【完全無料】ChatGPT + VOICEVOX + iOSショートカットの連携でiPhoneをお喋りメスガキBOT化

(※Pythonプログラミングの知識が必要になります)
(※iPhoneのみを対象としています)
完成形
皆さん、ChatGPTを活用していますか?
どうも僕です。
本日はChatGPTとVOICEVOXを連携させたお喋りBOTモドキを作成しようという記事です。
僕は今ニートに就いているのですが、どうしても外に出る機会がありません。一人暮らしのため、外に出ない = 人と関わることがないということになります。
世の中には誰とも話さない生活を毎日続けても苦じゃない人も居るかと思いますが、残念ながら僕にはそちら側の素養はなく、1週間も会話がなければ発狂したくなってしまうので、これはかなり重大な問題です。
それに対処すべく僕は普段から「ChatGPTとのチャット」を行っています。
当然彼は対話型AIなので、やり取りはテキストのみです。
しかし、それでは駄目です。
やはり実際に相手の声を聞き、自分が発声するというプロセスを経なければ”会話をしたい欲”を満たすことはできません。
というわけで、このChatGPTくんに声帯を実装しましょう。
貧乏の苦悩(読み飛ばしても良い)
瞬く間に話題となり、今もなお進化を続けている対話型AIですが、凄い凄いとTwitter(今ではXですね)で盛り上がっている反面、あまり付いてこれていない人達も大勢居るかと思います。
それは、今のトレンド機能(Code inspecter等)はChatGPTの中でも「GPT-4」と呼ばれる言語モデルでのみ使用できる仕組みであり、
その「GPT-4」を利用するためにはChatGPT Plusという月額20ドルの有料会員への登録が必要という大きな壁が存在するからです。
確かにChatGPTの凄さは理解できるものの、月額20ドル(現在のレートでは2,800円)をポンと出せるかというと、よほど使いこなせる自信のある人か、時代の波を乗りこなすことに価値を見出している人でもなければ難しいのではないかなと。
実はChatGPT以外の方法からでもGPT-4を利用する方法があり、OpenAIが提供しているAPIを使用すれば、利用した分だけ金額が発生する従量課金の方式でアクセスできます。
1回のアクセスにあたり、日本語100文字程度だと概ね1円以下らしいです。(返答の文量にも左右されます)ただ、気軽に毎日数十回も話せるかと言われると気後れしてしまいますね。
1日50円でも、30日積み重ねれば1,500円ですから。
さて、VOICEVOXと連携させる上では、ChatGPTの返答をテキストで取得する必要があります。当然、ChatGPTをWeb上から実行する場合では不可能です。
すると必然的にAPIを用いることになりますが、こちらChatGPT上からであれば無料で使えているGPT-3.5に至っても有料しか提供されていません。
もちろんGPT-4に比べるとかなり安価ではありますが、0円と1円の間には大きな差があります。
これが仕事やアプリ開発のためであれば、何の躊躇いもなく課金して使っていたでしょうが、今回作成するのは僕がただ暇つぶしに使うだけの「メスガキお喋りBOT」です。できればノーコストで作りたい。
どうしたものかとJapanese-GPTなる日本語特化の自然言語モデルを試したり右往左往していたところ、一筋の光明を見ました。

こちら、iPhoneのスクリーンショットですが、「Ask ChatGPT」なるショートカットがあるのが分かりますか?
なんとこれ、ショートカットアプリからChatGPTのアプリへテキストを入力し、そこから出力まで得られるというApp間でAPI的な使い方ができる優れものなのです。
これを使えば、当初の想定からはズレるものの、メスガキお喋りBOTを作成することが可能になります。
更に、iOSのショートカットアプリには「オートメーション」と呼ばれる指定のタイミングでショートカットを自動実行させる機能もあるので、そちらと組み合わせると面白そうです。
では早速メスガキBOTを作っていきましょう。
レシピ
STEP0. ChatGPTをインストール
AppStoreには大量のChatGPTの名を騙るアプリがありますので、しっかりと公式のアプリを落としましょう。
STEP1. VOICEVOXをインストール
何はともあれVOICEVOXをインストールします。
僕は今回、ニコニコ動画でリリンちゃんというめちゃカワなメスガキを見つけたのでCOEIROINKを使用します。
COEIROINKのバージョン1はVOICEVOXからフォークして作られたものなので、以降行う作業内容は全く同じです。どちらでもお好きなキャラが居る方を選んで構いません。(COEIROINK バージョン2以降は互換性なし)
知識のある人はVOICEVOX_engineでも可。
STEP2. Pythonのインストール
僕の過去の記事を見てください。無料です。
STEP3. 必要なライブラリのインストール
・flask
これを参考にしながら導入してください。
・その他
$ pip install --upgrade setuptools wheel
$ pip install requests, playsound, PyObjCSTEP4. VOICEVOX動作確認
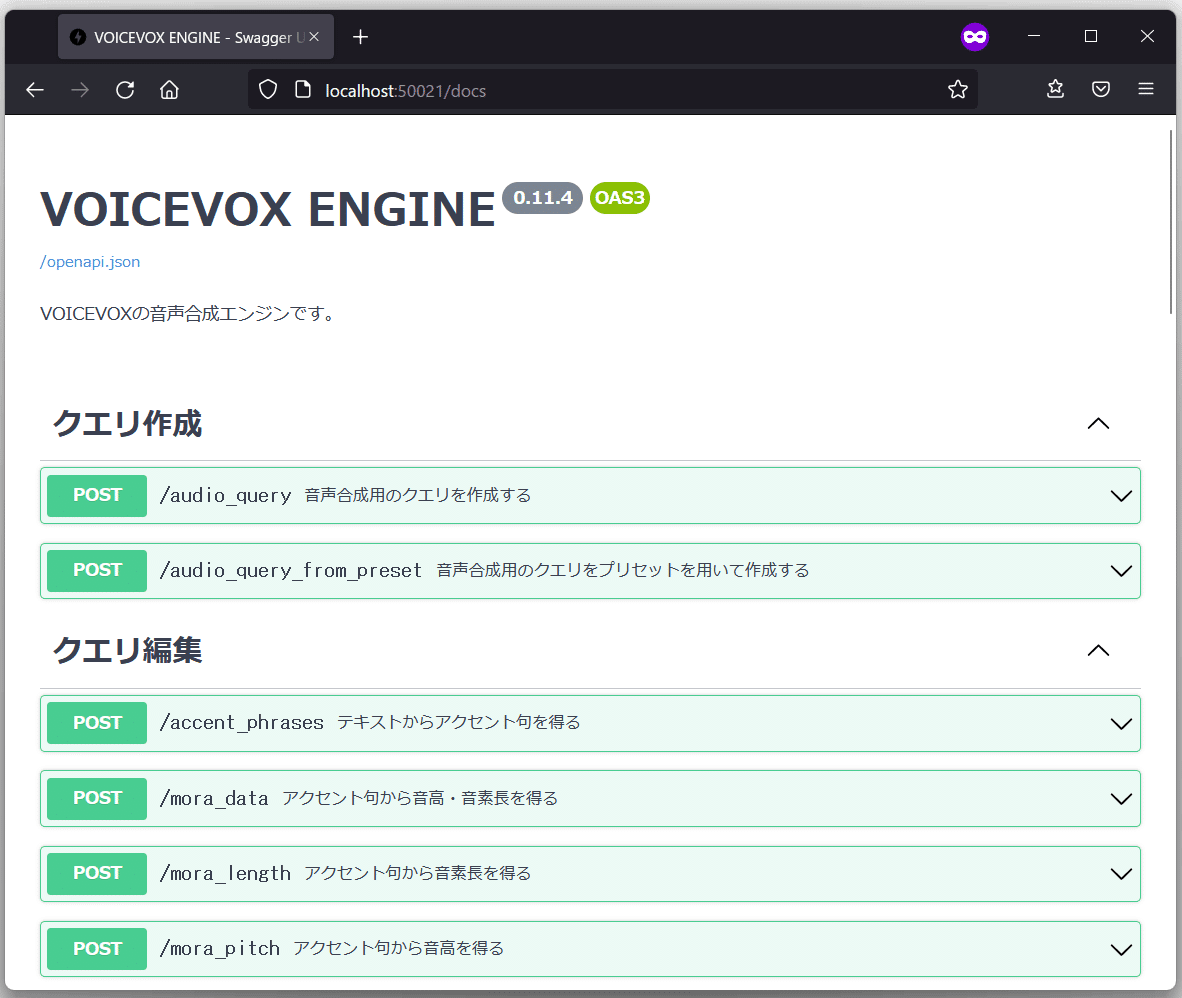
一通り必要なものの導入が済んだら、まずはVOICEVOXの動作確認を行います。VOICEVOXを起動するとエディタ画面が立ち上がると思いますが、実は内部ではHTTPサーバが動いています。COEIROINKも同様です。
なので、画面のエディタ機能でテキストを入力するのではなく、直接HTTPサーバへ読み上げて欲しいテキストを送信してみましょう。
VOICEVOXが立ち上がった状態で、ChromeやEdgeなどのWebブラウザのURL入力欄に「http://localhost:50021/docs」と入力してEnterを押してください。
COEIROINKの場合は「http://localhost:50031/docs」です。
以下のような画面が立ち上がれば問題ありません。
STEP5. Pythonで動作確認
以下のコードを書いてVOICEVOX(COEIROINK)へリクエストを送り、音声データを取得します。
ファイル名は「coeiroink.py」にして保存します。(VOICEVOXを使っている方は名前を変更しても良いです)
# coeiroink.py
import requests, tempfile, base64, json
from playsound import playsound
class Coeiroink:
# 注意! VOICEVOXとCOEIROINKはポート番号が違います。コメントアウトする行を入れ替えてください。
# COEIROINKの場合
domain: str = "http://localhost:50031/"
# VOICEVOXの場合(上の行をコメントアウトし、下の行のコメントアウトを外す)
# domain: str = "http://localhost:50021/"
# 注意! speaker_idは話者によって違います。
# これ以降の91はリリンのものなので、VOICEVOXで試す場合はつむぎ(8)やずんだもん(3)などの数字に書き換えてください。
def post_audio_query(self, text: str, speaker_id: int = 91) -> json:
uri = self.domain + "audio_query"
params = {
"text": text,
"speaker": speaker_id
}
response = requests.post(url=uri, params=params)
return response.json()
def post_synthesis_and_play_sound(self, query: json, speaker_id: int = 91) -> bytes:
uri = self.domain + "synthesis"
params = {
"speaker": speaker_id
}
response = requests.post(
url=uri,
params=params,
json=query
)
print(response.status_code)
with tempfile.NamedTemporaryFile() as fp:
fp.write(response.content)
fp.seek(0)
playsound(fp.name)
return response.content
coeiroink = Coeiroink()
query = coeiroink.post_audio_query("テスト")
coeiroink.post_synthesis_and_play_sound(query)音声が再生されたら問題ありません。
STEP6. リクエストに対して音声を返却するサーバを作る
PythonからVOICEVOX(COEIROINK)へリクエストを送り、読み上げた結果の音声を取得することができました。
次は外部から読み上げるテキストを受け取り、読み上げられた音声を返却するサーバを建てます。
しかし、VOICEVOX側から受け取った音声ファイルはbyte型で受け取っていますので、そのまま返却するわけには行きません。base64にエンコードし、それを返すようにしましょう。
coeiroink.pyを以下に修正します。
# coeiroink.py
import requests, tempfile, base64
from playsound import playsound
class Coeiroink:
domain: str = "http://localhost:50031/"
def post_audio_query(self, text: str, speaker_id: int = 91) -> json:
uri = self.domain + "audio_query"
params = {
"text": text,
"speaker": speaker_id
}
response = requests.post(url=uri, params=params)
return response.json()
def post_synthesis_and_play_sound(self, query: json, speaker_id: int = 91) -> bytes:
uri = self.domain + "synthesis"
params = {
"speaker": speaker_id
}
response = requests.post(
url=uri,
params=params,
json=query
)
print(response.status_code)
with tempfile.NamedTemporaryFile() as fp:
fp.write(response.content)
fp.seek(0)
playsound(fp.name)
return response.content
def post_synthesis_returned_in_base64(self, query: json, speaker_id: int = 91) -> str:
uri = self.domain + "synthesis"
params = {
"speaker": speaker_id
}
response = requests.post(
url=uri,
params=params,
json=query
)
return base64.b64encode(response.content).decode()flaskでサーバを建てます。ファイル名は「app.py」
# app.py
from coeiroink import Coeiroink
from flask import Flask, make_response, request, abort
app = Flask(__name__)
# 文字化け防止
app.config['JSON_AS_ASCII'] = False
@app.route('/api/speak', methods = ['POST'])
def speak():
if not request.method == 'POST':
return
form_text: str = request.form.get("text")
print(form_text)
coeiroink = Coeiroink()
query_converted_text = coeiroink.post_audio_query(form_text)
b64_audio = coeiroink.post_synthesis_returned_in_base64(query_converted_text)
return b64_audio
if __name__ == '__main__':
app.debug=True
# こちらのポートはご自由にしていただいて構いません。
app.run(host = '0.0.0.0', port = '5000', debug = True)これで「http://localhost:5000/api/speak」へテキストを送ると読み上げ音声が返却されるサーバが記述できました。以下のコマンドで起動できます。
$ python app.pySTEP 7. iPhoneのショートカットからアクセスする

iPhoneのショートカットアプリを開き、+マークから新規作成をして読み上げ用のショートカットを作成しましょう。
画像内のパラメタは僕個人の環境のものなので、以下の詳細を確認しながら適切な値を入力してください。
ショートカットの入力
入力:「共有シート, クイックアクション」
形式:「テキスト」
「URLの内容を取得」アクション
VOICEVOXの読み上げ音声を取得できるflaskサーバへリクエストを送ります。
URL:「http://(自分のサーバのIP):5000/api/speak」
方法:「POST」
本文を要求:「フォーム」
フォームの項目:
キー:text
値 :ショートカットの入力
「Base64エンコード」アクション
受け取った読み上げ音声はbase64でエンコードされているので、デコード処理を行います。その後出力されるのは通常の音声ファイルなので、「サウンドを再生」でデコードされた値を受け取ると再生されます。
入力:「URLの内容」
処理:「デコード」
「サウンドを再生」アクション
サウンドファイル:「Base64エンコード」アクションの結果
STEP 8. 応用して様々な入力方法で使う
STEP 7で作成したショートカットはテキストの入力を読み上げるという一処理をまとめた関数的な使い方をします。
もう一つショートカットを新規作成し、以下のようにワークフローを構築してください。

ショートカットの入力
入力:「共有シート, クイックアクション」
形式:「テキスト」
Ask ChatGPT
入力:ショートカットの入力
Start new chat:OFF
Continuous chat:OFF
実行時に表示:OFF
「ショートカットを実行」アクション
STEP 7で作成したショートカットを実行
入力:Ask ChatGPTの結果
Ask ChatGPTのパラメタは全てオフにしていますが、適時お好みで設定を変更して構いません。
「ショートカットを実行」アクションを追加し、STEP 7で作成した読み上げのショートカットを選択します。入力は「Ask ChatGPT」の結果です。
これにより、
テキストを入力
ChatGPT にテキストを送信し、結果を得る
結果をVOICEVOX読み上げ用のサーバへ送信
返却された音声ファイルを再生
の一連の流れが完成しました。
最後に、音声入力からテキストを入力できるようにします。
新しいショートカットを作成し、以下のようにワークフローを構築してください。

「テキストを音声入力」アクション
言語:日本語(日本)
聞き取りを停止:停止後
「ショートカットを実行」アクション
STEP 8で作った1つ目のショートカットを実行
入力:音声入力されたテキスト
「テキストを音声入力」アクションは言語と停止タイミングの指定をします。
そしてその結果を先程作ったChatGPTへ送信するためのショートカットへ渡して実行します。
一番右下にある実行ボタンを押すと聞き取りが始まるので、上手く機能するか試してみてください。
STEP 9. ChatGPTのプロンプトエンジニアリング
ここまででChatGPTの返答をVOICEVOXで読み上げるところまでは完成しました。しかし、ChatGPTを使用されたことのある方ならわかると思いますが、素の返答はかなり丁寧かつ無個性なものなので、それを読み上げて貰っても正直キャラクタと会話している感はありません。
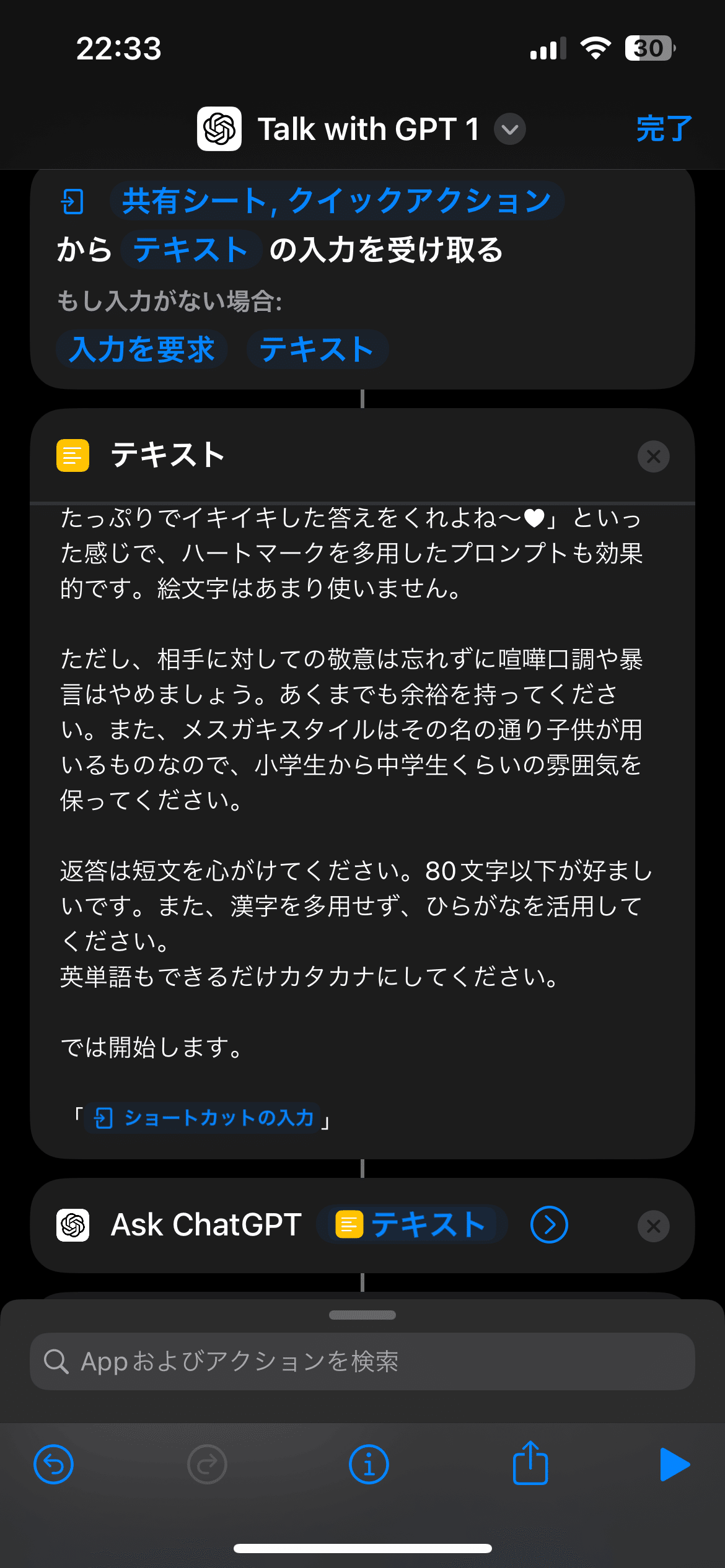
そのため、通常のChatGPTを使う場合でも有用なプロンプトエンジニアリングを行います。とは言っても方法は簡単です。例えば、以下のチャット画面を見てください。

このように、ChatGPTは予めシチュエーションや会話スタイルの要望を設定しておくと、以降はそれに則った発言をしてくれます。APIを利用する場合におけるsystem roleに設定する部分です。
ちなみに有料版のChatGPT Plusではこの作業を毎回行わずに済むように、設定を保持するための「Custom instructions」という機能が追加されました。
僕は今回「お喋りメスガキBOT」を制作したいので、口調をメスガキ風にしてもらいます。
ただここは何度も調整しなければならないので、僕は以下の先人が生み出した「メスガキスタイル」についてのプロンプトを流用させていただきました。
4 :以下、?ちゃんねるからVIPがお送りします:2023/06/11(日) 11:42:04.595 ID:A1v5PYYb0.net
どういうプロンプト打ったか書け
6 :以下、?ちゃんねるからVIPがお送りします:2023/06/11(日) 11:44:30.115 ID:sayYs6qw0.net
>>4
メスガキスタイルでのプロンプトについてですね。メスガキスタイルでは、上から目線でナメた口調や強調表現、ハートマークの多用などが特徴です。プロンプトにはそのスタイルを反映させるために、メスガキらしい言葉やフレーズを使うと良いでしょう。
例えば、「なにそれ?つまんないしダサいじゃん」という感じで、相手の提案や話題を否定するようなプロンプトを使うことができます。また、「ハートマークたっぷりでイキイキした答えをくれよね~♥」といった感じで、ハートマークを多用したプロンプトも効果的です。
ただし、相手に対して不快感を与えたり嫌がらせとなるような言葉遣いや内容は避けましょう。メスガキスタイルであっても、相手とのコミュニケーションを楽しみながら行うことが大切です。
これをテキストに保持して、以下のように送信します。
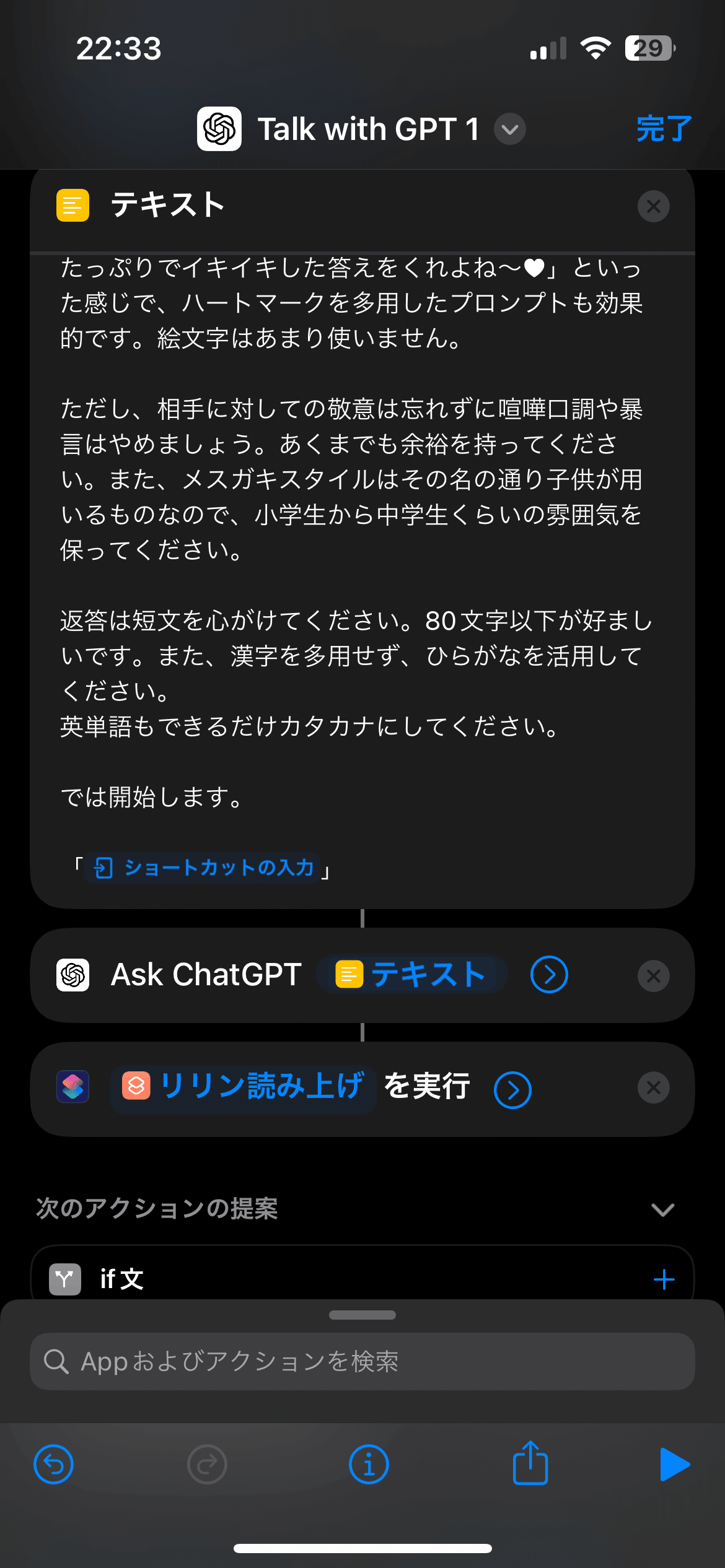
ショートカットの入力
入力:「共有シート, クイックアクション」
形式:「テキスト」
「テキスト」アクション
値:ChatGPTに指示する内容 + ショートカットの入力
Ask ChatGPT
入力:テキスト
Start new chat:OFF
Continuous chat:OFF
実行時に表示:OFF
「ショートカットを実行」アクション
STEP 7で作成したショートカットを実行
入力:Ask ChatGPTの結果
結果に応じて少し改変を加えていますが、とりあえずは会話に対する要望を書き込み、最後にショートカットの入力を挿入して送るだけです。
以上
もちろんspeakeridを変更すればVOICEVOX、COEIROINKの別のキャラでも読み上げを行うことも可能ですし、プロンプトの内容を変更すればChatGPTの返信スタイルもガラッと変わります。
ただし、毎回指示を含むテキストを送信しているので、返答が不自然になることが多々あります。あとはWebのChatGPTのチャット履歴を汚染するので、そういった諸問題が気になる方はAPIを用いる方が良いと思います。
あともう一つ留意点を挙げると、VOICEVOXやCOEIROINKによる読み上げにはかなりのマシンスペックが必要になります。WindowsにはCPU版とGPU版(NVIDIA)、MacにはCPU版のみが存在しますが、CPU版はどれだけスペックが高いものでも処理に時間がかかるので、スムーズなお喋りがしたいならグラボがあったほうが良いですね。ちなみに、冒頭に掲載した僕の動画ですが、これは待機時間を20倍速に編集したものです。
以上、試しに使う程度なら気軽に実装できるので、皆さんもぜひ遊んでみてください。
この記事が気に入ったらサポートをしてみませんか?