった”マルチオミクスデータ”からネットワークを描いていくわけですが、その前にまず簡単な例で、ネットワークの統計的な扱い方を考えてみましょう。

上のようなネットワークを描きたい場合に、どのようにして統計的に扱うのか?という話ですが、以下のような”隣接行列”という行列に変換するのが基本になります。
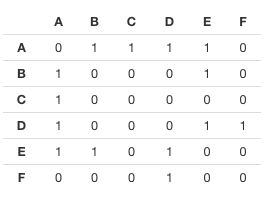
上の行列では、点と点が繋がっている場合を1、繋がっていない場合を0で表しています。例えば、AとBは繋がっているので上から1行目で左から2列目の値は1になっています。同様に、CとDは繋がっていないので上から3行目で左から4列目の値は0です。このような行列データに変換できれば、あとはRやPythonなどの統計解析ツールで、用意されているパッケージを使って先ほどのようなピンクのネットワークを描くことができるのです(今回の例はRのvisNetworkというパッケージを使って描写しています)。

論文より(https://www.pnas.org/content/pnas/117/25/14552.full.pdf)
研究の話に戻りますが、上の図のAが今回の農業生態系のデジタル化の結果、つまり農業生態系のネットワークを今説明したような方法で描写したものになります(Bはその一部を拡大したものです)。ここでは、マルチオミクス解析によって得られたデータの項目、例えば、コマツナの乾燥重量や土壌のCa含量、ある土壌微生物の量などが上のネットワークの一つ一つの頂点になっていて、それらのデータが互いに連動している場合に枝で繋がるようになっています。まず、これらの項目のデータ(それぞれ16サンプル分のデータを含んでいて、事前に正規化という計算を行なって項目間のデータのばらつき方の違いなどを揃えています)間の相関係数を計算していきます。相関とは、一方が増加するともう一方が増加または減少するような二変数の関係性のことで、その相関の大きさを表すのが相関係数(R)という値です。例えば、肥料の施用量を増やすと収穫量が増えるような(正の)相関関係がある場合には、二つのデータの相関係数は大きく(1に近い値)になります(ただし、相関係数だけでは因果関係があるかどうかまでは判断できません)。そして、頂点どうしが繋がるかどうか(例えば、コマツナの乾燥重量と土壌のCa含量に関係性があるか)をその相関係数を元に評価して、先ほどの隣接行列を作ります。なお、今回の研究では、頂点間の関係性を先ほどの例のように0か1の隣接行列データにするのではなくて、関係性の強さで重み付けを行なって0〜1の間の数字で表された隣接行列にしています(適切なスケールフリー・ネットワークになるように閾値 βを設定して、R^βで重み付けした結果を隣接行列にしています)。そして(できた隣接行列を、2つの頂点がどのくらい共通の頂点と繋がっているかを表すようなトポロジカル・オーバーラップ行列というものに変換した上で(細かい話なので省略します))Rのigraphというパッケージを使って上記のネットワークを描写する、というような話になります。どうしてもかなり細かい話になってはしまいましたが、項目間の相関係数から隣接行列を作ってネットワークのグラフを書くというが大まかな流れになっています。
このようなネットワークを描くと、例えば農家にとって重要なコマツナの重量や葉長が、どんな土壌の成分や土壌の微生物と連動しているかなというのを可視化することができる、ということになります。では次の投稿で、こうした解析の結果、何がわかったのか?というのを整理していきたいと思います。
この記事が気に入ったらサポートをしてみませんか?