
SageMaker Clarifyで特徴量重要度を出力する

電通デジタルで機械学習エンジニアをしている今井です。
本記事では、SageMaker Clarifyで特徴量重要度を出力する方法について紹介します。
昨今、AIや機械学習に対する説明可能性が注目されており、SHAP(SHapley Additive exPlanations)が広く用いられています。
SHAPはゲーム理論のShapley Valueに基づいてそれぞれの特徴量の予測への貢献度を計算する手法です。
詳細は元論文[1]や書籍[2](または有志による日本語翻訳)を参照ください。
SageMaker Clarifyは2020年12月に発表された新サービスで、バイアス検出と説明可能性のための機能が提供されています。
本記事ではそのうちSHAP特徴量重要度(feature importance)の出力について紹介します。
まずは従来どおりSageMakerトレーニングジョブでモデル学習を行います。
データは参考文献[3][4]をもとに事前準備します。

ここでは代表的なモデルとして、組み込みアルゴリズムのLinear LearnerとXGBoost、SageMaker Autopilotを使用します。
なお、実行環境はsagemaker==2.45.0で検証しています。
import sagemaker
from sagemaker.s3 import S3Uploader
from sagemaker.inputs import TrainingInput
from sagemaker.amazon.linear_learner import LinearLearner
from sagemaker.image_uris import retrieve
from sagemaker.estimator import Estimator
from sagemaker.automl.automl import AutoML
from sagemaker import clarify
import boto3
import json
from os import path
from urllib.parse import urlparse
import pandas as pd
import numpy as np
role = sagemaker.get_execution_role()
session = sagemaker.Session()
# Linear Learner
training_target = training_data['Target'].to_numpy().astype(np.float32)
training_features = training_data.drop(['Target'], axis=1).to_numpy().astype(np.float32)
ll = LinearLearner(
role=role,
instance_count=1,
instance_type='ml.m5.xlarge',
predictor_type='binary_classifier',
sagemaker_session=session)
ll.fit(records=ll.record_set(training_features, training_target))
# XGBoost
training_data.to_csv('train_data.csv', index=False, header=False)
train_uri = S3Uploader.upload('train_data.csv', 's3_path'.rstrip('/'))
train_input = TrainingInput(train_uri, content_type='csv')
xgb = Estimator(
image_uri=retrieve('xgboost', 'ap-northeast-1', version='1.2-1'),
role=role,
instance_count=1,
instance_type='ml.m5.xlarge',
sagemaker_session=session)
xgb.set_hyperparameters(objective='binary:logistic', num_round=100)
xgb.fit({'train': train_input})
# Autopilot
training_data.to_csv('train_data.csv', index=False, header=True)
train_uri = S3Uploader.upload('train_data.csv', 's3_path'.rstrip('/'))
automl = AutoML(
role=role,
target_attribute_name='Target',
problem_type='BinaryClassification',
job_objective={
'MetricName': 'AUC'
},
max_candidates=10,
sagemaker_session=session)
automl.fit(inputs=train_uri)学習が完了したらモデルのホスティングを行います。
model_name = 'model_name'
# Linear Learner and XGBoost
model = {ll|xgb}.create_model(name=model_name)
container_def = model.prepare_container_def()
# Autopilot
inference_response_keys = ['predicted_label', 'probability']
model = automl.create_model(
name=model_name,
candidate=automl.best_candidate(),
inference_response_keys=inference_response_keys)
container_def = model.pipeline_container_def('ml.m5.xlarge')
session.create_model(model_name, role, container_def)ここからはSHAP特徴量重要度の出力です。まずはSageMaker Clarifyを定義します。
clarify_processor = clarify.SageMakerClarifyProcessor(
role=role,
instance_count=1,
instance_type='ml.m5.xlarge',
sagemaker_session=session)次にDataConfig、ModelConfig、およびSHAPConfigを定義します。
執筆時点ではこれらの content_type としてtext/csvとapplication/jsonlinesのデータ型が対応しています。
application/jsonlinesは1行が
{"features": [39, 5, 77516, 9, 13, 4, 0, 1, 4, 1, 2174, 0, 40, 38], "label": 0} のようなデータ形式です。
ModelConfigはホスティングのモデル名を使用して以下のように定義します。
# XGBoost and Autopilot
model_config = clarify.ModelConfig(
model_name=model_name,
instance_type='ml.m5.xlarge',
instance_count=1,
accept_type='text/csv',
content_type='text/csv')
# Linear Learner
model_config = clarify.ModelConfig(
model_name=model_name,
instance_type='ml.m5.xlarge',
instance_count=1,
accept_type='application/jsonlines',
content_type='application/jsonlines',
content_template='{"features": $features}')SHAPConfigはそれぞれ以下のように定義します。
df = pd.read_csv('adult.data', names=adult_columns, sep=r'\s*,\s*', engine='python', na_values='?').dropna()
baseline = list()
for (c, d) in df.loc[:, df.columns != 'Target'].dtypes.items():
if d == np.object:
baseline.append(int(training_data[c].mode()))
else:
baseline.append(training_data[c].mean())
# XGBoost and Autopilot
shap_config = clarify.SHAPConfig(
baseline=[baseline],
num_samples=15,
agg_method='mean_abs',
use_logit=True)
# Linear Learner
shap_config = clarify.SHAPConfig(
baseline=[{'features': baseline}],
num_samples=15,
agg_method='mean_abs',
use_logit=True)baseline は数値列であれば中央値や平均値、離散値列であれば最頻値を指定します[5]。
また今回はBinaryClassificationのため use_logit=True とします。
DataConfigは以下のように定義します。
# XGBoost and Autopilot
headers = training_data.columns.to_list()
data_config = clarify.DataConfig(
s3_data_input_path=train_uri,
s3_output_path='s3_output_path'.rstrip('/'),
label='Target',
headers=headers,
dataset_type='text/csv')
# Linear Learner
with open('train_data.jsonl', 'w') as f:
for _, row in training_data.iterrows():
print(json.dumps({
'features': row.drop('Target').tolist(),
'label': int(row['Target'])
}), file=f)
train_uri = S3Uploader.upload('train_data.jsonl', 's3_path'.rstrip('/'))
headers = training_data.loc[:, training_data.columns != 'Target'].columns.to_list()
data_config = clarify.DataConfig(
s3_data_input_path=train_uri,
s3_output_path='s3_output_path'.rstrip('/'),
headers=headers,
features='features',
dataset_type='application/jsonlines')Configを定義したらrun_explainabilityを実行します。
clarify_processor.run_explainability(
data_config=data_config,
model_config=model_config,
explainability_config=shap_config,
model_scores=model_scores)ここで引数 model_scores は各モデルの推論結果の出力形式で決まります。
XGBoostの場合
0.2
0.7
0.3のように予測確率のみ1列での出力のため model_scores=None です。
Autopilotは本記事では
inference_response_keys = ['predicted_label', 'probability'] としたため
0,0.2
1,0.7
0,0.3となり、model_scores=1 としてインデックス番号を指定します。
Linear Learnerの場合
{"predicted_label": 0, "score": 0.2}
{"predicted_label": 1, "score": 0.7}
{"predicted_label": 0, "score": 0.3}のため予測確率を表す model_scores='score' とします。
run_explainabilityが完了すると、DataConfig.s3_output_path配下にreport.pdfやanalysis.jsonが作成されます。
report.pdfには重要度が上位10件の特徴量がプロットされています。

全特徴量の重要度を出力したい場合にはanalysis.jsonから取得します。
parse = urlparse(data_config.s3_output_path)
obj = boto3.client('s3').get_object(
Bucket=parse.netloc,
Key=path.join(parse.path.strip('/'), 'analysis.json'))
importance = json.loads(obj['Body'].read())['explanations']['kernel_shap']['label0']['global_shap_values']
pd.Series(importance).sort_values(ascending=False).plot(kind='bar', rot=90)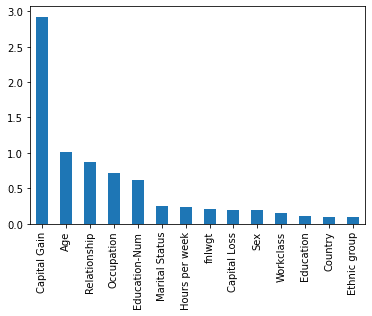
本記事では組み込みアルゴリズムを使用しましたが、データ/推論形式に合わせてConfigを定義できれば独自アルゴリズムを含む任意のモデルに対してSageMaker Clarifyを適用することも可能です。
参考文献
[1] Lundberg+, A Unified Approach to Interpreting Model Predictions, 2017
[2] Christoph Molnar「Interpretable Machine Learning」
[3] https://sagemaker-examples.readthedocs.io/en/latest/sagemaker_processing/fairness_and_explainability/fairness_and_explainability.html
[4] https://sagemaker-examples.readthedocs.io/en/latest/sagemaker_processing/fairness_and_explainability/fairness_and_explainability_jsonlines_format.html
[5] https://docs.aws.amazon.com/sagemaker/latest/dg/clarify-feature-attribute-shap-baselines.html