
GPTsのActionsでSupabaseやGoogle books APIと連携して洋書多読体験を向上させる

1. 目的
英語力を高めるためにChatGPTのサポートを受けながら洋書を毎日読んでいます。このような「毎日やる」系の取り組みに大切なことはモチベーションを維持することです。そのためのひとつの方法として「記録をする」というのはそれなりに効果があると思っています。
そこで今回は読書記録をしてくれるGPTを作ってみました。読書記録をするためだけにGPTを使う必然性は無さそうですが、意味の無さそうな遊びの積み重ねの中で素晴らしい成果が得られることもあるだろうということでやってみました。
2. やったこと
2.1. DBの設計
Supabaseというものを下記の記事で知ってから使ってみたいと思っていました。というのもDBを活用することでGPTsが長期記憶を獲得できればかなりの弱点を克服できそうな気がしたからです。
というわけでまずはどういうDBを作ろうかなと考えたのですが、毎度恒例の非エンジニアであるという言い訳をしながらChatGPTに相談しました。



Google Books APIとか言っていますが、本に関するAPIを調べてこれにしようと思いました。洋書に強そうな気がしたから、というのと大企業が好きだからです。

CREATE TABLE Book (
BookID SERIAL PRIMARY KEY, -- 本のID、自動生成される一意の識別子
Title VARCHAR(255) NOT NULL, -- 本のタイトル
Authors TEXT[], -- 著者の名前の配列
ISBN VARCHAR(20), -- ISBN番号
PublishedDate DATE, -- 出版日
Description TEXT, -- 本の概要や説明
CoverImageURL VARCHAR(255), -- 表紙画像のURL
AverageRating NUMERIC(3, 2), -- 平均評価
PageCount INT, -- ページ数
Language VARCHAR(20), -- 言語
Categories TEXT[] -- カテゴリの配列
);よくわからないですがかっこよさげなテーブル案を示してくれました。
「読むのに何日かかったか」がわかれば「ページ数」と合わせて読むスピードをおおよそ把握できるかなと思ったので追加してもらいました。たたき台があるとアイディアも浮かんできます。

CREATE TABLE Book (
BookID SERIAL PRIMARY KEY, -- 本のID、自動生成される一意の識別子
Title VARCHAR(255) NOT NULL, -- 本のタイトル
Authors TEXT[], -- 著者の名前の配列
ISBN VARCHAR(20), -- ISBN番号
PublishedDate DATE, -- 出版日
Description TEXT, -- 本の概要や説明
CoverImageURL VARCHAR(255), -- 表紙画像のURL
AverageRating NUMERIC(3, 2), -- 平均評価
PageCount INT, -- ページ数
Language VARCHAR(20), -- 言語
Categories TEXT[], -- カテゴリの配列
StartDate DATE, -- 読み始めた日付
FinishDate DATE -- 読み終わった日付
);最終的には読書記録テーブルも下記のようになりました。
CREATE TABLE ReadingRecords (
RecordID SERIAL PRIMARY KEY, -- 記録ID、自動生成される一意の識別子
BookID INT NOT NULL, -- 本のID、Bookテーブルの外部キー
ReadingDate DATE NOT NULL, -- 読書日付 (年月日のみ)
StartPage INT NOT NULL, -- 読み始めたページ
EndPage INT NOT NULL, -- 読み終えたページ
FOREIGN KEY (BookID) REFERENCES Book(BookID)
);それっぽいDBになってご満悦です。
2.2. Supabaseの環境構築
Supabaseではいくつかプランがあるのですが、もちろん無料プランで始めました。プロジェクトを二つまで作れて、容量等に制限があるようですが、個人で遊び半分に使う分には十分そうです。ChatGPTからもらったSQLをそのまま投げてテーブルが完成しました。

2.3. GPTs側のセッティング
次にSupabaseをGPTs側から使えるようにするためにActionsにSchemaを書いていかなければなりません。これの敷居が高すぎて辛いところですが何とか楽に実装したいところです。今回はSupabase側に下記のようなドキュメントがあったので活用させてもらいました。
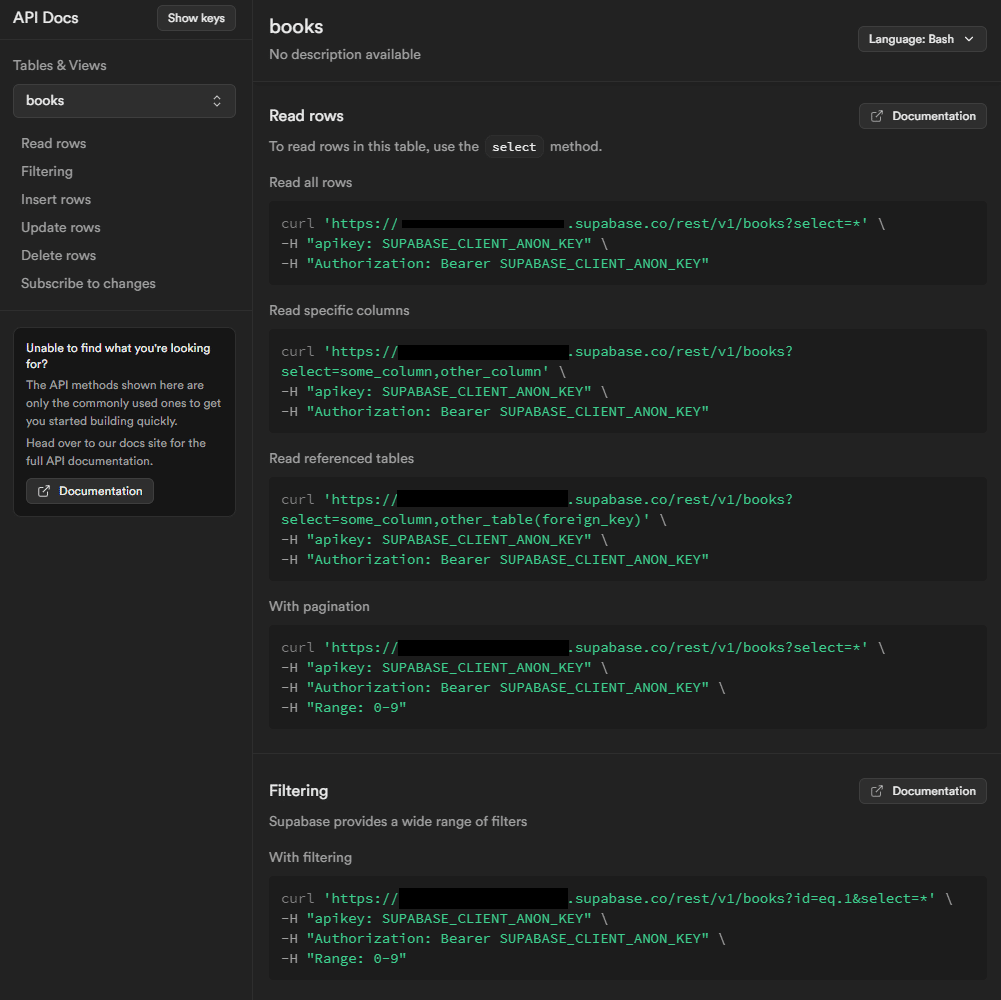
それぞれのコマンドのサンプルをコピーできるようになっていたのでコピーして以下のような感じでダメもとでChatGPTに丸投げしてみました。


{
"openapi": "3.0.0",
"info": {
"title": "Supabase API",
"version": "1.0.0"
},
"servers": [
{
"url": "https://***************************.supabase.co"
}
],
"paths": {
"/rest/v1/users": {
"post": {
"summary": "Add a new user",
"description": "Creates a new user in the users table.",
"operationId": "addUser",
"requestBody": {
"description": "User to add",
"required": true,
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"some_column": {
"type": "string",
"example": "someValue"
},
"other_column": {
"type": "string",
"example": "otherValue"
}
}
}
}
}
},
"responses": {
"200": {
"description": "User created"
}
},
"security": [
{
"apikeyAuth": []
}
]
}
}
},
"components": {
"securitySchemes": {
"apikeyAuth": {
"type": "apiKey",
"in": "header",
"name": "Authorization",
"description": "Supabase API Key"
}
}
}
}
イケそうな空気が出ているので調子に乗って下記のように指示しました。
{
"openapi": "3.0.0",
"info": {
"title": "Supabase API",
"version": "1.0.0"
},
"servers": [
{
"url": "https://***************************.supabase.co"
}
],
"paths": {
"/rest/v1/users": {
"get": {
"summary": "Get specific columns of users",
"description": "Retrieves specific columns for users.",
"operationId": "getSpecificUserColumns",
"parameters": [
{
"name": "select",
"in": "query",
"description": "Columns to select",
"required": true,
"schema": {
"type": "string",
"example": "some_column,other_column"
}
}
],
"responses": {
"200": {
"description": "Successful response",
"content": {
"application/json": {
"schema": {
"type": "array",
"items": {
"$ref": "#/components/schemas/User"
}
}
}
}
}
},
"security": [
{
"apikeyAuth": []
}
]
},
"post": {
"summary": "Add a new user",
"description": "Creates a new user in the users table.",
"operationId": "addUser",
"requestBody": {
"description": "User to add",
"required": true,
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/User"
}
}
}
},
"responses": {
"200": {
"description": "User created"
}
},
"security": [
{
"apikeyAuth": []
}
]
}
}
},
"components": {
"schemas": {
"User": {
"type": "object",
"properties": {
"some_column": {
"type": "string"
},
"other_column": {
"type": "string"
}
},
"required": [
"some_column",
"other_column"
]
}
},
"securitySchemes": {
"apikeyAuth": {
"type": "apiKey",
"in": "header",
"name": "Authorization",
"description": "Supabase API Key"
}
}
}
}
うんざりするほど優秀ですね…。ChatGPTを使うときのコツは勝手に限界を決めつけないで「きっとできる」と可能性を信じてあげることかなと思いました。
この要領でやりたいことを追加していくと理想のSchemaが手に入りますし、段々Schemaの意味もわかるようになってきて、自分で手動で編集したりできるようになります。時間はかかりますが楽しい作業です。
3. どんな感じになったか
最終的には本のデータをGoogle Books APIで取得してSupabaseのBooksテーブルに追加するようにしました。その時に発行されるBook Idを使って毎日の読書記録をRecordsテーブルに記録していきます。
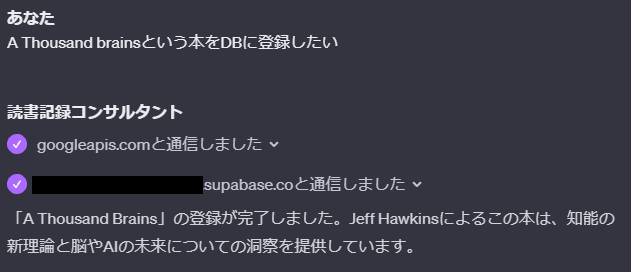

去年読了した本を教えてくれとお願いすると、

さらに、Code Interpreterを入れているので数字にも強く、


というわけで100万語を達成していることが確認できたのでやる気が出ました。今後も洋書多読を続けていこうと思います。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?