アセットマネージャーのためのファイナンス機械学習:金融データのラベリング 練習問題 トリプルバリアとベットサイズ

前記事において、ボリュームバーにトリプルバリアを適用し、ラベルを作成した。
このラベルにランダムフォレスト分類器をフィットさせる。特徴量は、リターン、デイリー・ボラティリティ、歪度、尖度、移動平均などとし、トリプルバリアのラベリング$${-1,0,1}$$のうち、垂直バリアに触れたケース'0'を落とした。
TPlabels=getBinsTUML(TPevents,price,t1)
TPlabels = TPlabels[~(TPlabels['bin'] == 0)]
short=5
long=20
TPlabels=getBinsTUML(TPevents,price,t1)
TPlabels = TPlabels[~(TPlabels['bin'] == 0)]
short=5
long=20
Xy=(pd.DataFrame()
.assign(price=Vbar['Close'])
.assign(ewm=Vbar['Close'].ewm(short).mean()-Vbar['Close'].ewm(long).mean())
.assign(s_skew=Vbar['Close'].rolling(short).skew())
.assign(s_kurt=Vbar['Close'].rolling(short).kurt())
.assign(l_skew=Vbar['Close'].rolling(long).skew())
.assign(l_kurt=Vbar['Close'].rolling(long).kurt())
.assign(rtn=VbarRtn)
.assign(vol=DailyVol)
.assign(label=TPlabels['bin'])
).dropna()
Xy = Xy[~Xy.index.duplicated(keep='first')]
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
X= Xy.drop('label',axis=1).values
y = Xy['label'].values.astype(int)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=False)
rf = RandomForestClassifier(max_depth=32, n_estimators=1000,class_weight='balanced',
criterion='entropy',random_state=0)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)ランダムフォレストのパラメータは、グリッドサーチで求めた値を入れている。このモデルの性能とROC曲線は以下の通りとなった。
print(classification_report(y_true=y_test, y_pred=y_pred))
y_pred_rf = rf.predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, y_pred_rf)
roc_auc = auc(fpr, tpr)
plt.plot(fpr,tpr,label='RF ROC (area = %0.2f)' %(roc_auc))
plt.plot([0, 1],[0, 1],linestyle='--',color=(0.6, 0.6, 0.6),label='Random guessing')
plt.xlim([-0.05, 1.05])
plt.ylim([-0.05, 1.05])
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.legend(loc="lower right")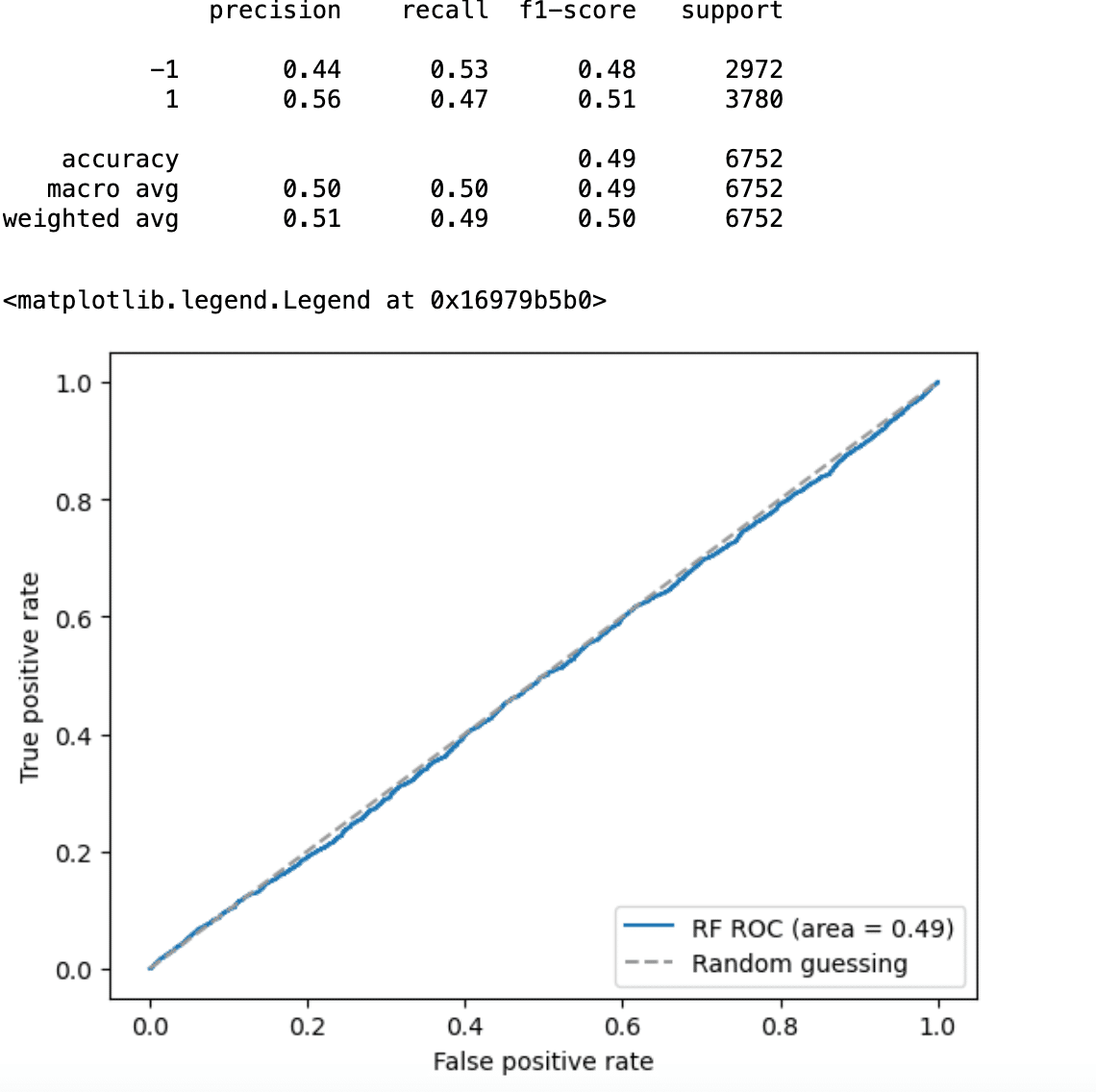
EWMAのクロスから、売りと買いのポジションのサイドを決め、メタラベルを作成する。
Vbar.short=Vbar['Close'].ewm(short).mean()
Vbar.long=Vbar['Close'].ewm(long).mean()
DCross, GCross = labels.getDCross(VbarX), labels.getGCross(VbarX)
buy = pd.Series(1, index=GCross.index)
sell = pd.Series(-1, index=DCross.index)
side = pd.concat([sell,buy]).sort_index()
EWMTPevents=labels.getEventsML(Vbar['Close'],Events,ptsl,DailyVol,minRet,t1=t1,side=side)
EWMTPevents= EWMTPevents.dropna()
EWMlabels=labels.getBinsTUML(EWMTPevents,Vbar['Close'],t1)このメタラベルをターゲットにして、さらに特徴量にポジションのサイドを加えて、ランダムフォレストを学習させる。
Xy['Meta']=EWMlabels.bin
Xy['side']=side
Xy=Xy.dropna()
Xy = Xy[~Xy.index.duplicated(keep='first')]
X= Xy.drop('Meta',axis=1).values
y = Xy['Meta'].values.astype(int)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=False)この結果に、メタラベルをあてた性能と混合行列は以下の通りである。
y_pred_meta = (y_pred & y_test)
print(classification_report(y_true=y_test, y_pred=y_pred_meta))
confmat=confusion_matrix(y_test, y_pred_meta)
fig, ax = plt.subplots(figsize=(2.5, 2.5))
ax.matshow(confmat, cmap=plt.cm.Blues, alpha=0.3)
for i in range(confmat.shape[0]):
for j in range(confmat.shape[1]):
ax.text(x=j, y=i, s=confmat[i, j], va='center', ha='center')
plt.xlabel('Predicted label')
plt.ylabel('True label')
plt.tight_layout()
plt.show()
accuracy = (y_test == y_pred_meta).sum() / y_test.shape[0]
print('Accuracy: ', round(accuracy, 4))

このモデルの結果をもとに、ビットサイズを決める。
getSignalで使うsideはメタラベルであって、売り買いのポジションとは違うことに留意し、売り買いのポジションはPosiとして扱う。
CUMSUM=pd.DataFrame()
CUMSUM.index=Xy.index
CUMSUM['prob'] = rf.predict_proba(X)[:,1]
CUMSUM['pred'] = rf.predict(X)
CUMSUM['side'] = EWMlabels.bin
CUMSUM['t1']=EWMTPevents['t1']
CUMSUM['Price']=Xy['price']
CUMSUM.dropna()
import BetSizeFM as BsFM
from scipy.stats import norm
CUMSUM['BetSize']=BsFM.getSignal(CUMSUM,0.01,CUMSUM['Prob'],CUMSUM['pred'],2)
CUMSUM['Posi']=side
CUMSUM['cumsum']=CUMSUM.BetSize*CUMSUM.Price*CUMSUM.Posiここで、買いのシグナルの時に買い、売りで売ったとする。
時系列最後の時点で所持している(売られていない)E-mini S&P先物の量と、価値は以下のように与えられる。

この記事が気に入ったらサポートをしてみませんか?