
学長のアー写を検証してみた。

大阪産業大学の学長は、2023年9月に吉川耕司(よしかわ こうじ)先生(デザイン工学部 教授)から、小川和彦(おがわ かずひこ)先生(工学部 教授)に代わりました(任期は3年間)。
新しい学長が就任してまずやることはご挨拶ですよね。
そして、学長ご自身のアー写、ならぬ肖像写真が掲載されます。
大学の顔である学長のアー写ですから、大学のカラーやこれからの経営戦略も含めて検討され、撮影、現像されているものと考えます。
小川先生の写真を見てみましょう。

うーん。なんですかね。
なんか、あまり大学の学長、っていう感じがしないというか。
強そう?怖そう?な雰囲気じゃないですか。
なんだか言葉にできない違和感を感じましたので、他大学の学長肖像写真と比較して、284枚の大学の学長写真を用いて検証してみました。
結論を先に述べています。
検証方法はその下に書いていますので、pythonなどに興味のある方はご覧ください。
結論
私が感じた違和感は、データからも示すことができました。
すなわち、腕組みをする学長の写真は非常に稀であるということ(全体の1%)。
そして、写真の輝度が他と比較して大きく外れて低く、暗かったということです(偏差値26.6)。
これは、ある意味で非常に個性的で、「尖った」写真を採用したと言えます。
おそらく、広報課が戦略的にこの写真を採用したのでしょう。
重要なのは、教育機関の長としてふさわしい写真なのか、という点です。
例えば、ビジネス分野では以下のような記事があります。
企業トップのポートレートでは「腕組み」は御法度。見る人に与える無意識の心理的マイナスイメージの代表例
他にも、
「企業のウェブサイトで社長が腕組みしていると株価が下がる」という法則で、ご存じの方も多いと思います。
といった噂というか都市伝説的な話もあるようです。いずれも、良い印象を抱かせるものではありません。
私個人の意見としては、組織のトップが腕組みした写真は、
「虚勢を張り、相手を拒絶している」
という印象が強く、好ましくないです。
他の多くの大学の学長写真が、明るく優しい雰囲気のものを採用していたのは、多くの学生を受け入れ、多様な価値観や個性が育つ場のイメージを持ってもらうためでしょう。
やはり教育機関としては、腕は開き、笑顔でいわゆる、
「すしざんまいのポーズ」

が最適であろうと考えています。
ぜひ弊学のリーダーにも、すしざんまいのポーズでアー写を撮影いただきたいものです。
検証方法
学長の写真は大学のホームページに貼られていますので、
ホームページを見て回ることにしました。
はい、めんどくさいですね。
やめます。自動化を目指します。
Pythonを使って、ChatGPTさんに相談しながら、学長写真を集めるという作業を進めたいと思います。
私立大学のリストを取得する
今回は、作業を簡略化するために、弊学と同様に私立大学の学長の写真を集めることにしました。
一体全国に何校あるのでしょうか。
ナレッジステーションというサイトでは、大学の数を以下のように紹介しています。
大学数は810校。
国立大学は86校
公立大学は102校
私立大学は622校です。
ググりますと、進路情報サイトであるスタディサプリには605校が掲載されていました。しかしリストになっておらずコピーするのが面倒なので、別のサイトを探します。
日本私立大学協会には414校が加盟しているそうです。
このサイトには全体の7割ほどの大学が掲載されており、こちらはホームページに大学名と大学HPのリンクが一覧で掲載されていますので、ここから大学名を抜いていきます。
ChatGPTさん、お願いします。
import csv
import requests
from bs4 import BeautifulSoup
# WebページのURL
url = "https://www.shidaikyo.or.jp/apuji/member/sort.html"
# Webページの内容を取得
response = requests.get(url)
# WebページのエンコーディングをUTF-8に設定
response.encoding = "utf-8"
# BeautifulSoupを使ってHTMLを解析
soup = BeautifulSoup(response.text, "html.parser")
# 大学名とウェブサイトのURLを含む要素をすべて取得
university_elements = soup.find_all("a", class_="resultUni__uni")
# 大学名とURLを格納するリスト
universities = []
# 大学名とURLを抽出してリストに追加
for element in university_elements:
university_name = element.text.strip()
university_url = element["href"]
universities.append([university_name, university_url])
# CSVファイルに大学名とURLを書き込む
with open("universities.csv", "w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(["大学名", "URL"])
for university in universities:
writer.writerow(university)
print("CSVファイルに大学名とURLが保存されました。")はい、一瞬でuniversities.csvというファイルに大学名と大学HPのリンクが作成されました。
学長の写真はどこにある
大学のHP内を探索して学長の写真を探す、ということを検討したのですが、良いアイディアが浮かばず、うまくいきませんでした。
そこで、先ほど取得した大学名に「学長挨拶」というキーワードを加えてGoogle検索し、トップに表示されたリンクを取得する、という作業を考えました(主にChatGPTさんが)。
import csv
from googlesearch import search
# 大学名と学長挨拶を含めるキーワード
search_keywords = "学長挨拶"
# 大学名と学長挨拶を含めるキーワードを使ってGoogle検索を行い、検索結果のURLを取得
def search_urls(university_name):
query = f"{university_name} {search_keywords}"
urls = search(query, num=1, lang="jp")
return urls
# 入力となるCSVファイルと出力となるCSVファイルのパス
input_csv_file = "universities.csv"
output_csv_file = "gakucho.csv"
# 検索結果をCSVファイルに書き込む
with open(input_csv_file, "r", newline="", encoding="utf-8") as input_file, \
open(output_csv_file, "w", newline="", encoding="utf-8") as output_file:
reader = csv.reader(input_file)
writer = csv.writer(output_file)
# ヘッダー行の書き込み
writer.writerow(["大学名", "学長挨拶URL"])
# 大学名を読み取り、Google検索を行って結果をCSVに書き込む
for row in reader:
university_name = row[0]
try:
urls = search_urls(university_name)
gakucho_url = next(urls, "取得できず")
except Exception as e:
gakucho_url = "取得できず"
print(f"エラー: {university_name}の検索結果を取得できませんでした。")
print("エラー詳細:", e)
writer.writerow([university_name, gakucho_url])
print("検索が完了しました。結果は gakucho.csv に保存されました。")これにより、ほとんどの大学の学長挨拶のページを取得することができました。
写真を取ってくる
学長挨拶ページには大体、学長のアー写が載っています。
先ほど、学長挨拶ページのリンクを取得しましたので、それを使って、学長のアー写を抜いてくるようにChatGPTさんにお願いしました。
import requests
import os
import csv
from bs4 import BeautifulSoup
from urllib.parse import urlparse, urljoin
# 画像を保存するディレクトリのパス
output_directory = "/Desktop/gakujpg/"
# CSVファイルのパス
csv_file = '/Users/gakucho.csv'
# 画像をダウンロードする関数
def download_images(url):
try:
# URLから画像のファイル名を生成
image_filename = url.split('/')[-1]
# 画像の拡張子が.jpgでなければスキップ
if not image_filename.lower().endswith('.jpg'):
return
# 画像をダウンロード
image_data = requests.get(url).content
# 画像を保存
with open(os.path.join(output_directory, image_filename), 'wb') as f:
f.write(image_data)
print(f'Saved image: {image_filename}')
except Exception as e:
print(f'Error downloading image from {url}: {e}')
# CSVファイルからURLを読み取り、画像をダウンロード
with open(csv_file, newline='', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
url = row[1] # CSVファイルの2列目にURLがあると仮定
try:
# URLからHTMLを取得
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 画像のリンクを抽出してダウンロード
for img_tag in soup.find_all('img'):
img_src = img_tag.get('src')
if img_src:
# 相対URLを絶対URLに変換
img_url = urljoin(url, img_src)
# 画像をダウンロード
download_images(img_url)
except Exception as e:
print(f'Error processing URL {url}: {e}')ウェブサイトにはページの装飾画像のpngなどがたくさん貼られているので、jpgだけを抜いてくるように指示しました。しかし学長の写真以外にも、学生や校舎の風景などの画像も一緒に取得されていたので、それらは手作業で削除しました。
重複した写真も削除して、最終的に284枚の人物写真が取得できました。
この284枚のおじさんおばさんの写真が全て学長なのかは定かではありません(どうやら理事長も入っていたようです)。
しかし、大学のホームページに掲載されている偉そうな人の写真は一定数集めることができました。
写真を検証する

上記のような写真が集まりました。
(著作権とか肖像権とかで怒られそうなのでボカしています)
検証1:腕組み
私が気になったのは、学長が腕組みをしていることでした。
私個人の経験から、学長が腕組みをしている写真を見たことがなかったのと、あまりふさわしい写真ではないように感じたためです。
284枚の写真から、腕組みをしている写真は弊学学長を含め3枚ありました。
全体の1%です。全て男性でした。
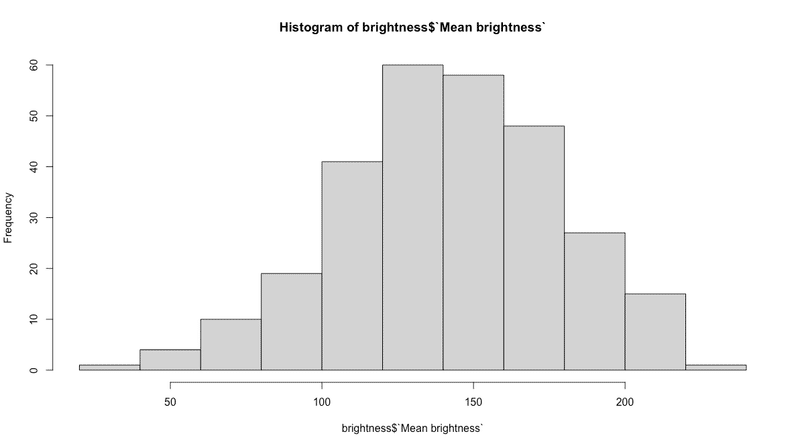
検証2:暗さ
次に気になったのは、写真の暗さです。
背景がダークな感じで、重厚感?威圧感がありますね。
他の写真はどうでしょうか。また定量的に比較は可能でしょうか。
写真の平均輝度を数値化することができます。
明るい写真の平均輝度は高く、暗い写真は低くなります。
それを用いて比較してみました。
PythonのOpenCVを使うと、画像の輝度を簡単に取得できます。
import cv2
def calculate_brightness(image_path):
# 画像をグレースケールで読み込む
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# 画素値の平均を計算
brightness = int(round(image.mean()))
return brightness
# 画像のパス
image_path = 'example.jpg'
# 画像の明るさを計算
brightness = calculate_brightness(image_path)
print(f'画像の明るさ: {brightness}')これを使って、284枚の写真の平均輝度を計算した結果です。
画像の平均輝度は最も明るいもので227、最も暗い画像では36となりました。(平均:142.8)。
弊学学長の画像の平均輝度は58で、284枚中下から4番目でした。
偏差値にすると26.6です。
今回集めた写真の中ではかなり暗い写真ということになります。
検証は以上です。
私立大学が622校だとして、今回は284人の写真データですので、半数に満たない不十分な検証であることを申し添えます。
参考:集合写真の作り方
284枚の写真を1枚のシートに載せたい。一つひとつサイズも違うし縦横の比率も違う。
なんとか楽に作業ができないか。探したら良い方法がありました。
Adobe PhotoshopのコンタクトシートIIという機能を使うことで、複数の写真を自動で任意のサイズのシートに並べてくれます。
この記事が気に入ったらサポートをしてみませんか?