
【ChatGPT】Blender自動化するPythonのコード作成にチャレンジ

はじめに申し上げておくとこれは誰かの役に立つようなコードではなく、あくまでChatGPTを活用してはじめてPythonにチャレンジした話なので、勉強法のひとつとしてご参考までに。
きっかけ
LoRAの教師データをどう準備するかという課題があったのですが、自分はVRMのモデルでポーズをとってスクショ、またはソフトからPNGやJPGを書き出しという手順を繰り返しやっていたのですが、ここをなんとか効率化できないかなと、いろいろ探っていたことがきっかけ。
さまざまな便利なソフトを活用してましたが、blenderでもできないかと、いつも参考にさせてもらっているyonaoshiさんのこの動画を見て、んーこれはblenderで自動化できないかなと思い、Pythonを一度も勉強したことないのですが、結果として2つほど試したことになりました。
(1)jsonを読み込んでVRMのモデルにポーズを反映させる
(2)VRMモデルをランダムなカメラ位置から自動で撮影をする
試したことになりましたというのは、何もわからないのでいろいろ聞きながら進めていたところ、大きく2つのコード作成をしているんだなと途中で気づきました。実現したいこととはいえ、初心者にはハードルが高そうですがモチベーションは維持できたと思います。
現在のやり方
VRMデータでポーズを取って画像で書き出す方法はいくつかありますが、Vroid studio、VRM Porsing Desktop(Steam)、VRMお人形遊びPC版、VRMお手軽ポーズ、などが扱いやすいかなと思っています。自分でポーズも変更できますし、用意されたポーズにしてカメラ位置、画角などをきめたり、背景なども読み込みできるのでかなり自由度が高く、あるいみVRMモデルのための撮影スタジオのように使えてとても便利です。

もちろんこれらでも十分に効率的で便利なものなのですが、自分のようにいくつもモデルを試したい、パターンを用意したいとなると、結構手間がかかってしまいます。もっと効率化できないかなと思い、BlenderのPythonコンソールで自動化できたらいいなと思いChatGPTに投げてみたところ、なんとかなりそうかも?と思いチャレンジしてみました。
自動化してやりたいこと
VRM(3Dモデル)ファイルとjson(ポーズ)ファイルを用意して、何枚の画像がほしいか設定したら、あっというまに、ランダムなポーズで撮影されたキャラクター画像ができあがる、というものを想定していました。
(1)VRMファイルを指定したフォルダから読み込む
(2)jsonファイルを指定したフォルダからランダムに読み込む
(3)jsonファイルの値をVRMモデルのポーズに反映させる
(4)カメラをランダムな位置に配置する
(5)カメラをVRMモデルに向ける
(6)VRMモデルを撮影する
(7)指定した画像サイズで指定したフォルダに保存する
(8)2〜7を指定した数だけ繰り返す
上記の(1)〜(8)というのは、はじめから計画していたことではなく、ChatGPTとやりとりを進める中でわかってきたフローをざっくりまとめたものです。
当たり前のことなのですが、実際のアプリケーションでどのような手順で操作するか、これをコード化するわけですから、そもそもこれをしらないとChatGPTのやっていることを理解することができないため、最低限アウトプットに対する知識は持っておいたほうが良いというわけです。
ChatGPTとのやりとり
何もわからなかったのでとりあえずこんな感じかなと思うことを投げてみたところ、すぐにコードのサンプルを出してくれました。すごい。

早速パスなどを指定してblenderのPythonコンソールで実行してみたところエラーが出たのでエラー内容を報告。そうするとその修正したコードがすぐに出てきたので、それをまたblender内のPythonコンソールで実行、エラーの報告、実行、報告、、、、を、おそらく50回は繰り返したんじゃないかと思います、、。そう簡単にはいかないのはわかっていました。

途中で(1)〜(8)のフローを一気にやるのは無理と思い、まずはjsonから読み込んだ値でポーズを変更させるということに専念。次にカメラをランダムに設置して撮影という2つのコードにわけて取り掛かることにしました。
ポーズ用のjsonは、VRM用のソフトから書き出しできるものから拝借したのですが、並びや書き方がさまざまで解読するのに時間もかかってしまうという始末。モデルのボーンの配列とjson内のキーの配列を再度humanoidの規格にあわせた並びに変更したほうがよい(本当?)など紆余曲折し、ときには質問に対して、全く検討違いな回答が繰り返されるということが多くありました。




成果
恥ずかしいですがコードをさらしておきます。以下の(1)と(2)を組み合わせることで、 LoRA用の教師データを一瞬で作成することを考えてましたが、結果惨敗。地道にスクショ撮ったほうが早い!ということはわかったのですが、なにかプログラムの学習方法という意味では、まるでマンツーマンでつきっきりのセンセがいたようで、少しは成果があったかなと、、。
(1)jsonを読み込んでVRMのモデルにポーズを反映させる
import bpy
import json
from mathutils import Quaternion
# VRMモデルを読み込む
bpy.ops.import_scene.vrm(filepath="VRMのパス")
# JSONファイルを読み込む
with open("jsonのパス", "r") as f:
pose_data = json.load(f)
# シーンを更新
scene = bpy.context.scene
# 読み込んだVRMアーマチュアを取得する
vrm_armature = bpy.context.scene.objects['Armature']
# アーマチュアをアクティブにする
bpy.context.view_layer.objects.active = vrm_armature
# アクティブなオブジェクトがアーマチュアであるかどうかを確認する
if bpy.context.active_object.type == 'ARMATURE':
print('Armature is active')
else:
print('Armature is not active')
# ポーズモードに切り替える
bpy.ops.object.mode_set(mode='POSE')
# アーマチュアのポーズを初期化
bpy.ops.pose.select_all(action='SELECT')
bpy.ops.pose.transforms_clear()
# 初期ポーズのQuaternionを取得する
armature_pose_quat_data = {}
for bone in vrm_armature.pose.bones:
armature_pose_quat_data[bone.name] = bone.rotation_quaternion
# オブジェクトモードに切り替える
bpy.ops.object.mode_set(mode='OBJECT')
# アーマチュアのポーズ変更前の情報を表示する
for bone in vrm_armature.pose.bones:
# VRMモデル内のすべてのポーズボーンとその名前を辞書に保存する
pose_bone_table = {}
for bone in vrm_armature.data.bones:
pose_bone_table[bone.name] = vrm_armature.pose.bones[bone.name]
# 辞書の内容を表示する
for name, bone in pose_bone_table.items():
# JSONファイル内のキーとVRMのポーズボーンを自動的に対応付ける
pose_bone_table = {}
for bone in vrm_armature.data.bones:
for pose_bone in vrm_armature.pose.bones:
if pose_bone.bone.name == bone.name:
pose_bone_table[bone.name] = pose_bone
break
for bone_name, bone_data in pose_data.items():
rotation = [float(x) for x in bone_data['rotation']]
pose_data[bone_name]['rotation'] = rotation
pose_data[bone_name]['quaternion'] = Quaternion(rotation)
# ポーズモードに切り替える
bpy.ops.object.mode_set(mode='POSE')
# ボーンのポーズを変更する
for bone_name, pose_quat_data in pose_data.items():
pose_bone = pose_bone_table.get(bone_name)
if pose_bone:
# Quaternionコンストラクタでエラーが起きる場合があるので、例外処理を追加する
try:
pose_quat = Quaternion(pose_quat_data['quaternion'])
except:
print(f"Failed to create Quaternion from {pose_quat_data} for bone {bone_name}")
continue
# 初期ポーズと合成する
armature_pose_quat = armature_pose_quat_data.get(bone_name)
if armature_pose_quat:
pose_quat = armature_pose_quat.inverted() @ pose_quat
# ポーズを変更する
pose_bone.rotation_quaternion = pose_quat
# オブジェクトモードに切り替える
bpy.ops.object.mode_set(mode='OBJECT')
# シーンを更新する
bpy.context.view_layer.update()
なんとかjsonの値をボーンに反映はできたものの、ボーンと値がずれていた関係で、とんでもない形に、、。VRMの基礎知識が足りないこともありこちらは一旦断念。
(2)VRMモデルをランダムなカメラ位置から自動で撮影をする
import bpy
import mathutils
import math
import random
import re
import os
import json
from mathutils import Vector, Quaternion
# VRMをインポート
bpy.ops.import_scene.vrm(filepath="VRMファイルのパス")
# ポーズ用json格納場所
json_path = "jsonのフォルダのパス"
poses = os.listdir(json_path)
# シーンの設定
scene = bpy.context.scene
scene.render.engine = 'BLENDER_EEVEE'
scene.render.image_settings.file_format = 'PNG'
# VRMオブジェクトの取得
vrm_object = bpy.context.view_layer.objects.active
# VRMオブジェクトの境界ボックスを取得
bbox = vrm_object.bound_box
# VRMオブジェクトの境界ボックスの中心を計算
bbox_center = sum((Vector(b) for b in bbox), Vector()) / 8
# VRMオブジェクトのバウンディングボックスの対角線の長さを計算
bbox = vrm_object.bound_box
bbox_center = sum((mathutils.Vector(p) for p in bbox), mathutils.Vector()) / 8
bbox_diag = (max(bbox, key=lambda p: p[0])[0] - min(bbox, key=lambda p: p[0])[0])**2 \
+ (max(bbox, key=lambda p: p[1])[1] - min(bbox, key=lambda p: p[1])[1])**2 \
+ (max(bbox, key=lambda p: p[2])[2] - min(bbox, key=lambda p: p[2])[2])**2
bbox_diag = bbox_diag**0.5
# カメラの設定
camera = bpy.data.objects['Camera']
# VRMオブジェクトを選択
vrm_object.select_set(True)
# アーマチュアをアクティブにする
for obj in bpy.context.scene.objects:
if obj.type == 'ARMATURE' and obj.name == 'Armature':
bpy.context.view_layer.objects.active = obj
break
# アクティブなアーマチュアを取得する
obj = bpy.context.view_layer.objects.active
if obj and obj.type == 'ARMATURE':
armature = obj.data
bpy.context.view_layer.objects.active = obj
bpy.ops.object.mode_set(mode='POSE') # ポーズモードに切り替える
if bpy.context.object.mode == 'POSE':
print("ポーズモードに切り替わりました。")
else:
print("ポーズモードに切り替わりませんでした。")
print("アーマチュアオブジェクト:", armature)
else:
print("No armature object found.")
armature = None
# 対象となる首のボーンオブジェクトを取得する
neck_bone_name = "J_Bip_C_Neck"
neck_bone_obj = None
if armature:
neck_bone_obj = armature.bones.get(neck_bone_name)
# 対象ボーンが選択されている場合はそのボーンを対象にする
target_bone = None
if armature:
for pbone in obj.pose.bones:
if pbone.bone.name == neck_bone_name:
target_bone = pbone
break
if target_bone:
print("選択されたボーン:", target_bone.name)
else:
print("No bone selected.")
# 対象となる首の位置を取得する
obj = bpy.context.object
neck_bone_name = "J_Bip_C_Neck"
neck_bone_obj = obj.pose.bones.get(neck_bone_name)
if neck_bone_obj:
neck_position_local = neck_bone_obj.head
neck_position_global = obj.matrix_world @ neck_bone_obj.matrix @ neck_position_local
bpy.context.scene.cursor.location = neck_position_global
print("ローカル座標系での首の位置:", neck_position_local)
print("グローバル座標系での首の位置:", neck_position_global)
else:
print("Could not find neck bone: {}".format(neck_bone_name))
# 首のボーンが見つかった場合、3Dカーソルを移動させる
if neck_bone_obj:
cursor_location = neck_bone_obj.head
bpy.context.scene.cursor.location = cursor_location
# 新しいカメラの名前とデータを設定
new_camera_obj_name = "NewCamera"
new_camera_data = bpy.data.cameras.new(new_camera_obj_name)
# アクティブなオブジェクトを取得
new_camera_obj = bpy.data.objects.new(new_camera_obj_name, new_camera_data)
old_camera_obj = None # 旧カメラを削除する
for obj in bpy.data.objects:
if obj.type == 'CAMERA' and obj != new_camera_obj:
bpy.data.objects.remove(obj, do_unlink=True)
# 撮影くりかえし
for i in range(10):
# ポーズのjsonファイルをランダムに選択
pose_file = os.path.join(json_path, random.choice(poses))
print("Selected pose file: {}".format(pose_file))
# 撮影処理
camera_numbers = set()
for obj in bpy.data.objects:
if obj.type == 'CAMERA':
match = re.match(r'Camera(\d+)', obj.name)
if match:
camera_numbers.add(int(match.group(1)))
print(camera_numbers)
new_camera_number = 1
while new_camera_number in camera_numbers:
new_camera_number += 1
# カメラを作成
new_camera_data = bpy.data.cameras.new('Camera')
new_camera_obj_name = "Camera{:02d}".format(new_camera_number)
new_camera_obj = bpy.data.objects.new(new_camera_obj_name, new_camera_data)
#old_camera_obj = None # 旧カメラを削除する
#for obj in bpy.data.objects:
# if obj.type == 'CAMERA' and obj != new_camera_obj:
# bpy.data.objects.remove(obj, do_unlink=True)
camera_numbers.add(new_camera_number)
x = round(random.uniform(-2.0, 2.0), 1)
z = round(random.uniform(1.0, 3.0), 1)
y = -2
chosen_point = (x, y, z)
print(chosen_point)
# 新しいカメラの位置を指定
new_camera_location = mathutils.Vector(chosen_point)
new_camera_obj.location = new_camera_location
# シーンにカメラを追加する
bpy.context.scene.collection.objects.link(new_camera_obj)
# カメラの表示設定
bpy.context.view_layer.objects.active = new_camera_obj
bpy.ops.object.visual_transform_apply()
new_camera_obj.data.display_size = 2.0
new_camera_obj.show_name = True
print("Camera created: {}".format(new_camera_obj.name))
# カメラをアクティブにする
bpy.context.view_layer.objects.active = new_camera_obj
print("Active:", new_camera_obj)
bpy.ops.object.transform_apply(location=True, rotation=True, scale=True)
# カメラを3Dカーソルの位置に向ける
cursor_location = bpy.context.scene.cursor.location
camera_location = new_camera_obj.location
camera_direction = (cursor_location - camera_location).normalized()
up_vector = Vector((0, 1, 0))
camera_rotation = camera_direction.to_track_quat('-Z', 'Y')
up_quat = camera_rotation @ up_vector.to_track_quat('-Z', 'Y').inverted()
new_camera_obj.rotation_mode = 'QUATERNION'
new_camera_obj.rotation_quaternion = (cursor_location - new_camera_obj.location).to_track_quat('-Z', 'Y')
print("Cursor Location:", cursor_location)
print("Camera Location:", camera_location)
print("Camera Direction:", camera_direction)
print("Camera Rotation:", camera_rotation)
print("Up Quaternion:", up_quat)
# カメラの距離と解像度
camera_distance = 1 * bbox_diag
render = bpy.context.scene.render
# カメラの画角の計算
aspect_ratio = render.resolution_x / render.resolution_y
new_camera_data.angle = 0.5 * math.atan((bbox_diag / 1) / (camera_distance * aspect_ratio))
# レンダリングの設定
render = bpy.context.scene.render
# 画像の解像度を自動調整
resolution_scale = max(vrm_object.dimensions) * 2.0
render.resolution_x = int(1024 * resolution_scale)
render.resolution_y = int(1024 * resolution_scale)
# レンダリング時のポストプロセスを有効にする
render.use_compositing = True
# カメラが存在するか確認
camera = bpy.data.objects.get(new_camera_obj_name)
if camera is None:
print("カメラが存在しません")
# レンダリング
else:
# カメラをアクティブに設定する
bpy.context.scene.camera = camera
num_frames = 1
if bpy.context.scene.camera is None:
bpy.context.scene.camera = camera
for frame in range(num_frames):
bpy.context.scene.frame_set(frame)
render = bpy.context.scene.render
render.filepath = "/Volumes/A002/blender/Output/frame_{}_{}.png".format(i, frame)
bpy.ops.render.render(write_still=True, use_viewport=True, scene=bpy.context.scene.name)
print("Rendered frame_{}_{}.png".format(i, frame))
# VRMを削除
bpy.ops.object.select_all(action='SELECT')
bpy.ops.object.delete(use_global=False)
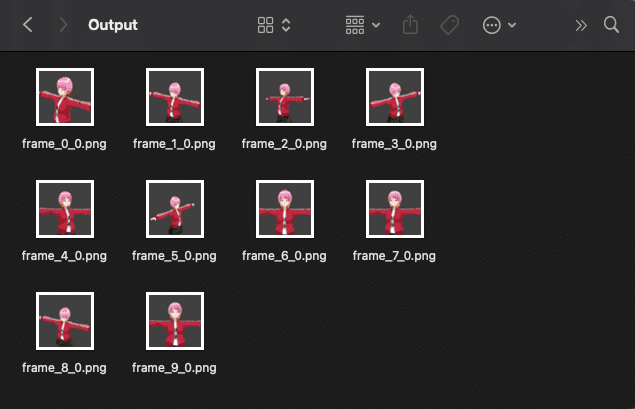
コードにはデバッグ用にprint文があちこちについてますが、それがわりと勉強になりました。カメラから被写体までの構図の変化のつけ方として、あとはレンズをランダムで設定するということもできそうです。
もしどなたかこれが実現できそうでしたら、、。
コミュニケーション能力とアウトプットに対する知識が問われる
ChatGPTを活用してプログラムを作成というよりは、ChatGPTと一緒に考えながら作る感覚、マンツーマンのセンセにも近かったように思います。はじめてPythonに触れた感じとしては、途中で興味が薄れることもなく勉強できたのかなと、、。
AIだから何かすごいものすぐにポンっと出してくれるということではなく、何を作りたいのか、何を回答として得たいのか、こちらからどんな情報を与えられるのか、的確な質問、指示を伝えられるか、そのあたりが問われるように思います。逆にいえば、それらが明確な人にしてみたら、ものすごい手段、パートナーを手にいれたような感じだと思います。
また、もし普通に学習しようとしてたら、何かのオンライン講座を受講して基本を、、みたいな感じで進めてたかもしれませんが、なにかとてつもなくすごい学習法のようにも感じます。
今回の失敗の原因としては自分のVRMモデルの構造に対する知識の無さが原因でした。いずれにしてもアウトプットに対する技術・知識・経験があるかないかで、ChatGPTへの情報の伝え方が変わってくると思いますので、アウトプットに関連する貪欲な興味・関心もかなり大事かなと思います。
今後は自由な発想やアイデアとともに、AIをうまく活用できる人が生き残るんだと思います。