
深層学習で洋服の写真を並び替え(分類アプローチ)|札幌の長期インターンシップインタビュー

私たちダイアモンドヘッド株式会社ではファッションアパレルに特化した商品情報を管理する自社サービスを展開しています。
サービスの中では商品に紐づく写真を多数管理しており、写真は規則に則って順序付け(並び替え)された状態でショッピングモールやショッピングアプリへと写真を含めたデータが配信されてます。
今回の記事は、商品画像の並び順を深層学習を用いて自動化する実験を主に長期インターンシップ参加者と新卒入社数名で取り組んだレポートを記事化しました。
参加したインターンシッププログラム
以下、レポート本文です。
1. 背景
現状では、弊社運営のスタジオで撮影した画像をお客様が閲覧できるようになった後、ECサイトにおいて表示したい画像の並びになるよう人手で並び替えを行っている。 しかし、全商品の全画像を手動で並び替えるのは非常にコストが大きい。
2. 目的
「1. 背景」で述べた画像の並び替えを、近年注目を浴びている人工知能技術である「深層学習」を活用して、自動で高速に行うことを試みる。
「レギュレーションに基づく画像ソート」(以下、本タスク)とは、与えられた画像群内の画像を任意のレギュレーションに基づいて並びかえる(ソート)することである。
例えば、以下のようなレギュレーションのもとで、入力となる画像群が与えられたとすると、その画像群内の画像を、「バック」が写っている画像は最初に、「洗濯タグ」が写っている画像は最後に、「袖」が写っている画像は中盤に、というように並び替えることを言う。

3.アプローチ
以前取り組んだランキング問題としてのアプローチ、すなわち、PointWise的な「Percentile Rank」を用いたアプローチとPairwise的なアプローチでは、新たなレギュレーションに基づいた画像ソートが必要になったときに、そのレギュレーションに則った教師データの作成が必要であることを指摘いただき、そのようなコストを削減するために画像分類によるアプローチを考えた。
これは、1枚の画像に対して、画像に「裾」が写っているのか「袖」が写っているのかなどを機械に予測させ、そのラベルに基づいて単純な辞書のソートなどで画像の並びを得ようとするものである。つまり、画像を分類し、その分類クラスを用いてソートする。
この分類問題としてのアプローチのメリットとデメリットをまとめると以下のようになる。
メリット
・画像のクラスに基づいてソートするため、レギュレーションごとに学習させる必要がなくなる。
・各画像につき一度しか深層学習モデルに入力しないため、計算量が画像枚数に対して線形。(pairwise手法ではO(N^2):Nは画像枚数)
デメリット
・クラス分類の性能がそのままソートの性能に直結する。(回帰より、モデルの出力値がソート結果に大きく影響する。)
結論から述べると、商品及びモデルの画像に対する分類は以下のような結果になった。
結果
商品画像とモデル画像の全17クラス分類でもある程度の性能は発揮できる。
裾や袖の間違いが多い。
学習データに含まれていないような珍しいカットや撮影方法の画像は間違えやすい。→幅広いジャンルと撮影スタイルのデータで学習することが最も重要に思える。
4. アーキテクチャ
実験におけるアーキテクチャは以下のようにした。事前学習済みモデルにConvNeXtを使ったのは、前回の実験である程度性能がよく、学習が早く終わることが分かったためである。

5.実験
DeepLearningの観点から本タスクの主問題である分類問題について、私の行った試行錯誤を述べる。
これまでは服の画像のみを扱っていたが、最終目標が服と人物が混じった全画像のソートであることを考慮し、まずはこれまで行ったことがなかった人物モデルの画像に対して以下のようなクラスを定義して分類を行うことを考えた。
“far_front” (全身&前)
“far_back”(全身&後ろ)
“far_side”(全身&横)
“near_front”(寄り&前)
“near_back”(寄り&後ろ)
“near_side”(寄り&横)
ただし、「全身」の定義は「肩からくるぶしあたりまで写っているもの」としている。次にそれぞれのクラスの例を示す。

ラベル付けと並列して学習を行ったため、段階的に2クラス分類、4クラス分類を行ってから、最終タスクである6クラス分類を行った。以下にそれぞれの実験の概要と結果を簡単に示す。
ここでのTrainの損失関数とValidの評価関数は、ともにCrossEntolopyを用いている。
2クラス分類:
2クラス分類の段階では、単純に画像を”near(寄り)”と”far(全身)”に分けることとした。学習の損失は以下のようになった。

Validの損失は以下のようになった。

結果は、3885画像中、3853画像正解、32画像不正解となり、かなり良い性能が出た。
4クラス分類:
4クラス分類では、”near_back”,“near_back以外”, “far_back”, “far_back以外”の4つのクラスに分類した。Trainの損失は以下のようになった。

Validの損失は以下のようになった。

結果は、3885画像中3856枚正解、29枚不正解となった。
6クラス分類:
モデル画像に対する最終タスクである6クラス分類では ”far_back”, “far_front”, “far_side”, “near_back”, “near_front”, “near_side” の6分類に分類を行った。Trainの損失は以下のようになった。

Validの損失は以下のようになった。

結果は以下のようになった。
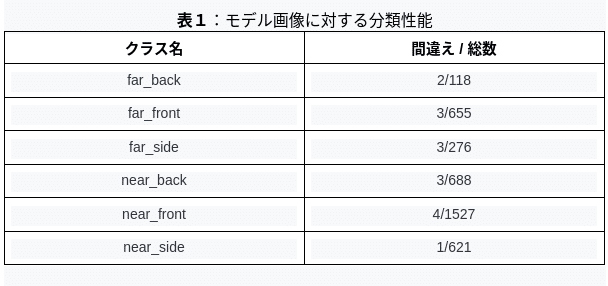
以上より、モデル画像に対する6分類程度ならかなり高精度で行えることが確認できた。
人間(モデル)に対する分類もある程度うまく行くことが分かったので、レギュレーションに基づく画像ソートの分類問題としてのアプローチの最終目標として、モデルが写った画像と服の画像を同時に分類するモデルの作成を試みた。ここで定義したクラスは以下の17クラスである。
1_brand_tag (ブランドタグ)
2_material (生地感)
3_print (プリント)
4_wash_tag (お洗濯タグなどのタグ類)
5_sleeve (袖)
6_sleeve_hem (袖&裾)
7_hem (裾)
8_feature (特徴カット)
9_collar (襟)
10_back (後ろからなど全体像を撮ったもの)
11_far_back (モデルの全身&後ろ向き)
12_far_front (モデルの全身&前)
13_far_side (モデルの全身&横)
14_near_back (モデルのより&後ろ)
15_near_front (モデルのより&前)
16_near_side (モデルのより&横)
17_near_zoom (モデルの一部分ズーム)
各クラスの例を次ページ以降に挙げる。



17クラス分類:
汎用的なカテゴリ7つに対して、上記のクラスのラベル付けを行い学習を行った。Trianの損失は以下のようになった。
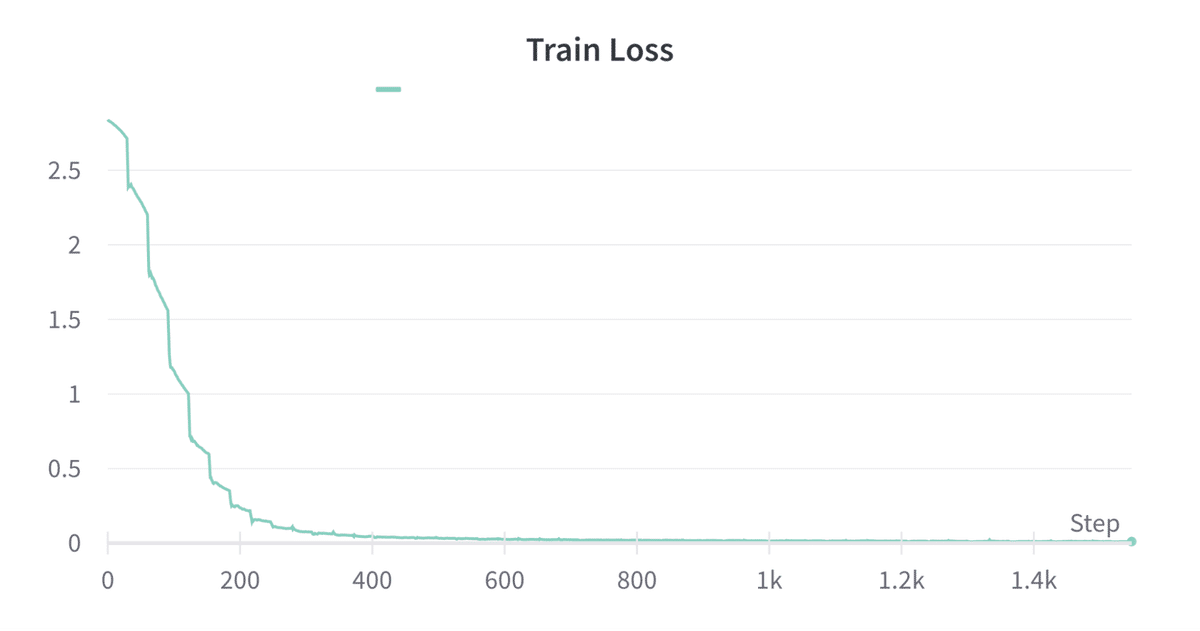
Validの損失は以下のようになった。

次に、学習に使用した汎用的なカテゴリとは別のカテゴリ5つに対して推論を行い検証した。以下がその検証結果である。

袖と裾の性能が著しく悪く、17_near_zoomもその次に悪い。一方で、それ以外のクラスではある程度の性能は出ている。
次に間違えたものの例を記載する。
1_brand_tag :
ブランドタグについて、唯一の間違いは以下であった。

これは、1_brand_tagとしたのは理解できるが、9_collar として欲しいところなので、間違いとなっている。
2_material:
間違った2つは以下であった。

ポケットを左のように写したような画像は訓練データにほとんどない。
右は人が着ているので17_near_zoomとしているが、この判定はかなり難しいように思える。
3_print:
間違えた6件は以下のようなものであった。

左上は人判定できていない。右上の間違いは、文字列に反応しているように思える。洗濯タグは間違えたくない。
4_wash_tag:

brand_tagとのミスが予想されていたが、予想通りになった。
5_sleeve:

基本的に学習データにあまり含まれていない画像で間違える。肘パッチやパーカー等の前開きの服を裏返したような画像は少なかった。左下は裾も写っているので不正解としているが、sleeveともとれなくないし、featureともとれなくない。
6_sleeve_hem:
間違いはなかった。
7_hem :

5_sleeveでも述べたように、前開きの服の裏地を撮ったものは少ない為間違えたと考えられる。左下以外は裾が写っておりhemとしても間違いではないかと思う。左下のように袖を裾と判別するのは避けたい。
8_feature :

真ん中や右はfeatureと考えられるような考えられないような。
9_collar :

上記のようなベストが間違いの全てであった。ベストは学習データにほとんど含まれていない。
11_far_back:

数枚の間違いがある。基本的にはfar_frontと間違える。
12_far_front:

farとnearの判定を間違えている。
13_far_side:

far内で間違える。原因は不明。
14_near_back:

マネキンに服を着せて撮影された画像は学習データにほとんど含まれていないため、間違えたように思える。おそらくマネキンを人と判定している。
15_near_front:

マネキンに服を着せて撮影された画像は学習データにほとんど含まれていない。
17_near_zoom:

マネキン画像とベストは学習にあまり含まれていない。右上と左下はあまり間違えたくない。
6. これまでのまとめ[総評]:
17クラス分類でもある程度の性能は発揮できる
裾や袖の間違いが多い。
学習データに含まれていないものはやはり間違えるため、幅広いジャンルと撮影テーマのデータで学習することが最も重要に思える。
高い正解率のクラスでも完璧というわけではない。
これまで対応していなかったモデル画像に対してもソートが行えそう
これからの課題
裾袖が精度が悪い。→データセットの拡充、augmentationをしてみる。
本当にタグ付けコストがかからないのか。→今回とは別クライアントのデータを用いて汎化性能を見る。
インターンシップに興味をお持ちの方へ
募集要項や応募選考フローや良くある質問などの情報を長期インターンシップ募集サイトにまとめました。興味をお持ちの方はリンク先をご確認下さいますようお願いします。

ダイアモンドヘッドの公式LINEアカウント
LINEアカウントを友達登録すると、チャットを利用しての個別相談や限定イベントへ参加できます。以下リンクから友達追加が可能です。
以上となります。ご拝読ありがとうございました。