
株価をpython【#4.7】

前々回はいろいろスキップして6章をやっていましたが、掘り下げたくなったので、掘り下げていきます。前回は売られすぎ、買われすぎのときに買ったり売ったりしたらどうなるかを検証しました。結局負けるシミュレーション結果が出ました。
6章 株価のトレンド分析
6.1 相場の強弱
6.2 複数の指標を可視化
6.3 チャートを保存する
前提(毎回書く)
教科書:pythonでできる株価データ分析
URL:https://www.morikita.co.jp/books/mid/085711
※アフェリエイトはしていません。本を売る気はありませんが、この本はいい本だと思います。あと、批判的なコメントに思える記述があるかもしれませんが、この本に一切の批判はありません。そういう記述を見かけたら、私の視野の狭さとレベルの低さ故の文章と思ってください。
前回たどり着かなかった、「2.Volumeを使って、売られすぎ、買われすぎを判断してみてはどうだろうか(偏差値38の頭で考えた)。
Close(取引終了時の値) - Open(取引開始時の値) の差が大きいときにいっぱい取引していたら、みんなで乱高下?していた。
Close-Openの差が小さいのにVolumeが大きいと、みんなでちまちました取引が多かったのかな?ってか、そもそもどれくらい毎日Close-Openの差が出ていて、Volumeはどれくらいが普通か見てみるのはどうだろうか。」を試していきます。
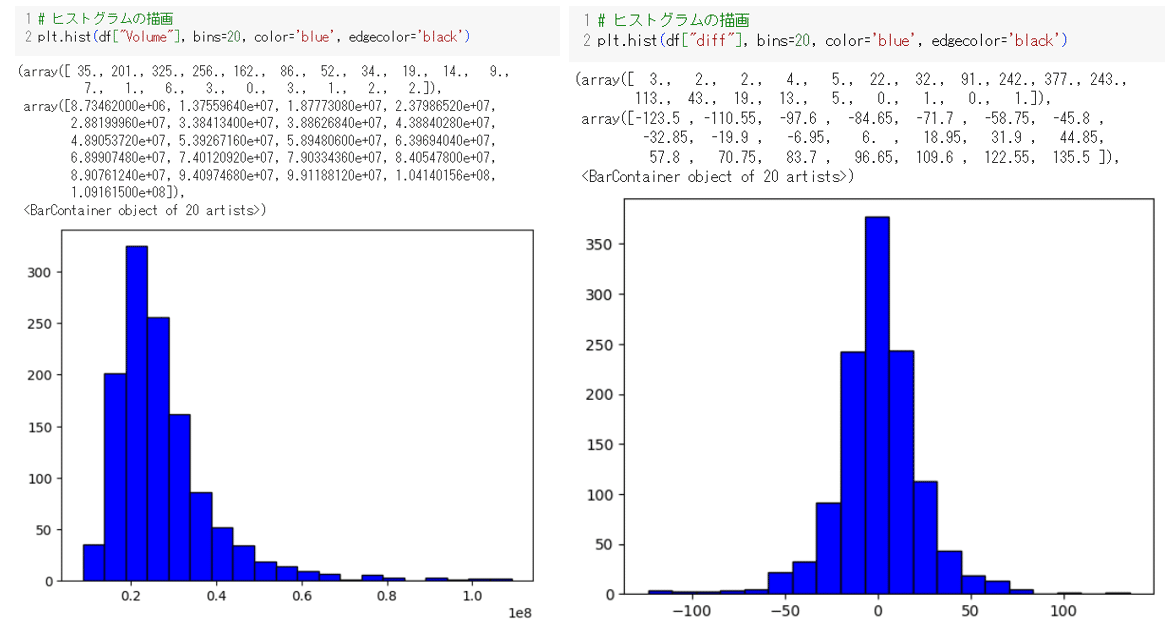
手始めに、データの分布を見てみました。
左がVolume出来高の日ごとのヒストグラム、右がClose-Open差です。これが大きいと始まったときより、その日は高い金額で終わったということです。0のあたりにピークがあってけっこうきれいそうな(正規分布に近そうな)ヒストグラムです。
説明とか試行錯誤を数ステップスキップしますが、次は、このVolumeとClose-Open差の散布図を書いてみました。(色も付けちゃいました)

順に説明していきます。Close-Open差が小さいはたぶんあんまり取引をしていないだろうと考えました(通常通りの取引)。それに比べて、Close-Open差が大きいときは変動が大きいので取引が多いだろうと思いました。ただ、どれくらい多くてどんな分布をするかわからなかったので、VolumeとClose-Open差を散布図で関係を見ました。
すると、何やら1か所に集中して、遠くに行くとまばらに分布していることがわかりました。まばらな部分は取引額が大きいところです。ここが「買いすぎ」「売りすぎ」にあたる部分と考えました。そこを赤色に塗ることにして、そこを見てdiffが正の場合「買いすぎ」、負の場合「売りすぎ」として取引をシミュレーションすることにしました。
もう1つ説明できていないのが、赤色をどうやってつけたか?です。
はじめはOne Class Support Vector Machineを使ったのですが、思った結果が出なかったので、mt法を使うことにしました。
One Class SVMの説明は難しいので割愛します。慣れ親しんでいたので、使ってみただけです。
mt法の説明は↓です。単純化して言うと2次元の標準偏差です(2次元に限らずn次元の標準偏差です)。標準偏差をσで表現しますので、1σ、2σ、3σ、、、と増えていくものです。これはσという単位で計測するので、測るものごとにσの長さは変わります。このσの単位をマハラノビス距離とも言います。なので、1マハラノビス距離、2マハラノビス距離、、、と増えていきます。今回は5以上を外れ値として赤にしました。
https://jp.mathworks.com/help/stats/mahal.html

私は以前matlabを使っていたのでpythonでOne Class SVMやmt法のコードは書けませんので、もちろんChatGPTに教えてもらいながら書きました。(今回は多すぎて、もとに戻ってまとめることができなかったので割愛)
diffが正の場合「買いすぎ」、負の場合「売りすぎ」として取引をシミュレーションした結果が↓です。4勝1敗で累積でも勝っています。

Volumeを使うと精度よく勝てる可能性が出てきました。??ホントかなぁ?これは今の時点ではほぼ嘘です。だって、n=1、サンプル数が1つしかないので。取引高の絶対値や、分布は株によって違うので、分布のグルーピングをして、似たもののなかで、取引額の絶対値、桁をそろえるために正規化(最近は標準化といいますよね、、、私は先生に正規化で習いました。)して、そのあと、普遍的でなくてもいいけど、なんか5みたいな閾値も理屈をつけて設定しないといけないですし。。。
そこで似た分布のサンプルを100個用意することにしませんでした。私の株への探求はここまでです。株で本気で稼ぎたくなったら、この続きをやろうと思います。まぁ門外漢の素人が思いついたことなので、サンプルを増やすと、ホントは「正しくない。そんなものを使っても勝てない」という結論になる可能性が高いです。
でもまぁ、探求心ができて、それを満たすことができたので万々歳です。楽しかったー。まだ続きますので、またお会いしましょう。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?