
DynamoDBの一括書き込みCLIで運用作業を楽にした話

電通デジタル開発部の平沼です。
本記事は電通デジタルアドベントカレンダー2021 7日目の記事になります。
本記事では、DynamoDBに大量のデータを書き込む際、運用を少し楽にするために内製したツールをご紹介します。
課題感
新しいサービスをリリースする際の初期データの登録やテストデータの登録など、DynamoDBにデータを書き込む場面は多いです。書き込む選択肢は主にAWS Command Line Interface (AWS CLI)やAWSマネジメントコンソールがあります。

AWS CLIで一度に複数の項目を追加する場合、batch-write-item APIやtransact-write-items APIがあります。それぞれのユースケースとしては下記が考えられます。(表内の例はAWSのサンプルを利用しています。ProductCatalog, Thread, Forum)

今回のユースケースとしては単一のテーブルに作成したデータを手動で一度書き込むことなのでbatch-write-item APIを利用しました。
batch-write-item APIは便利ですが、面倒だと思う点もあります。
インプットとなる JSON 形式のファイルを作成するのが大変
一度に最大25件のデータまでしか書き込めない
インプットとなる JSON 形式のファイルを作成するのが大変
AWS DynamoDBのサンプルデータを見ると、下記のようになっています。
{
"Reply": [
{
"PutRequest": {
"Item": {
"Id": {
"S": "Amazon DynamoDB#DynamoDB Thread 1"
},
"ReplyDateTime": {
"S": "2015-09-15T19:58:22.947Z"
},
"Message": {
"S": "DynamoDB Thread 1 Reply 1 text"
},
"PostedBy": {
"S": "User A"
}
}
}
},
{
"PutRequest": {
"Item": {
"Id": {
"S": "Amazon DynamoDB#DynamoDB Thread 1"
},
"ReplyDateTime": {
"S": "2015-09-22T19:58:22.947Z"
},
"Message": {
"S": "DynamoDB Thread 1 Reply 2 text"
},
"PostedBy": {
"S": "User B"
}
}
}
},
{
"PutRequest": {
"Item": {
"Id": {
"S": "Amazon DynamoDB#DynamoDB Thread 2"
},
"ReplyDateTime": {
"S": "2015-09-29T19:58:22.947Z"
},
"Message": {
"S": "DynamoDB Thread 2 Reply 1 text"
},
"PostedBy": {
"S": "User A"
}
}
}
},
{
"PutRequest": {
"Item": {
"Id": {
"S": "Amazon DynamoDB#DynamoDB Thread 2"
},
"ReplyDateTime": {
"S": "2015-10-05T19:58:22.947Z"
},
"Message": {
"S": "DynamoDB Thread 2 Reply 2 text"
},
"PostedBy": {
"S": "User A"
}
}
}
}
]
}見て分かる通りネストが深く見づらく、またこの形式で作成するのも大変です。手動でインプットファイルを作成する人は少ないかもしれません。 AWS公式ブログでAWS S3、AWS Lambdaを利用したCSVからの一括取り込みの実装紹介記事や、PowerShellでExcelファイルからこの形式に出力するスクリプトを紹介しているブログはありました。またQ&Aサイトでも未だにこのような質問が頻出しており、いくつかGithuHubのリポジトリのツールが紹介されていました。しかし、スターが多いツールは見当たらず、決定的なソリューションはなかったため今回作成に至りました。
一度に最大25件のデータまでしか書き込めない
リファレンスにも記載があるとおり、一度の実行で最大25件のデータまでしか書き込めないため、それ以上の場合はインプットファイルを分割する必要があります。
上記で挙げた面倒なポイントと既存ソリューションを鑑みてCLIを作ることにしました。
DynamoDB Batch Write CLI (dybw)
dybwは下記の特徴があります。
インプットを手動でも作りやすいフォーマットにした
書き込みたい件数によってファイル分割を考える必要がない
未処理のデータがある場合は自動リトライ
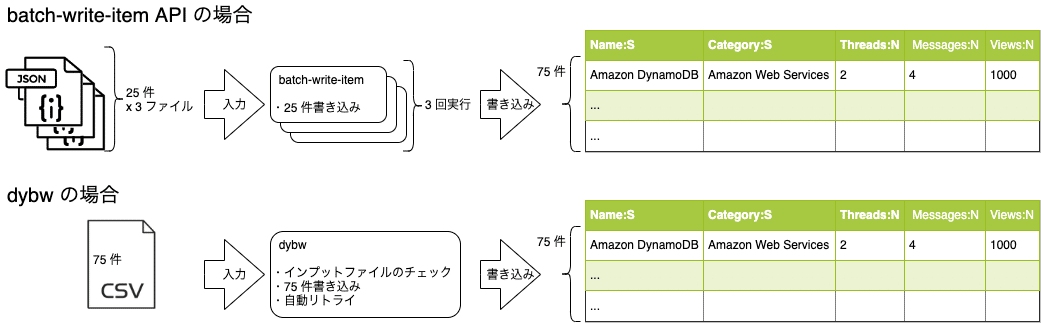
ユーザは、インプットファイル(input.csv)を準備すると下記のように実行できます。
$ cat input.csv
Id:S,ReplyDateTime:S,Message:S,PostedBy:S
Amazon DynamoDB#DynamoDB Thread 1,2015-09-15T19:58:22.947Z,DynamoDB Thread 1 Reply 1 text,User A
Amazon DynamoDB#DynamoDB Thread 1,2015-09-22T19:58:22.947Z,DynamoDB Thread 1 Reply 2 text,User B
Amazon DynamoDB#DynamoDB Thread 2,2015-09-29T19:58:22.947Z,DynamoDB Thread 2 Reply 1 text,User A
Amazon DynamoDB#DynamoDB Thread 2,2015-10-05T19:58:22.947Z,DynamoDB Thread 2 Reply 2 text,User A
$ dybw put --table Reply --use-sortkey --execute --input-csv input.csv --out reply
# 短縮 Ver. $ dybw p -t Reply -s -e -i input.csv -o reply上記はSampleTableテーブルにinput.csvに記載したデータをPutするコマンドです。以下オプションを説明します。
--use-sortkey(-s)
ソートキーがある場合に指定する必要があります。インプットファイルを読み込んだ際、データがユニークかどうかを判断するために利用しています。--execute(-e)
実際に書き込みを行うオプションです。指定しない場合はdry-runとなります。--input-csv(-i)
インプットファイルを指定します。--out(-o)
インプットファイルをbatch-write-item APIのインプットに利用できるJSON形式のファイルに変換し、指定先に出力します。
インプットを手動でも作りやすいフォーマットにした
PutやDeleteといった操作の記述はインプットファイルから省いています。これは前述したとおりサブコマンドで指定するようにしています。つまり、一度のコマンド実行ではPutかDeleteのいずれかのみ実施できるようにしています。理由としては、今回の用途ではPutとDeleteを混ぜて使うことは少ないこと、またインプットファイルが見やすくなるためです。
インプットファイルはCSV形式としています。GoogleスプレッドシートやMicrosoft Excelでも作成でき、参照もしやすいためです。
ヘッダは、<属性名><デリミタ><カラムタイプ>の形としています。デリミタは、コマンド実行時のオプションで変更可能です。下記はサンプルデータをCSV形式で書いた場合の例です。
Id:S,ReplyDateTime:S,Message:S,PostedBy:S
Amazon DynamoDB#DynamoDB Thread 1,2015-09-15T19:58:22.947Z,DynamoDB Thread 1 Reply 1 text,User A
Amazon DynamoDB#DynamoDB Thread 1,2015-09-22T19:58:22.947Z,DynamoDB Thread 1 Reply 2 text,User B
Amazon DynamoDB#DynamoDB Thread 2,2015-09-29T19:58:22.947Z,DynamoDB Thread 2 Reply 1 text,User A
Amazon DynamoDB#DynamoDB Thread 2,2015-10-05T19:58:22.947Z,DynamoDB Thread 2 Reply 2 text,User Aインプットファイル読み込み時にデータがパーティションキーとソートキーでユニークかどうかを判定するため、パーティションキー、ソートキー、その他の項目の順番で記載するようにしています。図示したものが下記になります。

ソートキーがない場合は、コマンドオプションで--use-sortkey(-s)を指定しないことで、パーティションキーのみでユニークかどうかの判定を行います。
書き込みたい件数によってファイル分割を考える必要がない
内部で25レコードごとにデータを生成してbatch-write-item APIを実行することで、ユーザはレコード数を気にせずに必要なデータを準備するだけでよくなりました。
未処理のデータがある場合は自動リトライ
batch-write-item APIは実行に失敗したデータをレスポンスのUnprocessedItemsフィールドで返却します。このUnprocessedItemsの値はそのままリクエストとして利用できる形式となっています。
ドキュメントでは、
"Typically, you would call BatchWriteItem in a loop. Each iteration would check for unprocessed items and submit a new BatchWriteItem request with those unprocessed items until all items have been processed."
(意訳: 通常は未処理のデータがなくなるまで、繰り返しBatchWriteItemをコールする。)
と記載があります。そのため値がある場合は自動でリトライするようにしています。
実装で気遣った点、面倒だった点
気遣った点
dybwでは、dry-runをデフォルトの挙動にしており、実際に書き込む場合は--execute(-e)オプションを付ける必要があります。dybwはDynamoDBに直接書き込むため、入力ファイルを間違えて実行すると事故につながってしまいます。これを防止するためdry-runをデフォルトにしました。dry-runモードで実行した場合は、書き込まれる予定のデータがコンソール上に出力されます。インプットファイル読み込み時のチェックや各オプションについても機能します。
面倒だった点
CLIはGolangで実装しています。面倒な点はインプットファイルから読み込んだデータをBatchWriteItemの入力形式に合わせて変換するところでした。インプットファイルを読み込んだ後、JSON形式でも出力できるようにするため、内部でAWS CLIのbatch-write-item APIの入力形式に合わせてmapへ変換しています。さらにmapからBatchWriteItemの入力形式へ変換しています。mapがとても深いネストとなっているため扱いづらかったです。今にして思えば、JSON出力用とBatchWriteItem入力用で分けて変換していれば苦労はなかったんですが、実装当時は思いつかなかったので次バージョンで修正しようと考えています。
数回利用して気づいた点
インプットファイルが数万行になると、実行環境によりますが、コマンド実行時に一度に全行読み込むところでOut Of Memoryが起きてしまうことがあります。これは一度にファイルから読み込んで処理する行数を制御するようにして解決しました。以降は使いづらさもなく今までより少し楽に書き込み作業ができています。
おわりに
手動でも作りやすいインプットフォーマットにする、ユーザが書き込み件数を意識しないようにする、自動リトライを入れることでDynamoDBへのデータ書き込みが少し楽になりました。
今後の展望としては、コマンド実行後の中断や再開ができる機能の実装や、書き込みなどにかかった時間の計測ができていないので計測機能の実装できればと考えています。数万行のCSVを書き込む際に中断/再開の仕組みがあると、リトライを加味したバッチに利用できたり、時間がかかりすぎた場合にファイルを再分割せずに対応できるため、便利かなと思っています。