
GAN(敵対的生成ネットワーク)とは

GANの種類や活用事例について解説します!
この記事を読んでいる方はAIについて調べており、その中でも「GAN」という単語を目にする機会が増えていると思います。
しかし、その仕組みや実際にどうやって活用されているのか知りたいと感じても、「私には難しそう」と敬遠してしまっている方も多いと思います。
そこで、今回の記事ではAIのネットワークであるGANについて、わかりやすく解説していきます!
GANとは
GANとは、「Generative Adversarial Network(敵対的生成ネットワーク)」と呼ばれるAIの一種です。
GANはデータから特徴を学習することで、実在しないデータを生成し、そのデータを存在するデータの特徴に沿って変換できます。
GANのネットワーク構造は、Generator(生成ネットワーク)とDiscriminator(識別ネットワーク)の2つのネットワークから構成されており、互いに競い合わせることで精度を高めていきます。
例えると、「偽物を作り出す悪い人(Generator)」と「本物かどうか見破る警察(Discriminator)」のような役割をネットワーク内に組み込み、競争させるような形で学習させます。
このお互いに競争させて学習させる形式から「敵対的生成ネットワーク」という名前が作られています。
このGANの一番の特徴は、教えるためのAIやデータを用いることなく(データのラベリングが不要)学習が可能になることです。
従来の深層学習(ディープラーニング)では、データのラベリングが必須でしたが、GANではその必要がなくなります。
一方、ラベリングが無いことによって学習が不安定になるので、学習を安定させる工夫を施したGANも存在します。
GANで何が出来るのか
GANの研究は日々進歩しており、様々な場面で使われています。
実際GANを使って何が出来るのかの一例をご紹介します。
①高品質の画像を作る
GANを使うことで、品質の低い画像から高品質の画像を作ることが出来ます。
例えば、ピンボケした写真や昔の写真の解像度を上げるなどといった活用法があります。
また、複数の顔の画像を取り入れることで、実際には存在しない人の画像を作ることも出来ます。(例PGGAN)
②文章から画像を起こす
絵の特徴を書いた文章から画像を生成することが出来ます。
例えば、「野原に寝そべっているライオン」と文章を打つと、その風景に沿った画像が生成されます。
また、さらに技術が発達すると音声による画像の修正というように、様々な場面での活用が期待されています。(例StackGAN)
③画像を別の画像に仕上げる
1つの画像から雰囲気の異なる別の画像を作ることができます。
ただの風景の画像からイラスト風の画像に変換したり、絵画作品のようなテイストの画像に変換したりすることが出来ます。(例CycleGAN)
④動画を別の動画に仕上げる
近年フェイクニュース等で話題になっている技術ディープフェイクにもGANが使われています。
ある人の動画に別の人の顔を載せたり、別人の2人の動きをシンクロさせたりすることができます。
ディープフェイク技術については詳細を別記事で解説していますので、是非こちらもご覧ください。
>> ディープフェイクとは?実例を含めてわかりやすく解説!
GANの種類
GANは画期的な技術ですが、生成や学習の仕方が通常のオリジナルGANは動作が不安定になりやすいといった欠点があります。
そのため、不安定になった動作を解決するために様々な種類のGANが開発されています。
以下図内での略称
G:Generator D:Discriminator z:ノイズベクトル y:条件ベクトル G(z):Generatorが生成した偽のデータ
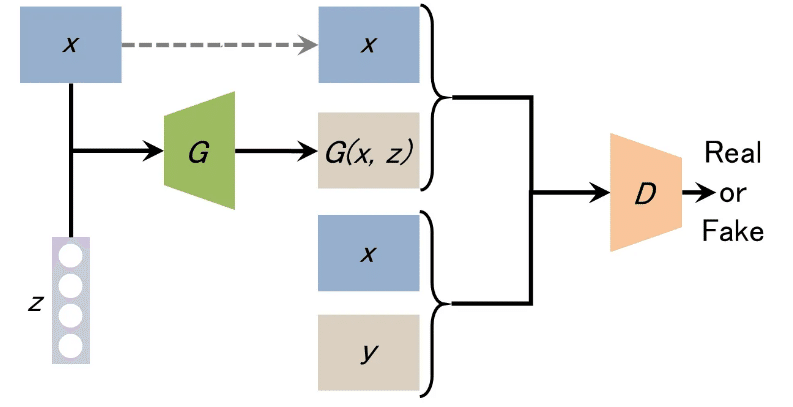
pix2pix
条件画像と画像のペアから画像同士の関係を学習することで、1枚の画像から学習したペアの画像関係を補完した画像を生成することが出来ます。
またpix2pix は汎用性の高い画像生成アルゴリズムであり、問題ごとにネットワークを設計する必要がないというのも特徴です。
論文:https://arxiv.org/pdf/1611.07004.pdf
♦pix2pixの特徴
航空写真から地図の作成、白黒画像からカラー画像の生成、昼の風景から夜の風景の生成など多種多様な画像生成に用いられています。
主に地理情報分野における活用が期待されており、地図から衛星画像へ、衛星画像から地図への変換においても実施事例として紹介されています。
土地利用や地すべりなどの予測に用いられた事例もあり、今後土地の有効活用や災害などの予測などで活躍することが期待されます。
ネットワーク構造
CGAN (Conditional GAN):条件付き敵対的生成ネットワーク
生成画像

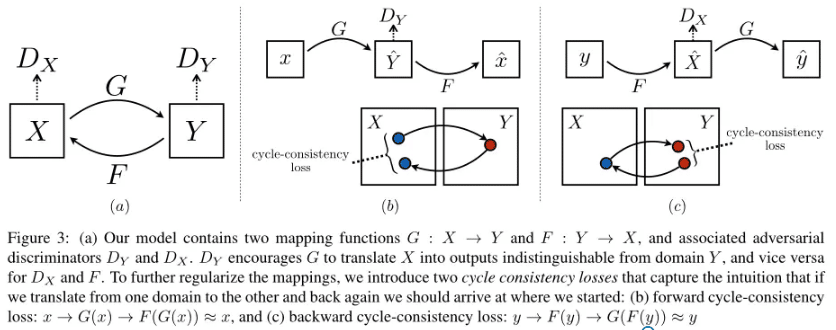
CycleGAN
2組の画像を使い、一方の画像から他方の画像を生成し、他方の画像から一方の画像に戻した時に(サイクルした時に)精度が高くなるように学習させます。
訓練データとして二つの画像群を与え、ウマ →→ シマウマ、
景観写真 →→ モネの絵画というような写像を学習し、一方からもう一方へ自動的に変換が行えるようにしました。
参照:https://arxiv.org/pdf/1703.10593.pdf
CycleGANの特徴
画像から画像への変換をすることが出来ます。またpix2pixと異なる点は、pix2pixは(下図(b)部分)しか行わないのに対し、画像を元に戻す作業(下図(c)部分)も行っていることによって、両方向の変換作業が行えるという点です。これによって、pix2pixは輪郭がピッタリ合っているようなペア画像のみ変換可能なのに対して、CycleGANは厳密なペアでなくても、柔軟に変換可能です。さらに両方向の変換を学習させたい時はCycleGANを使うことでpix2pixの半分程度の時間で学習させることが出来ます。
ネットワーク構造
生成画像

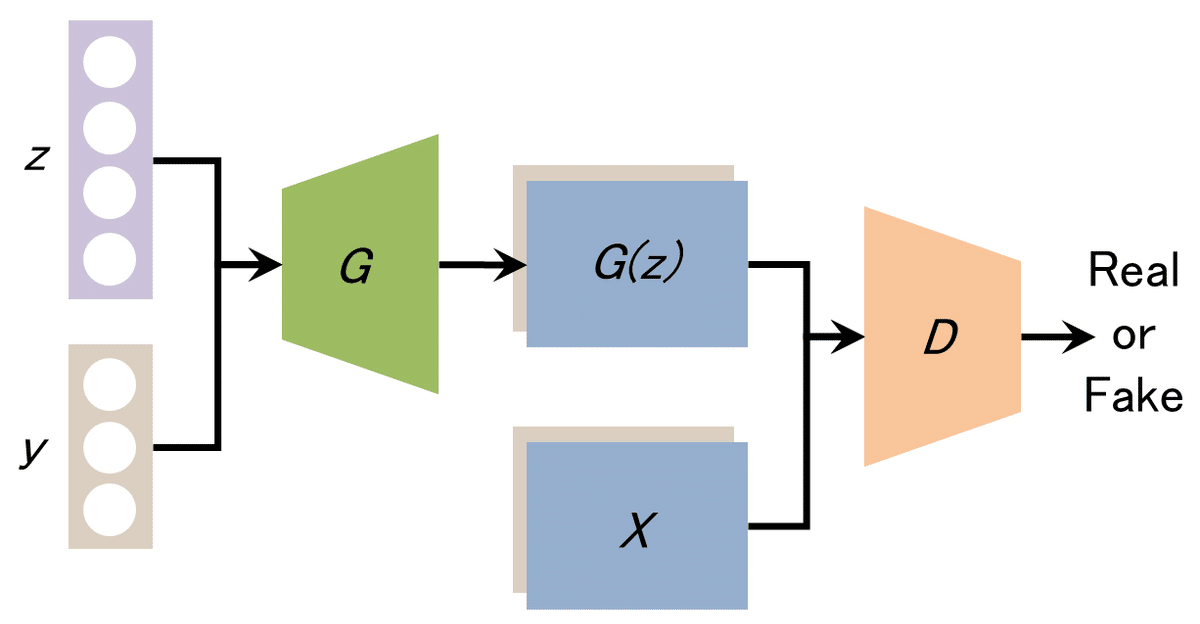
CGAN (Conditional GAN)
条件付きGANと呼ばれ、生成器と識別機に画像データに加えて追加の情報を与えることで、生成する画像に条件を付けるように訓練を行うGANの事を指します。
論文:https://arxiv.org/pdf/1411.1784.pdf
CGANの特徴
通常のGANとは異なり、指定した条件にマッチした画像を生成することが出来ます。
例えば、0〜9の数字を生成するように学習すると、「数字の3を生成」といったように生成させたい画像を指定できるわけです。
ネットワーク構造
生成画像

DCGAN (Deep Convolutional GAN)
GANに比べて高解像度であり、学習も安定化されました。
GANではぼやけていた画像を自然な形で生成したり、よりシンプルな画像を生成することが出来ます。
DCGANはこれまであまり注意の向けられていなかった教師なし学習にCNNを用いて取り組む有力な候補であり、新しいタスクに対して学習した特徴量を適用します。
論文:https://arxiv.org/pdf/1511.06434.pdf
DCGANの特徴
DCGANは広い意味でCGANの一種であり、オリジナルGANとの大きな違いは、generatorとDiscriminatorそれぞれのネットワークに全結合層ではなく、畳み込み層と転置畳み込み層を使用している点です。
畳み込みとは、2つの情報源が組み合わさった系統的な手法で、ある関数を別のものに変える操作です。
一般的に、畳み込みは画像をぼかしたり鮮明にしたりする効果を得るための画像処理です。
逆畳み込みとは、畳み込みの逆プロセスではなく、入力データを拡大するためにデータを補完してから畳み込みを行うことです。
ネットワーク構造
生成画像

PGGAN (Progressive Growing GAN)
PGGANもDCGAN同様に畳み込み層、転置畳み込み層を使っており、段階的な学習によってDCGANより高解像度の画像を生成することができるようになりました。
GANは生成する分布(画像など)の解像度が高くなるに連れてランダム要素の影響が色濃くなり、DiscriminatorはGeneratorの生成分布と教師データを区別することが容易になってしまい、ネットワーク全体の学習が不安定になります。
このように、GANは高解像度の画像を出力することが難しいという問題があります。
そこでPGGANは段階的にネットワーク層を増加させ、高解像度を実現しています。
論文:https://arxiv.org/pdf/1710.10196.pdf
PGGANの特徴
PGGANとDCGANの大きく違う点は、以下の図のように、段階的に学習データの解像度を上げて行き、これに合わせてGeneratorとDiscriminatorのネットワークもその対象構造を保ったまま層を追加して解像度を上げて行くことです。
これにより、1024×1024解像度まで生成することができるようになりました。
生成画像

BigGAN
PGGAN同様、BigGANも高解像度の画像を生成することが出来ます。
GANは一般的に学習が不安定であり、高品質な画像出力が難しかったのですが、BigGANはネットワークを大規模化することでそれを可能にしました。
論文:https://arxiv.org/pdf/1809.11096.pdf
BigGANの特徴
BigGANは最大512×512ピクセルの高解像度画像を条件付きで生成するモデルで1000カテゴリーの画像を生成することが出来ます。またBigGANはジェネレータに直行正規化を用いており、これによりInceptionスコアが大幅に改善しました。
Inceptionスコアとは識別ネットワークの識別容易性と生成画像の多様性というふたつの観点を考慮した指標です。つまり、GeneratorとDiscriminatorの能力が上がり、より高品質な画像生成ができるようになりました。
BigGANでは直交正則化のほかにも、CNNの学習効率を上げる手法のひとつであるSkip connectionが使われています。
StyleGAN
PGGAN同様に、段階的に解像度を上げていく手法を採用することで、本物と区別がつかないような画像を生成することが出来ます。StyleGanは、高レベルな属性を教師なしで分離し、 生成画像に確率的な変動(例、そばかす、髪など)を含めることを可能にしました。
また学習したデータの特徴を元に実在しないデータを生成したり、データを変換したりすることができ、『写真が証拠になる時代が終わる』なんてことが起こるかもしれません。
論文:https://arxiv.org/pdf/1812.04948.pdf
StyleGANの特徴
StyleGANはMapping networkとSynthesis networkの2つのネットワークで構成されています。またStyleGANでは高解像度な画像を生成するためにprogressive growing[6]というアプローチをとっています。progressive growingとは、GANの学習過程において、低解像度の学習から始め、モデルに徐々に高い解像度に対応した層を加えながら学習を進めることで高解像度画像の生成を可能にするというものです。例えば初めに4×4の学習から始め、次に8×8の層を追加というように学習を進めていくことで最終的に1024×1024の画像を生成しています。
ネットワーク構造
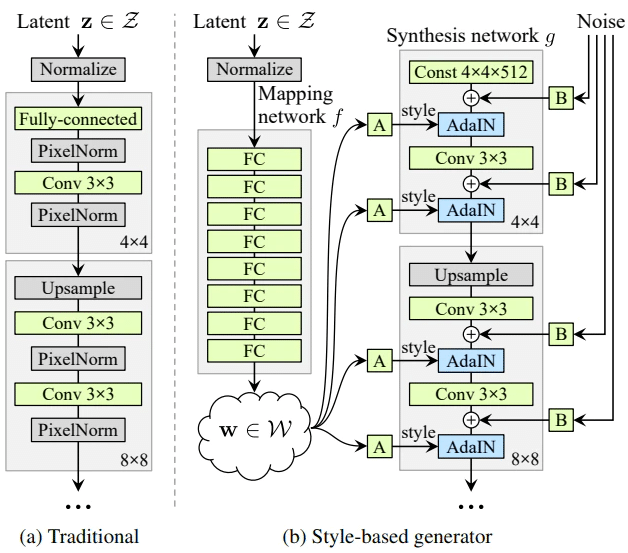
↑左の図がこれまでのGAN(PG-GAN)、右の図がStyleGANです。
StyleGANでは以下のように本物と区別がつかないような画像を生成することが出来ます。
生成画像

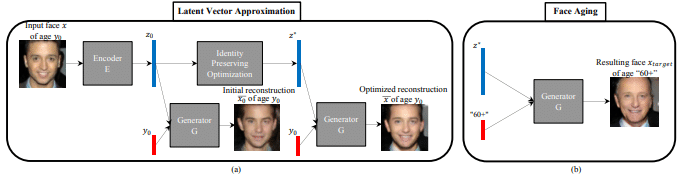
AGE-cGAN
年齢別で高品質な顔画像を生成できる技術です。
論文:https://arxiv.org/pdf/1702.01983.pdf
AGE-cGANの特徴
顔の属性を変更するためにGANを採用した従来の研究とは異なり、元の画像の顔の違うバージョンの画像を生成するのが特徴です。
これを用いると、自身の顔の画像を若返らせたり、老いさせたりすることが出来ます。
年齢を横断する顔認識、迷子の捜索、そしてエンターテインメントを含む様々な産業で活用事例があります。スマホのカメラアプリなどではこの技術が使われています。
ネットワーク構造
生成画像

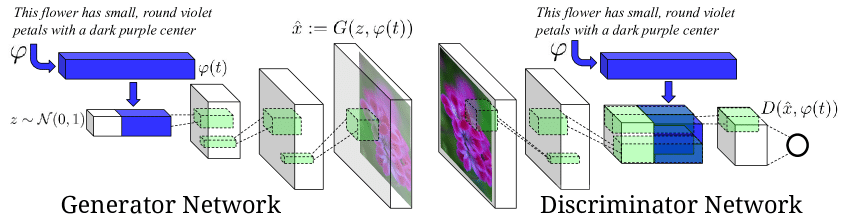
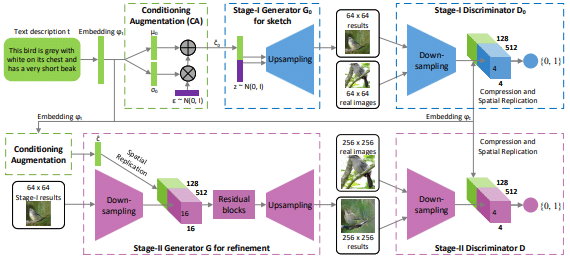
StackGAN
文章から画像を生成することが出来ます。
文章から画像を生成するネットワークと生成された画像を高精度にするネットワークの2つのGANで構成されています。
字の意味を反映した大まかな画像を生成することには成功していましたが、詳細な部分の表現や物体の要素については表現できない問題がありました。
しかし、StackGANを用いることで画像の精度を向上させることが出来ました。
論文:https://arxiv.org/pdf/1612.03242.pd
StackGANの特徴
GANを多段構成にすることによって、最初のステージのGANで大枠をとらえた低解像度な画像を生成し、以降のステージのGANでより高解像度な画像を生成することで画像の精度を向上させています。
ネットワーク構造
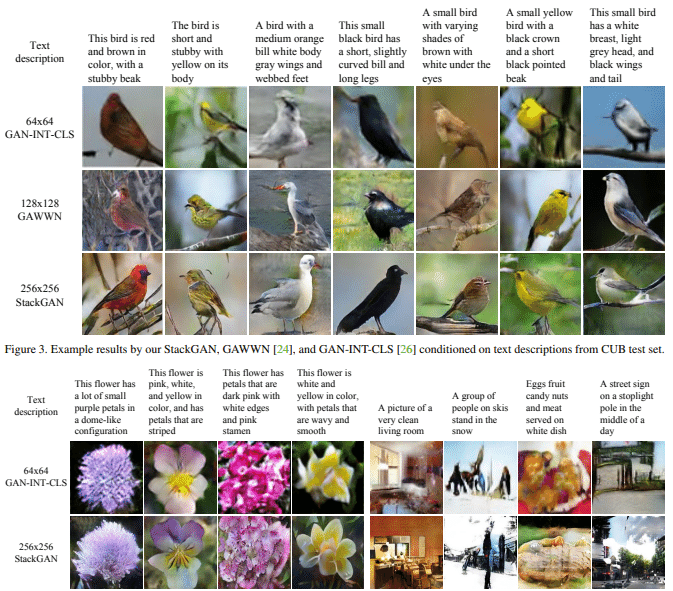
入力文字と生成画像
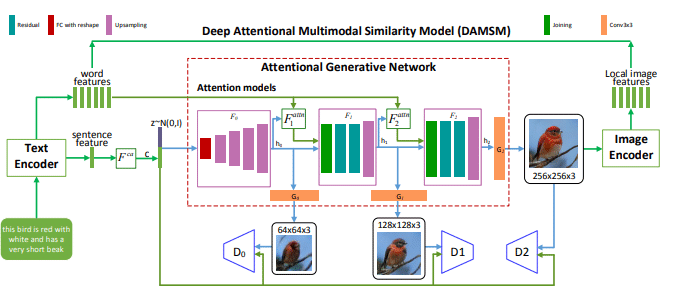
AttnGAN
StackGAN同様、AttnGANも文章から画像を生成することが出来ます。StackGANとの違いは、より細部までの詳細な表現力を持つtext-to-image生成モデルの実現したことです。
自然言語から画像を自動生成することは、多くの芸術や設計におけるコンピュータ支援の分野での大きな課題となっており、 近年ではtext-to-imageにGANを用いた生成モデルが活発に研究されています。
text-to-imageでは文章全体をベクトルに変換し、そのベクトルを使用して画像を生成するものが一般的です。
このような手法では表現力豊かな画像を得ることができる一方で、入力となる文全体のベクトルからは単語レベルの細かい粒度の情報が抜け落ち、詳細な画像の生成は未だ難しいのが現状の中、AtnnGANがこの課題解決の一助となっています。
論文:https://arxiv.org/pdf/1711.10485.pdf
AtnnGANの特徴
AttnGANは、新しい生成ネットワークを使用して、画像のキャプションのようなテキストによる描写の個々の単語に注意を払うことにより、画像のさまざまなサブ領域で詳細を合成できます。
その結果従来のテキストから画像を描く技術と比較して画質がほぼ3倍に向上しました。
AttnGANの生成する画像はまだ不完全ではありますが、将来的には画家やインテリアデザイナーのアシスタント、音声による写真修正、さらには脚本から直接アニメ映画を作ることも可能になるかもしれません。
ネットワーク構造
生成画像

GANの活用事例
GANの実際の活用事例として、3つ紹介します。
医療分野での画像解析
GANは、医療画像の解析や生成に活用されています。
例えば、低解像度の医療画像を高解像度に変換することで、病変の検出精度を向上させることができます。
また、GANを用いて生成された合成画像は、機械学習のデータ不足を補うためのトレーニングデータとして利用されることもあります。
自動車産業での自動運転技術
自動運転車の開発において、GANはシミュレーション環境の構築に利用されています。例えば、実際の道路状況を模倣した高精度なシミュレーション画像を生成することで、自動運転アルゴリズムのトレーニングに役立てられています。
エンターテインメント分野でのコンテンツ生成
GANは、映画やゲームなどのエンターテインメント分野でも活用されています。
例えば、映画の特殊効果やキャラクターの生成、ゲームの背景やキャラクターの自動生成などに利用されています。
まとめ
今回はGANとは?という疑問の回答から、どのようなことができるのか、そして様々な種類のGANを紹介してきました。GANはさまざまな種類があり、様々な用途で利用できるのがわかったと思います。
しかし、GANもメリットだけではありません。
例えば、ウクライナ紛争で話題に上がったゼレンスキー大統領のディープフェイク動画にもGANが利用されています。
私達ユーザは、この便利な技術”GAN”をどのように使うのか、十分な注意を払う必要があります。
この記事が気に入ったらサポートをしてみませんか?