
[競馬予想AI] ランク学習で着順予想するとなかなか強力だったお話

前回までは、決定木系のアルゴリズムを使用したモデル作成と、その評価やチューニングについて紹介してきました。
今回は、前回までのアルゴリズムとは異なるアルゴリズムを使って競馬の着順予想をしていこうと思います。
今回使うアルゴリズムはLambdaRankです。
結果としてはなかなか使えるモデルが完成したと思いますので、結果だけ気になる方は後半の「各種馬券の的中率は?」をご覧ください。
(2020/6/14追記)
学習データの不備を修正しました。それにより、的中率と参考回収率に変更がありましたので追記いたします。
前回までのアルゴリズムの欠点
前回までのアルゴリズムでいまいち性能が出なかったのは、ただ単に膨大なデータ点をクラスタリングしようとした点です。レースでは相対的な馬の強さが重要であるため、全データから強そうな馬の特徴を見つけることは困難です。
今回はこの相対的な強さをきちんと考慮したアルゴリズムとなります。具体的には、前回までには無かったレースというグループの概念を取り入れています。
LambdaRankとは
検索エンジンなどに使われていて、検索文字を入力するとその内容に適したページを適合度が高い順に並べてくれるものです。このモデルのキモは、適合度と並び順です。
今回はこのLamdaRankを競馬データに適用してみました。
データの準備
必要なデータは今までと同じですが、加えてqueryデータが必要になります。queryデータはどこからどこまでのデータをひとまとまりとして扱うかを表すデータです。
競馬ですと1レースごとが1まとまりのデータになろうかと思います。
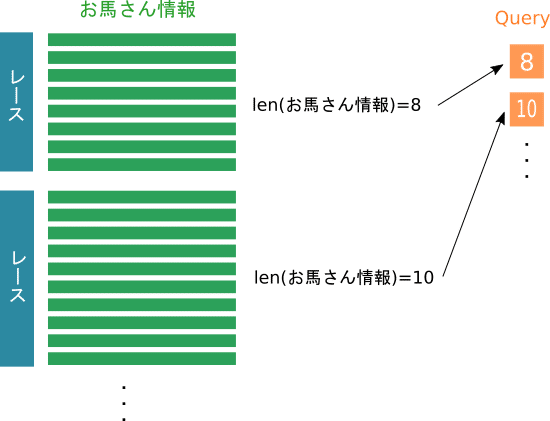
お馬さん情報の中にはレースを一意に特定できるrace_id的なものが含まれているので、groupby関数などでお馬さん情報の件数をカウントすればqueryデータは作成できますね。
「レースの数=queryデータの長さ」となり、queryデータは1次元のデータ構造になります。
もう1つ、教師データ(target)についてですが、こちらの中身は関連度です。関連度が高い方が上位へ来るように設定します。つまり、1着>2着>3着となるように値を設定します。具体的には1着は5、2着は3、3着は1といった具合です。
今回は「着順の逆数を取って×10し、4着以降は0」としました。コード的にはこんな感じです。実装の簡単さも考慮してこれでよしとします。
target = [int(1.0/i*10) if i < 4 else 0 for i in data["rank"]]これで1着は10、2着は5、3着は3、4着以降は0になります。
この関連度の設定方法にはいくつかあると思います。例えば賞金です。賞金が高い馬の方が強いだろうという仮定が成り立ちそうだからです。
このあたりの設定についてはみなさん色々工夫してみてください。(ココが面白いところ!)
これでデータの準備は完了です。
お馬さんデータを学習させる
いよいよ実際にデータを食べさせて学習させます。
noteの更新が遅くなったのは、データの食べさせ方とパラメータの解釈に時間がかかったからです。調べても詳しい日本語ドキュメントはほとんど出てきませんでした。英語の公式ドキュメントを読んでいじっているうちに時間が経ってしまいました。
今回使うのはLightGBMで、その中のLamdaRankを使用します。各種パラメータの設定はある程度デフォルトでも問題なく動作しますが、やはりチューニングは必要になると思います。今回は取り急ぎ最低限のチューニングを行って学習しています。
LightGBMのインストール手順は省略します。
LambdaRankの動かし方は2つあり、1つは学習データやパラメータの設定ファイルを読み込んでコマンド実行するパターンと、もう1つは学習データをPythonプログラム内でDataFrameなどで用意して実行するパターンです。
データ加工などDataFrameの方がやりやすいので(やりやすいとは言ってない)今回は後者を採用します。
#lightGBMのパラメータ設定
max_position = 20
lgbm_params = {
'objective': 'lambdarank',
'metric': 'ndcg',
'lambdarank_truncation_level': 10,
'ndcg_eval_at': [1,2,3],
'learning_rate': 0.01,
'boosting_type': 'gbdt',
'random_state': 777,
}
#学習
train = lgb.Dataset(train_data, train_target, group=train_query)
valid = lgb.Dataset(val_data, val_target, reference=lgtrain, group=val_query)
model = lgb.train(
lgbm_params,
lgtrain,
num_boost_round=100,
valid_sets=valid,
valid_names=['train','valid'],
early_stopping_rounds=20,
verbose_eval=5
)パラメータの'objective'は'lambdarank'を指定することでLightGBMでLambdaRankが使えます。評価関数はndcg、'ndgc_eval_at'は上位3つ[1,2,3]を指定しています。これは馬券圏内のみを考慮するためです。
学習データ(train)とバリデーションデータ(valid)、教師データ(target)を準備して、それぞれ学習器に入れるだけです。(教師データを使わず動かしてる例があったりして、そこの理解に時間がかかりました。)
通常の分類器と異なるのは、queryデータを指定する点です。バリデーションデータにはreferenceオプションでtrainを指定するのを忘れずに。
過学習防止のため、early_stopping_roundsの設定も重要です。
テストデータで予測させてみる
学習ができたら、早速テストデータで予測させてみましょう。
#テストデータで予測する
pred = model.predict(test_data, num_iteration=model.best_iteration)さきほどのモデルにテストデータを入れてpredict関数を呼び出すだけです。
予測結果に、実際の着順をくっつけてソートしたものがこちらです。
query_id pred true
0 0.138933394341269 1
0 0.13160600424035 7
0 0.120605448916792 3
0 0.107421695208755 5
0 0.085786402385561 9
0 0.084729663748046 11
0 0.082840123263615 8
0 0.065516105636695 4
0 0.052830554176945 10
0 0.04478674967569 12
0 0.041674522933117 13
0 0.037819802489508 2
0 0.005449532983656 6
0 0 14
1 0.115876945737174 4
1 0.098069737694005 3
1 0.086219663635577 1
1 0.083399607681719 14
1 0.073689392110932 2
1 0.073297030104782 12
1 0.06479679568379 11
1 0.063599255981776 8
1 0.061754796064301 9
1 0.058858897958897 10
1 0.051301180951365 13
1 0.051234690921533 15
1 0.047669721846512 5
1 0.045957170907081 6
1 0.024275112720557 7
1 0 16
・・・predの列が予測して出力された値です(今後アンサンブル学習させるために標準化しています)。query_idが同じものが同じレースという意味です。trueの列が実際の着順(答え)です。
予測結果であるpredの値の絶対的な大小に意味はなく、相対的な大小関係のみ見てください。
スペースの関係上、2レース分くらいしかお見せできませんがどうせしょうか?何となく上側に着順が小さいものが来てるような気がしませんか?もともと3着まで考慮してないので上側3つ分がきちんと予測できていればよしとします。
これは綺麗に予測できてる方だと思います。
23 0.197126862166266 1
23 0.136376255464705 2
23 0.124601343283186 3
23 0.115575428706921 4
23 0.11402240920553 7
23 0.09759020676793 8
23 0.090776223609383 11
23 0.044513724478309 6
23 0.03128305881678 10
23 0.031084845863058 5
23 0.017049641637933 9
23 0 12
24 0.157877665729012 1
24 0.151702492716404 2
24 0.148914269518451 9
24 0.142653512432766 4
24 0.123786661191349 6
24 0.085884431168736 10
24 0.065270772567894 3
24 0.055769533192577 12
24 0.036574472675945 11
24 0.021042198804412 5
24 0.010523990002455 7
24 0 823番のレースは3連単当ててますね!次の24番は馬単とワイドがいけます。ほかのレースもワイドを当ててるのが割と多い印象がありました。
各種馬券の的中率は?
ということで気になる精度ですが、今回はテストデータのうち各種馬券がどの程度の割合で正解しているかを計算してみます。(6516レース分)
予測した上位3つ分のみ考慮していることに注意してください。
(2020/6/14追記:学習データの不備の修正に伴い、的中率および参考回収率の数値を訂正しました。)
参考回収率とは?
以降、参考回収率を表示しています。
過去の約45,000レースの各種馬券の配当金の調和平均を使用して算出しています。よく使う算術平均より小さな値になります。調和平均のほうが体感的に現実味のある値になるので調和平均を採用し、厳しめに評価しました。
算術平均で計算した場合、参考回収率は調和平均より大きくなります。
単勝の的中率:26.90%
1着だと予測したものが実際に1着だった割合です。1番人気の馬を選んだ場合の的中率は約30%と言われているのでよく予測できているのではないでしょうか。(参考回収率:108.9%)
複勝の的中率
予測した3頭のうち、1頭以上複勝圏の馬が含まれている割合:90.28%
予測した3頭の馬のうち、1着または2着または3着の馬が1頭以上含まれている割合です。
1着と予測したものが複勝圏の馬であった割合:57.72%
1着と予測した馬が1着または2着または3着であった割合です。(参考回収率:119.5%)
2着と予測したものが複勝圏の馬であった割合:47.42%
2着と予測した馬が1着または2着または3着であった割合です。(参考回収率:98.16%)
3着と予想したものが複勝圏の馬であった割合:38.68%
3着と予測した馬が1着または2着または3着であった割合です。(参考回収率:80.1%)
1着予測の馬のみ参考回収率が100%を上回りました。また、3頭のうち複勝圏の馬が1頭以上含まれている割合が89.72%なので軸馬を選んだらもう1頭はこの3頭の中から選ぶなど、いろんな戦略がとれるかもしれません。
馬単の的中率:6.32%
1着と2着と予測した馬が実際に1着と2着だった割合です。ランダムに選んでも18頭レースの場合は約0.33%、12頭レースの場合は約0.55%の確率なのでかなりいい的中率だと思います。(参考回収率:137.2%)
ワイドの的中率:47.00%
こちらは予測した1~3着の馬のすべての組み合わせ(3通り)のうち、1着-2着、1着-3着、2着-3着のいずれか1つ以上の組み合わせが含まれる割合です。(参考回収率:94.0%~)
3通り購入なので、複数的中する可能性があります。
3連複の的中率:6.46%
予測した3頭で3連複が的中した割合です。(参考回収率:169.0%)
ランダムに選んでも18頭レースの場合は約0.122%、12頭レースの場合は約0.45%なのでかなりいい的中率だと思います。回収率もなかなかです。
3連単の的中率:1.69%
予測した3頭がピッタリ合致した割合です。(参考回収率:206.2%)
ランダムに選んでも18頭レースの場合は約0.020%、12頭レースの場合は約0.076%なのでかなりいい的中率だと思います。3連単は回収率が200%を超える結果となりました。
一部馬券の的中率が時間の都合で間に合いませんでしたが、当モデルの性能をなんとなく把握していただければ幸いです。
競馬に関してド素人の人間がここまで予測できれば十分ではないでしょうか。思っていた以上の性能が出て驚きました。
今後について
今回は取り急ぎテストデータを予測するところまで作りました。なのでまだ本格的なチューニングができていません。また、一部学習データに不具合があることが判明したのでその修正をする必要もありそうです。
関連度の作り方も、もう少し考慮する必要がありそうですね。なので、次回はこのモデルの磨き上げをメインにやっていこうと思います。時間があれば実践投入までやりたいですね!
☑学習データの修正(完了し追記済)
☑モデルのチューニング(完了)
☑関連度の作り方の違いによる精度評価(関連度のバリエーションでアンサンブル学習?)(完了)
○テストデータの回収率を実際のオッズデータを元に算出してみる
○競馬予想AI実戦投入
▼FANBOX
月額支援していただきますと当月間noteと同様の予想をご覧いただけます。
よろしければサポートをよろしくお願い致します。いただいたサポートは今後の技術向上のために書籍費用等に当てられ、このnoteで還元できればと思います。