
第二弾:Pyspark 問題集(基礎編)

こんにちは。コグラフSSD−2事業部の安山です。
データサイエンスの世界では、大規模なデータセットを扱う能力が不可欠です。その中核をなすのが、Apache SparkとそのPythonインターフェイスであるPySparkです。PySparkは、ビッグデータ処理における強力なツールであり、データ分析、機械学習、リアルタイムデータストリーミングなど、多岐にわたる用途に利用されています。
PySparkを使った具体的なデータ処理の例と解答例を示し、理解を深めることができるように設計しました。
アウトプットをしながら楽しんで取り組んでください!
環境
GoogleのColaboratoryで実行できるようになっています。
事前準備
csvファイルをダウンロードしてください。
インストール関連
!pip install pyspark
!pip install findspark
!pip install pyarrow
!pip install xlrd
!pip install openpyxl
!pip install chardetfrom pyspark.sql import SparkSession
from pyspark.sql.types import StringType, StructType, StructField
import pyspark.sql.functions as fn
from pyspark.sql.functions import col, lit
import pandas as pdcsvファイルの判定
環境によっては文字化けを起こす可能性があるので、こちらを使用し判定して、読み込む際に活用してください。
import chardet
def detect_encoding(file_path):
with open(file_path, 'rb') as file:
result = chardet.detect(file.read(10000))
return result['encoding']
file_name = 'order_history.csv' # CSVファイル名(別の階層にある場合はパス)
encoding = detect_encoding(file_name)
print(f"Detected encoding: {encoding}")DataFrameの作成
member_sdf = spark.read.format("csv").option("header", "true").option("encoding", "ascii").load("members.csv")
product_sdf = spark.read.format("csv").option("header", "true").option("encoding", "utf-8").load("products.csv")
order_sdf = spark.read.format("csv").option("header", "true").option("encoding", "ascii").load("order_history.csv")出力裏技
おそらくsparkDataFramは綺麗に出力されないと思います。綺麗に出力をしたい方は、少し面倒ですが下の手順を毎回実行してみてください。
sparkDataFram = hogehoge...
display(sparkDataFrame.toPandas())上記のようにsparkDataFrameをPandasDataFrameへと変換をし、displayで表示させてみてください。
綺麗に表示されます。

問題
問1 注文履歴(order_sdf)からもっとも多く来店したIDを特定する。
Q1_answer_sdf = order_sdf.groupBy(
"member_id"
).agg(
fn.countDistinct("purchase_time").alias("times")
).orderBy(
col("times").desc()
)
display(Q1_answer_sdf.toPandas())答えはcograph_118となります。「来店数が最も多いID」を特定するには「IDごとの来店回数」が分かれば求めることができます。よって、まずはそれぞれのIDの来店回数を算出します。その後、どのような方法でもいいですが、ソートなどを行い「来店数が最も多いID」を求めます。
問1の派生編
来店数が多い10人のリストを作成する。
top_10_list = [row[0] for row in Q1_answer_sdf.select("member_id").collect()][:10]collect()という関数を使用すると、1レコード(Rowオブジェクト)ごとにリストに格納されます。
Q1_answer_sdf.select("member_id").collect()
Row(member_id='cograph_188')の「'cograph_188'」を取得するように内包表記を利用してリストを作成します。
top_10_list = []
for id in Q1_answer_sdf.select("member_id").collect()[:10]:
top_10_list.append(id[0])
top_10_list上記のような書き方でもリストの作成は可能です。
問2 日付ごとの来店ID数を求める。
色々な方法はありますが、今回は年月日のカラムをそれぞれ作成してみましょう。
order_sdf_with_ymdcols = order_sdf.withColumn(
"y", fn.substring(col("purchase_time"), 1, 4)
).withColumn(
"m", fn.substring(col("purchase_time"), 6, 2)
).withColumn(
"d", fn.substring(col("purchase_time"), 9, 2)
)
display(order_sdf_with_ymdcols.toPandas())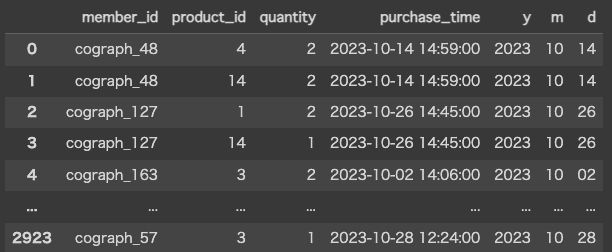
withColumn()はカラムを付け加えることができます。読み込んだままのDataFrameにはないカラムを付け加えることによって、データフレームの操作性が向上するかもしれません。
ここまでくると、お馴染みの日付ごとなのでgroupBy()を使って集計をしていきます。
Q2_answer_sdf = order_sdf_with_ymdcols.groupBy(
"y", "m", "d"
).agg(
fn.countDistinct("member_id").alias("cnt_uu")
).orderBy("y", "m", "d")
display(Q2_answer_sdf.toPandas())※aliasで指定しているcnt_uuはcount unique userの略称です。重複なしでユーザーを数えた場合の数になります。

問2 別解 substring編
order_sdf.groupBy(
fn.substring("purchase_time", 1, 4).alias("year"),
fn.substring("purchase_time", 6, 2).alias("month"),
fn.substring("purchase_time", 9, 2).alias("day"),
).agg(
fn.countDistinct("member_id")
).orderBy("year", "month", "day").show()上記のようなコードで直接groupByの中でカラムのようなものを一時的に作成する方法もあります。
substring関数は、はsubstring(カラム名, 切り取りたい部分のスタート位置, 取得文字数)で切り取りたい範囲を指定することができます。
問2 別解 split編
order_sdf.groupBy(
fn.split("purchase_time","-")[0].alias("year"),
fn.split("purchase_time","-")[1].alias("month"),
fn.split(fn.split("purchase_time","-")[2], " ")[0].alias("day"),
).agg(
fn.countDistinct("member_id")
).orderBy("year", "month", "day").show()split関数は、split(カラム名, 分割する際の文字)で文字列を分割することができます。
2024年9月29日15時20分00秒を表す"2024-09-29 15:20:00" を"-"で分割します。
["2024", "09", "29 15:20:00"]のように三つの要素を持つリストになります。
年を取得したければリストの0番目を指定します。
このように年月日をそれぞれ取得すればいいわけですが、今回の問題ではリストの3番目には日情報だけではなく時間の情報も含まれてしまっています。
なので、①purchase_timeを「” ”」空白で分割し、0番目を取得、②取り出した要素を「”-”」で再度分割し2番目を取得します。そうすることによってday情報を他の情報を含まずに取得することができます。
イメージ!!
"2024-09-29 15:20:00"
↓ ①空白で分割
["2024-09-29", "15:20:00"]
↓ ①0番目の要素を指定
"2024-09-29"
↓ ②”-”で分割
["2024", "09", "29"]
↓ ②2番目の要素取得
"29"
このような流れで29日という情報を抽出することができます!終わりに
この問題集を通じて、PySparkにおける、groupByなどの基本的・応用的な操作についての理解を深めることができたでしょうか。その他にも実務でよく使われるような関数を幾つか紹介しましたが、その他にも多くの有用な関数があります。例えば、window関数を使用することで、データセット内のグループに対して複雑な計算を行うことができます。また、pivot関数を用いることで、データの再構成を行い、分析に適した形へと変換することが可能です。さらに、join操作により、複数のデータフレームを結合し、より豊富な情報を含むデータセットを構築することができます。これにより、異なるデータソースからの情報を統合し、深い洞察を得ることが可能になります。
第三弾も公開予定です!
この記事が気に入ったらサポートをしてみませんか?