
お試し!Amazon SageMaker(サンプルデプロイ編)- Trying Out SageMaker(Sample Model Deploy)

前回の記事(https://note.com/cute_dietes745/n/n6a67fc5ee3db)の続編です。前回の記事ではSageMaker Studioでサンプルコードを実行してモデルのトレーニングまで行いました。
今回はその続きの最終回、「モデルのデプロイ~リソースのクリーンアップ」までとなります。
本記事では前回の記事のコードが実行されている環境を前提としています。
はじめに
本記事の内容は以下の公式チュートリアルのうち、「Step 5: Deploy the Model to Amazon EC2」以降を実施したものになります。
実行するコードの内容については本記事でも補足していますが、詳細については開発者ガイドも併せて参照ください。
サンプルコードの実行
モデルをデプロイする
前回トレーニングしたモデルをAmazon EC2にデプロイします。
以下のコード実行することでモデルをホストするエンドポイント作成まで自動的に行われます。以降はこのエンドポイントにデータをリクエストすることでもモデルによる予測結果を取得することができます。
import sagemaker
from sagemaker.serializers import CSVSerializer
xgb_predictor=xgb_model.deploy(
initial_instance_count=1,
instance_type='ml.t2.medium',
serializer=CSVSerializer()
)
デプロイ後(数分かかります)は以下のコードでエンドポイント名を取得することができます。
xgb_predictor.endpoint_name
エンドポイントもSageMaker Studioコンソール画面から確認できます。
左側のメニューから「Endpoints」を選択すれば一覧で照会できます。

また、エンドポイントの詳細画面ではデプロイしたインスタンスの情報を確認できます。
「Test Inference」タブのGUIからエンドポイントのテストも行えます。
テストデータのリクエストを送信し、予測値を取得することができます。
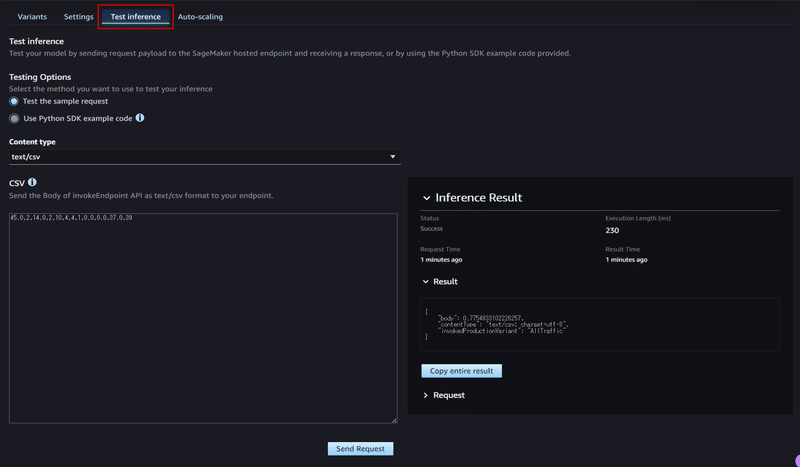
「Send Request」ボタンを押下すると推論結果が表示されます。JupyterLabでの予測値と比べるに、ResultのJSONのうちbodyに予測値が設定されているようです。
※GUIからは1行だけ送った場合に予測値が返却されました。複数行入力した場合は予測値が返却されないのですが、これがそもそも対応していないのかデータの書き方の問題なのか判断付きませんでした。
モデルを評価する
次に実際にトレーニングしたモデルを評価してみます。
※筆者が理解しきれていない部分も含まれていますので、より詳しく知りたい方は丁寧に解説されている他サイトを参照ください。
まずはテスト用データ(前回の記事参照)に対する予測の実行、そして予測値をグラフにプロットします。
import numpy as np
def predict(data, rows=1000):
split_array = np.array_split(data, int(data.shape[0] / float(rows) + 1))
predictions = ''
for array in split_array:
predictions = ','.join([predictions, xgb_predictor.predict(array).decode('utf-8')])
return np.fromstring(predictions[1:], sep=',')import matplotlib.pyplot as plt
predictions=predict(test.to_numpy()[:,1:])
plt.hist(predictions)
plt.show()
今回のサンプルでは国勢調査データに基づいて、収入が年間 50,000 ドルを超えるかどうかを予測するモデルを作成しています。
これは二項分類の問題で、予測したい値は1(True、超えている)または0(False、超えていない)となります。
グラフにプロットした予測結果から分かる通り、モデルの予測値は浮動小数点数になっています。ここにカットオフ値(閾値)を定めることで最終的な予測値に分類します。
サンプルではカットオフ値を0.5とし、Scikit-learnライブラリで混同行列(
confusion matrix)とその分類レポート(classification report)を出力しています。
まずは混同行列を出力します。
import sklearn
cutoff=0.5
print(sklearn.metrics.confusion_matrix(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0)))
混同行列は正解の値と予測値が一致していたのか、不一致だったのかを分類した行列になっています。
今回のデータでは以下のように表示されており、真陰性と真陽性(行列の左上と右下)の値が高いほど良好と判断できます。
真陰性(左上):予測値が0、正解値が0(正解)
偽陰性(左下):予測値が0、正解値が1(不正解)
偽陽性(右上):予測値が1、正解値が0(不正解)
真陽性(右下):予測値が1、正解値が1(正解)
次に分類レポートを出力します。
print(sklearn.metrics.classification_report(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0)))
分類レポートはモデルの評価に役立つ評価指標をまとめたものになります。今回のデータでは1または0のクラスに分類した結果について、以下の指標が出力されています。
Precision(適合率):予測値のうち、正解値と一致した割合。
Recall(再現率):予測したデータのうち、正しい予測ができた割合。
F1-Score(F1スコア):適合率と再現率の調和平均。1に近いほど良い性能であることが示されており、適合率と再現率をバランスよく評価する際に参照するそうです。
Support:各クラスのデータ件数。
またAccuracy(正解率)も併せて表示されており、それによると今回のモデルでは8割以上で正確に予測できていることができているようです。
混同行列とクラス分類レポートを出力することで現時点でのモデルの性能は見ることができました。
カットオフ値の探索
カットオフ値の最適化のためのサンプルコードも実行してみます。
先のコードでは決め打ちの値を使用していましたが、カットオフ値は予測の精度にもかかわるパラメータです。
各カットオフ値での予測値について、損失関数を使用して損失(正解値と予測値との差)を計算し、損失が最小となるカットオフ値を見つけます。
import matplotlib.pyplot as plt
cutoffs = np.arange(0.01, 1, 0.01)
log_loss = []
for c in cutoffs:
log_loss.append(
sklearn.metrics.log_loss(test.iloc[:, 0], np.where(predictions > c, 1, 0))
)
plt.figure(figsize=(15,10))
plt.plot(cutoffs, log_loss)
plt.xlabel("Cutoff")
plt.ylabel("Log loss")
plt.show()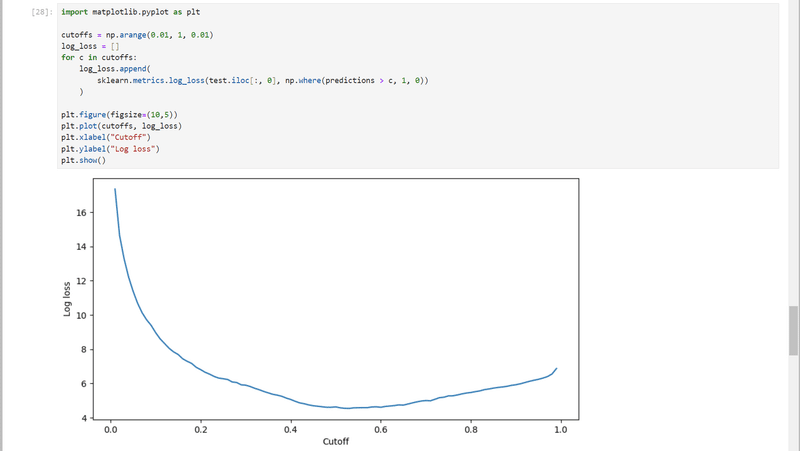
print(
'Log loss is minimized at a cutoff of ', cutoffs[np.argmin(log_loss)],
', and the log loss value at the minimum is ', np.min(log_loss)
)
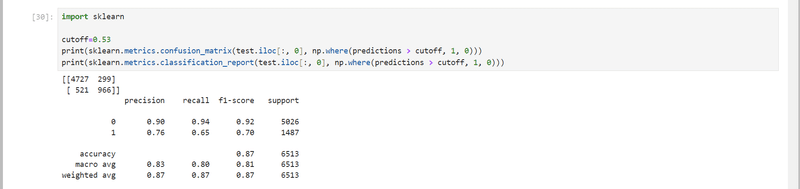
カットオフ値が探索できたので再度モデルを評価してみました。
大きな差は出ませんでしたが、一応カットオフ値を変更してみると真陰性と真陽性の件数が上がっているようです。
リソースのクリーンアップ
SageMakerのサンプルコードの実行はここまでとなります。
最後に作成したリソースのクリーンアップをお忘れなく!
まとめ
今回はサンプルコードを実行しただで、モデルのトレーニングや評価といった部分はまだまだ勉強が必要でした。
ひとまずはモデルのデプロイまでを行える環境を簡単に構築できるということは体験できてよかったなと思います。実際に業務で利用するのであればセキュリティの考慮やデータレイクの利用するなど他のAWSサービスとの連携も検討していく必要が出てくるかと思います。そういった部分も今後試していきたいと思います。
この記事が気に入ったらサポートをしてみませんか?