
お試し!Amazon SageMaker(サンプル実行編)- Trying Out SageMaker(Sample Code)

前回の記事で構築したSageMaker StudioからJupyter Labを使ってみます。
とはいえ筆者には機械学習の経験がないため、とりあえずAWSのユーザーガイドのサンプルコードを実行してみる、といった内容になります。
今回は「データ準備~モデルトレーニングの実行」までとなります。
はじめに
本記事では以下の開発者ガイドのサンプルコードを実行してみます。
実行するコードの内容については本記事でも補足していますが、詳細は開発者ガイドも併せて参照ください。
なお開発者ガイドの内容は実行環境としてSageMaker NoteBookインスタンスを前提とした内容となっているため、コードの実行のために必要な設定はは参考にする程度で進めています。
サンプル実行
ライブラリのインストール
まずはノートブック内でライブラリSHAPをインストールします。
このライブラリはゲーム理論的なアプローチにより「機械学習モデルの予測に対し、各入力特徴が予測結果にどのように影響したのか?」ということを解析するもののようです。
今回はライブラリに含まれる練習用のデータセットのみ使用します。
※以下のコマンドでインストールする場合、インスタンスが「ml.t3.midium」ではスペックが足りないようでした。
※コマンドについては記事下部の補足も参照ください。
%conda install -c conda-forge --solver classic --yes shapインストール後はカーネルのリスタートしておく必要があるようです。

サンプルコードの概要
データ準備編
データセットのロードする
データセットの分割する(トレーニング用、検証用、テスト用)
データセットをCSVに出力し、S3にアップロードする
モデルトレーニング編
パラメータの設定
トレーニングの実行
コードの実行(データ準備編)
それでは実際にコードを実行していきます。
コードは基本的に開発者ガイドに記載されたものをそのまま使用していますが、一部省略や変更を加えています。
SHAP の成人国勢調査データセット(adult)のロードします。
この国勢調査データに基づいて、収入が年間 50,000 ドルを超えるかどうかを予測するモデルを作成します。
データの説明は以下SHAPの公式ドキュメントを参照ください。
import shap
X, y = shap.datasets.adult()
X_display, y_display = shap.datasets.adult(display=True)
feature_names = list(X.columns)
feature_namesデータセットを分割します。
「トレーニング用」「検証用」「テスト用」の3つに分割していますが、「テスト用」はモデルの評価で使用するため本記事内では使用していません。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
X_train_display = X_display.loc[X_train.index]X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=1)
X_train_display = X_display.loc[X_train.index]
X_val_display = X_display.loc[X_val.index]分割したデータセットと正解のラベル(収入が年間 50,000 ドルを超えているか、いないのかの値)と合体させます。
import pandas as pd
train = pd.concat([pd.Series(y_train, index=X_train.index,
name='Income>50K', dtype=int), X_train], axis=1)
validation = pd.concat([pd.Series(y_val, index=X_val.index,
name='Income>50K', dtype=int), X_val], axis=1)
test = pd.concat([pd.Series(y_test, index=X_test.index,
name='Income>50K', dtype=int), X_test], axis=1)
実行結果を非表示にしていますが、期待通りであることを確認しています。
トレーニング用と検証用のデータセットをCSVファイルに変換してS3にアップロードします。
モデルをトレーニングする際はSageMakerのCreateTrainingJob APIを使用することになりますが、APIのリクエストパラメータを確認する限りではデータはS3やEFSなどの決められたサービスに保管しておく必要がありそうです。
train.to_csv('train.csv', index=False, header=False)
validation.to_csv('validation.csv', index=False, header=False)import sagemaker, boto3, os
bucket = sagemaker.Session().default_bucket()
prefix = "demo-sagemaker-xgboost-adult-income-prediction"
boto3.Session().resource('s3').Bucket(bucket).Object(
os.path.join(prefix, 'data/train.csv')).upload_file('train.csv')
boto3.Session().resource('s3').Bucket(bucket).Object(
os.path.join(prefix, 'data/validation.csv')).upload_file('validation.csv')正常にCSVファイルがアップロードされていることを確認します。
! aws s3 ls {bucket}/{prefix}/data --recursive
コードの実行(モデルトレーニング編)
サンプルコードではXGBoostアルゴリズムを使用します。
XGBoostは機械学習に広く使われているライブラリで、表形式のデータセットを扱った分類や回帰のような予測モデリング問題を得意としているそうです。
各種トレーニングに必要なパラメータを定義していきます。
import sagemaker
region = sagemaker.Session().boto_region_name
print("AWS Region: {}".format(region))
role = sagemaker.get_execution_role()
print("RoleArn: {}".format(role))from sagemaker.debugger import Rule, ProfilerRule, rule_configs
from sagemaker.session import TrainingInput
s3_output_location='s3://{}/{}/{}'.format(bucket, prefix, 'xgboost_model')
container=sagemaker.image_uris.retrieve("xgboost", region, "1.2-1")
print(container)
xgb_model=sagemaker.estimator.Estimator(
image_uri=container,
role=role,
instance_count=1,
instance_type='ml.m4.xlarge',
volume_size=5,
output_path=s3_output_location,
sagemaker_session=sagemaker.Session(),
rules=[
Rule.sagemaker(rule_configs.create_xgboost_report()),
ProfilerRule.sagemaker(rule_configs.ProfilerReport())
]
)xgb_model.set_hyperparameters(
max_depth = 5,
eta = 0.2,
gamma = 4,
min_child_weight = 6,
subsample = 0.7,
objective = "binary:logistic",
num_round = 1000
)モデルトレーニングを実行します。
トレーニング用、検証用のCSVファイルを与えます。
from sagemaker.session import TrainingInput
train_input = TrainingInput(
"s3://{}/{}/{}".format(bucket, prefix, "data/train.csv"), content_type="csv"
)
validation_input = TrainingInput(
"s3://{}/{}/{}".format(bucket, prefix, "data/validation.csv"), content_type="csv"
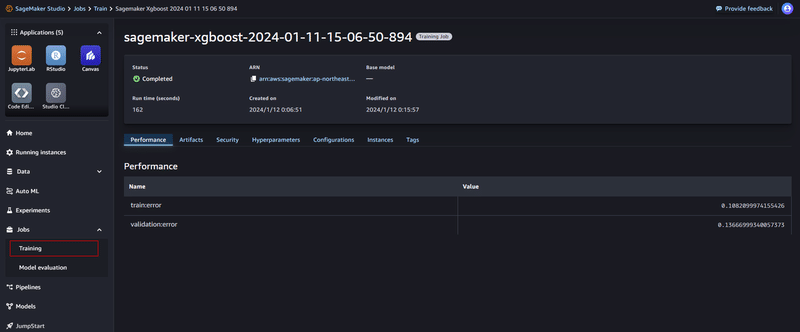
)xgb_model.fit({"train": train_input, "validation": validation_input}, wait=True)実行後数分でモデルトレーニングが完了し、ログに「Training job completed」が表示されたことを確認できました。

実行したモデルトレーニングのジョブの情報はSageMaker Studioの画面からも確認することができます。
使用したリソースや実行時間の詳細も記録されていますのでコスト観点でも見ておきたい部分です。
まとめ
今回モデルのトレーニングまでを実施してみて、簡単に機械学習を始められるんだなという印象を強く持ちました。
(サンプルコードを動かしただけで、データのラベリングなどの労力のかかる作業を一切していないのもありますが。。。)
SageMaker以外にもS3を使用したりする場面も出てくるため、ライフサイクルポリシーを検討してみたりなど環境面も整えていきたいです。
補足
conda installによるライブラリのインストールについて
少し調べる必要があったため、補足として残しておきます。
執筆時点(2024/01/10)で「conda install」を使用したライブラリのインストール時にエラーが発生しました。

Solving environment: failed
InvalidMatchSpec: Invalid spec 'conda-forge/linux-64::_libgcc_mutex==0.1=conda_forge[md5=d7c89558ba9fa0495403155b64376d81]': Libmamba only supports a subset of the MatchSpec interface for now. You can only use ('name', 'version', 'build', 'channel', 'subdir'), but you tried to use ('md5',).以下を参考にして「--solver classic」を付与することでとりあえずインストールできていますが、最新の状況は別途確認するようにしてください。
https://github.com/conda/conda-libmamba-solver/issues/418
「pip install」は特に問題ないようでしたので、本記事の内容であればこちらを使うのがよいかもしれません。
SageMaker SDKのログの抑制
ノートブック実行環境にインストールされているSageMaker SDKのバージョンがによってはかなりの頻度でINFOログが表示されます。
(バージョン2.183.0 以上で発生するという報告があるようです。)

sagemaker.config INFO - Not applying SDK defaults from location: /etc/xdg/sagemaker/config.yaml
sagemaker.config INFO - Not applying SDK defaults from location: /home/sagemaker-user/.config/sagemaker/config.yaml以下を参考にして設定変更することで、INFOログの出力を抑制できます。
https://github.com/aws/sagemaker-python-sdk/issues/4123
import logging
logging.getLogger("sagemaker.config").setLevel(logging.WARNING)この記事が気に入ったらサポートをしてみませんか?