
SAS-Python書き換えメモ ~SASと向き合うことになった貴方へ~

こんにちは。コグラフ株式会社データアナリティクス事業部のワダです。今度からSASを主に使用する案件への参画が決まり、未経験の状態からキャッチアップすることになりました。
この記事ではSAS言語の基本構成とデータ操作、分析の流れを紹介し、Pythonで記述する場合の書き換え例も併記します(Google Colaboratory上での実装を想定)。
私のようなPython、SQL知識が少しある人がスムーズにSAS言語をインプットする最初の足掛かりになる、そんな記事を目指します。
SASを無料で使う
SASとは
SAS Institute社が開発した統計解析ソフトウェアであり、主に金融、医療(製薬、治験等)業界でよく利用されている製品です。SAS言語という独自のプログラミング言語で分析手順を指示し、解析を行います。1970年代から大学や研究所等研究機関で用いられ、歴史のある製品、言語と言えます。
SAS® OnDemand for Academics
SASは本来非常に高価なソフトウェアですが、無償版もあります。SAS® OnDemand for Academicsは教授・教員、学生、個人の学習者かを問わず、教育・学習を目的とすれば誰でも利用が可能です。ブラウザ上で動きます。
ぜひ下記リンクにアクセスして使用してみましょう。本記事はこの無償版を使ってSASを実装します。
SASの基本構成
データセットとライブラリ
SASには「データセット」「ライブラリ」という用語があります。データセットはデータの集合体、そのデータセットが置いてある領域をライブラリと呼びます。「データセット」はSQLでいうテーブルの集合、「ライブラリ」はスキーマのようなものという理解です。
「ライブラリ」は「一時ライブラリ」と「永久ライブラリ」の2種類あり、「一時ライブラリ」はSAS起動中のみ保持されます。
SAS言語の構成要素
SAS言語は以下3つの要素に分かれています。
グローバルステートメント(ライブラリ定義、変数定義等)
SAS起動中に適用する設定の変更や追加を行います。ライブラリや変数の定義をここで行います。DATAステップ(データの読み込み)
データソースからデータを読み込んでSASデータセットを作成、データ加工を行います。CSVファイル等の読み込みを行うこともできます。PROCステップ(データの集計・分析)
DATAステップで読み込んだデータセットを用いた集計・分析を行います。集計やグラフの作成に加え、SASの得意な多種の統計解析手法を実装することができます。
SASで統計分析をしてみよう with Pythonコード
有名なIrisデータセットを用いて、SAS上でのライブラリ定義~分析の一連の流れをご紹介します。CSVは下記サイトより拝借しました。
CSV読み込み~テーブル作成
CSVファイル等の外部ファイルをSAS内で使用するにはSASテーブルという形式に変換する必要があります。
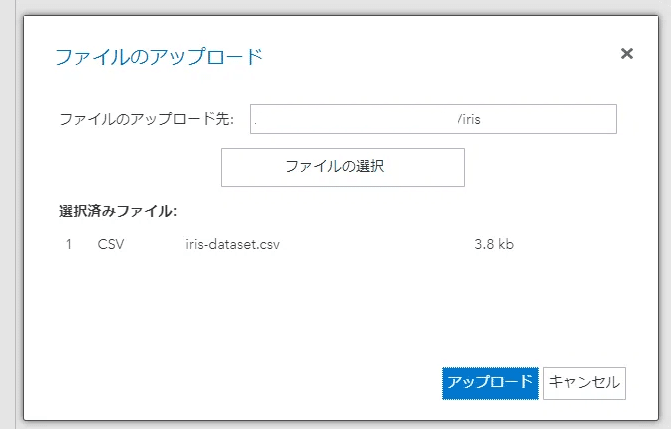
画面左のファイルとフォルダエリアにirisフォルダを新規作成し、今回使用するCSVをアップロードします。PCのファイルエクスプローラと同様に操作できます。
ここからデータの読み込みに関するコードを記述します。
※SAS言語の文字列は「ステートメント」と呼ばれ、処理の指示や情報の指定を行います。ステートメントの最後には必ず「;」を付けないといけません。
/* データを読み込む */
data iris;
infile '/要pass変更/iris-dataset.csv' dlm=',' firstobs=2;
input Sepal_Length Sepal_Width Petal_Length Petal_Width species $;
run;同CSVをPython pandasデータフレームで読み込む際のコードも併記します。SASと比較すると区切り文字、読み込み開始行、カラム名の指定が不要でシンプルです。
import pandas as pd
iris = pd.read_csv('要pass変更/iris-dataset.csv')1行目
data「iris」というテーブルを作成 という宣言をします
2行目
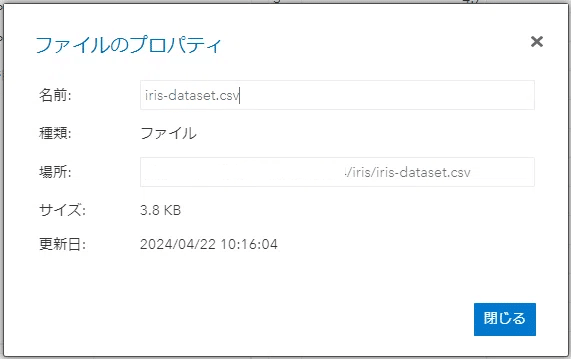
infile 読み込むCSVのパスを指定します。パスの確認方法はファイルとフォルダエリアでCSVファイルのプロパティを開けばOKです。
dlm データ区切り文字の指定 今回は「,」を指定します。
firstobs データの読み込み開始行の指定 今回のCSVは1行目にカラム名が入っているので「2」を指定します。指定しないとSASは1行目から読み込みます。
3行目
input 各列の定義 カラム名の定義を行います。CSVの並び順通りにカラム名を直接入力します。文字列型のカラムの場合はカラム名の後ろにスペースをあけ、「$」をつけます。
重要:SASの命令規則
列名の長さは1~32文字
列名の先頭文字は英字かアンダースコアのみ
空白文字は列名に使用できない
英字は大文字小文字混在で指定できる
出力レポートには大文字小文字が区別して表示される
コーディング時には区別なし
4行目
run それまでに入力されたステートメントを実行するという意味です。
上記を実行するとirisのCSVを読み込み、SASテーブルが作成されます。
実行はF3キーか、RUNマークをクリックします。

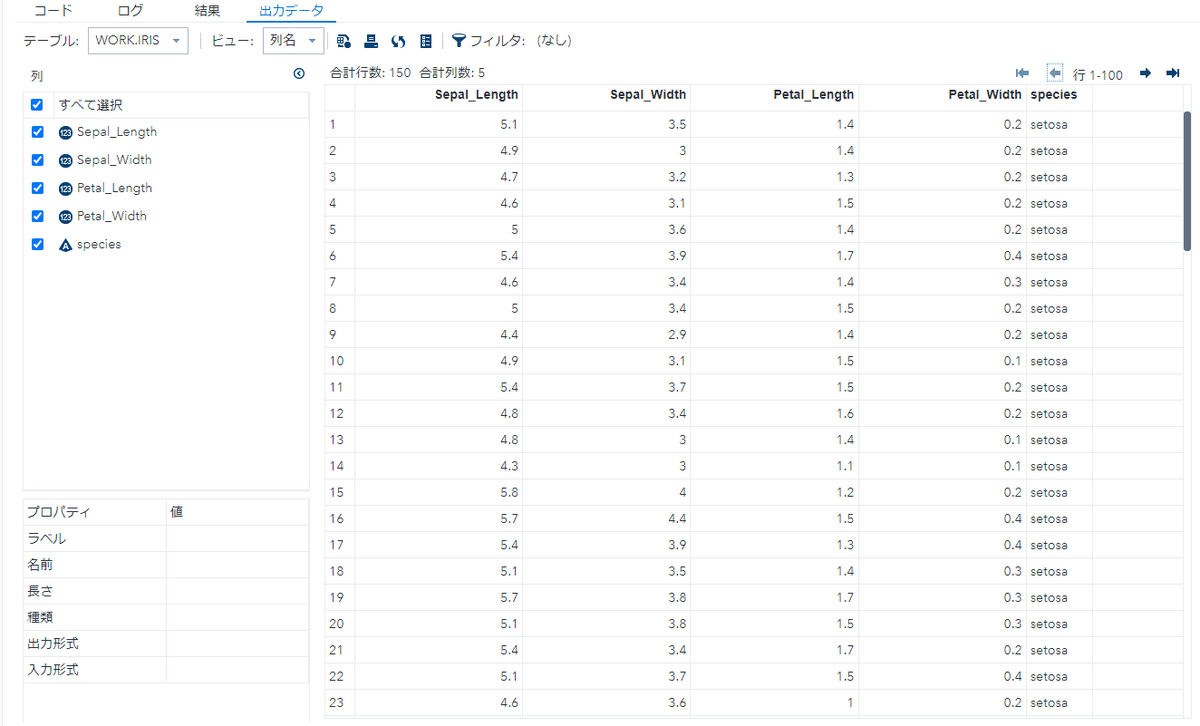
「WORK」内に作成されています
グラフの作成
ここから作成したSASテーブルを用いて簡単なグラフを作成します。
Irisデータセットを用いているので散布図の作成をしてみましょう。
画面左部「タスクとユーティリティ」メニューから散布図を選択します。
データセットをメニューから読み込みましょう。「WORK」内「Iris」を選択します。
X軸、Y軸、グループを指定できるので「Sepal_Length」「Sepal_Width」「species」をそれぞれ指定します。するとコードが生成されます。
生成されたコードは以下の通りです。
proc sgplot data=WORK.IRIS;
scatter x=Sepal_Length y=Sepal_Width / group=species;
xaxis grid;
yaxis grid;
run;Python上でseabornを用いた例も併記します
import seaborn as sns
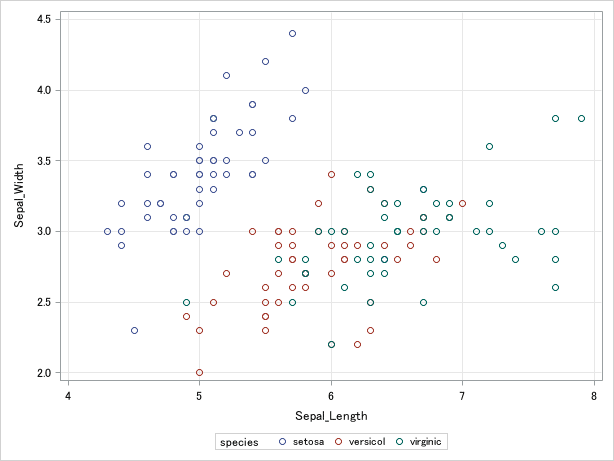
sns.scatterplot(x=iris['sepal_length'], y=iris['sepal_width'], hue=iris['species'])実行すると散布図が表示されます
「表示」メニューからグラフのオプションを選択可能です。今回は回帰直線とタイトルを追加してみましょう。

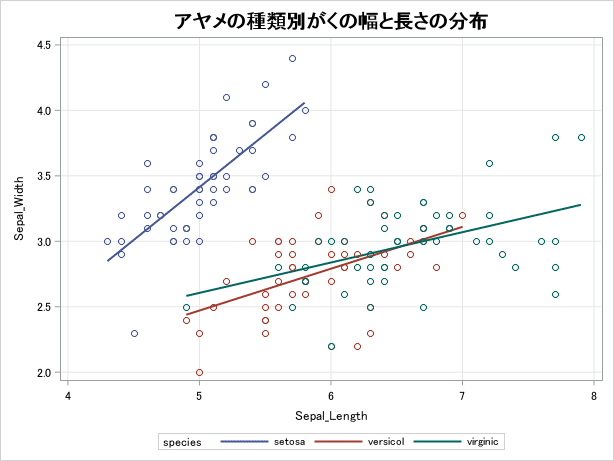
setosaと他2種の大きさがはっきり違うことが確認できます
相関分析
SASの本領を発揮する統計解析の機能についてもご紹介します。
まずは相関分析を行います。
先ほどの散布図作成と同様に「タスクとユーティリティ」メニュー内「統計量」「相関分析」を選択します。
今回は「Sepal_Length」と他3カラムとの相関を見るために、各項目に指定を行います。オプションで散布図をプロットするようにも設定しました。

生成されたコードを併記します。
proc corr data=WORK.IRIS pearson nosimple noprob plots=matrix(histogram);
var Sepal_Width Petal_Length Petal_Width;
with Sepal_Length;
run;Pythonで同内容を出力する場合は以下の例が挙げられます
#SASと出力を合わせるため1行目のみ表示
corr = iris.drop(columns='species').corr().head(1)
print(corr)
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(15,5))
ax1 = fig.add_subplot(1,3,1)
ax2 = fig.add_subplot(1,3,2)
ax3 = fig.add_subplot(1,3,3)
ax1.scatter(iris['sepal_width'],iris['sepal_length'])
ax1.set_xlabel('sepal_width')
ax1.set_ylabel('sepal_length')
ax2.scatter(iris['petal_length'],iris['sepal_length'])
ax2.set_xlabel('petal_length')
ax2.set_ylabel('sepal_length')
ax3.scatter(iris['petal_width'],iris['sepal_length'])
ax3.set_xlabel('petal_width')
ax3.set_ylabel('sepal_length')
plt.show()以下SAS出力結果です。
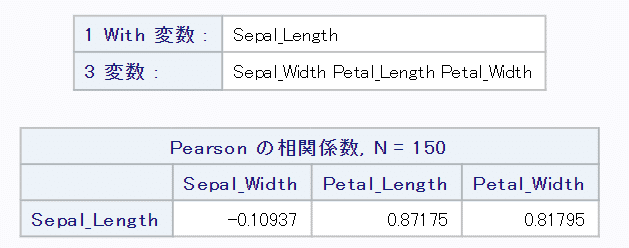
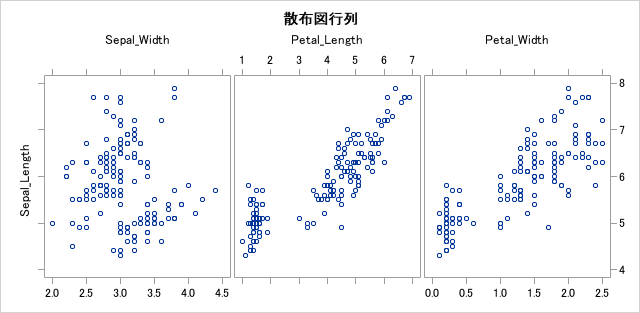
結果を見るとがくの長さとがくの幅の相関は他2カラムと比べ低く、負の相関が確認できます。がく同士のデータの相関が弱いのは意外ですね。
ANOVA 一元配置分散分析
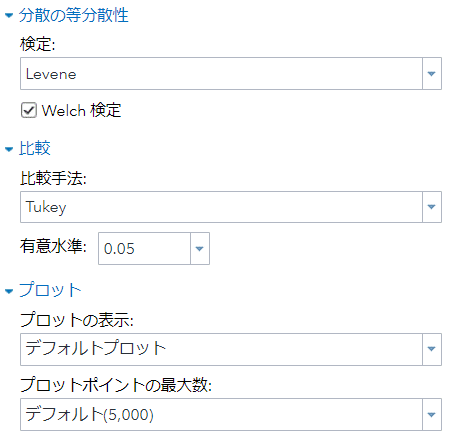
3群以上の平均値が統計的に異なるかどうか評価するANOVAも試してみましょう。今回は「Sepal_Length」に着目します。検定はルビーン検定、多重比較にはTukeyを用います。
生成されたコードを表示します。
proc glm data=WORK.IRIS;
class species;
model Sepal_Length=species;
means species / hovtest=levene welch plots=none;
lsmeans species / adjust=tukey pdiff alpha=.05;
run;全ての出力を再現できてはいないですが、Pythonでの書き換え例は以下が挙げられます。
from scipy.stats import f_oneway
#各DFに分割
setosa_sepal_length = iris[iris['species'] == 'setosa']['sepal_length']
versicolor_sepal_length = iris[iris['species'] == 'versicolor']['sepal_length']
virginica_sepal_length = iris[iris['species'] == 'virginica']['sepal_length']
# ANOVAの実行
f_stat, p_value = f_oneway(setosa_sepal_length, versicolor_sepal_length, virginica_sepal_length)
print(f"F-statistic: {f_stat:.2f}")
print(f"p-value: {p_value:.4f}")
from statsmodels.stats.multicomp import pairwise_tukeyhsd
print(pairwise_tukeyhsd(iris['sepal_length'], iris['species']))以下SAS上で出力された結果です。
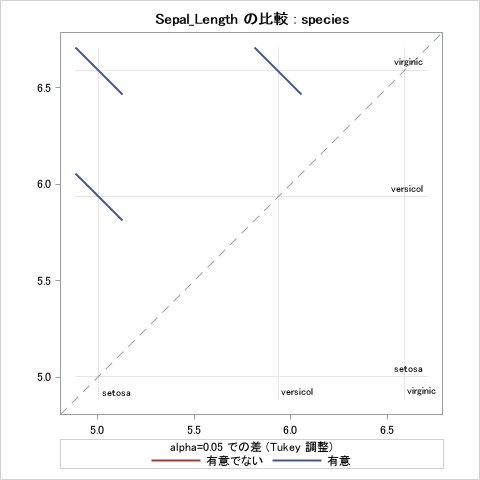
有意水準0.1%で帰無仮説が棄却されました。多重比較においても3品種それぞれの組み合わせで0.1%水準で帰無仮説が棄却されました。「Sepal_Length」においては3品種間で統計的に有意な差があることがわかりました。



まとめ
SASの特徴
SAS言語の構成は3つに分かれ、比較的理解しやすい
古くからある言語ということもあり比較的単純な文法です。何の処理を行っているかは各ステートメントの要素を順々に追っていけば大枠を理解できるのではないでしょうか。「言語構成」「;」等のルールに気を付ければ無理なくキャッチアップできそうです(もしかしたらバカの山にいるのかもしれませんが)。GUIとCUIの二刀流で分析
プロダクトやバージョンによりますがSASはGUI上で指定すればコードが自動生成され、簡単に分析を行うことができます。CUIで編集もできるため細かくカスタマイズを行うことが可能です。統計解析に強い
変数を指定しオプションを選択することで容易に分析を行い、詳細の結果を出力することが可能です。この点はPythonライブラリと比べるとSASの高い性能を感じます。因みに筆者はSPSS Statisticsを学生時代利用したことがありますがSASの方が挙動がよく、わかりやすいUIと出力結果だと感じました。
おわりに
簡易な内容ですが、SASにおけるデータの読み込みから分析までの一連の流れについてご紹介しました。いかがでしたでしょうか。
SAS上でのデータ加工や集計、欠損値補完などの前処理、マクロシューティング等に関しては割愛しました。筆者のスキルが追い付いたらそれらのトピックについて続編を書こうと考えています。
新たなスキルや知識をキャッチアップし続け、noteの投稿内容も充実させていきたいので今後とも読んでいただけたら幸いです。
データ分析に興味のある方募集中!
コグラフ株式会社データアナリティクス事業部ではPythonやSQLの研修を行った後、実務に着手します。
研修内容の充実はもちろん、経験者に相談できる環境が備わっています。
このようにコグラフの研修には、実務を想定し着実にスキルアップを目指す環境があります。
興味がある方は、下記リンクよりお問い合わせください。

X(Twitter)もやってます!
コグラフデータ事業部ではX(Twitter)でも情報を発信しています。
データ分析に興味がある、データアナリストになりたい人など、ぜひフォローお願いします!
📢Wantedly新掲載!
— アラリコ@コグラフ株式会社 | データ事業部 (@CographData) July 14, 2023
「データに興味がある」
「データに携わる仕事がしたい」
そこのあなた!
私たちと一緒にデータ分析しませんか?
IT業界未経験の方も大歓迎です☺️#エンジニア転職 #データ分析 #駆け出しエンジニアと繋がりたいhttps://t.co/S9o7VSjGRt
この記事が気に入ったらサポートをしてみませんか?