Windowsでvoicevox_coreをPythonで動かす

Windowsでvoicevox coreをPythonで使う際に、
ハマってしまったのでメモ。
https://github.com/VOICEVOX/voicevox_core
ライブラリのダウンロード
通常通り、Cドライブ直下かユーザー直下に
PowerShellを立ち上げて以下の命令を打つ。
voicevox_coreというフォルダとdownload.exeが作られる。
voicevox_coreは作業ディレクトリにする。
> Invoke-WebRequest https://github.com/VOICEVOX/voicevox_core/releases/latest/download/download-windows-x64.exe -OutFile ./download.exeこの場合はlatestを選んでいるが、以下ページから適切なものを探す。https://github.com/VOICEVOX/voicevox_core/releases

以下の命令を実行すると、voicevox_core内に、必要なライブラリなどがインストールされます。
> ./download.exedownload.exeはもう特に必要ないです。
Python環境の構築
voicevox はPython3.8で動いているので、3.8を先にインストールする。
https://www.python.org/downloads/release/python-380/
Pathを忘れず通しておく。
コマンドプロンプトでvoicevox_coreに移動して以下のコマンドを打って
venv環境を作る。
> py -3.8 -m venv python-env次に仮想環境を立ち上げる。
> python-env\Scripts\activateちゃんと3.8になっているか確認。
> python -Vpipをバージョンを最新にする。
(今回はpipを上げていなかったせいで、後のvoicevox_coreのインストールが出来なかった。)
> python.exe -m pip install --upgrade pip次にvoicevox_coreのpythonパッケージを入れるので
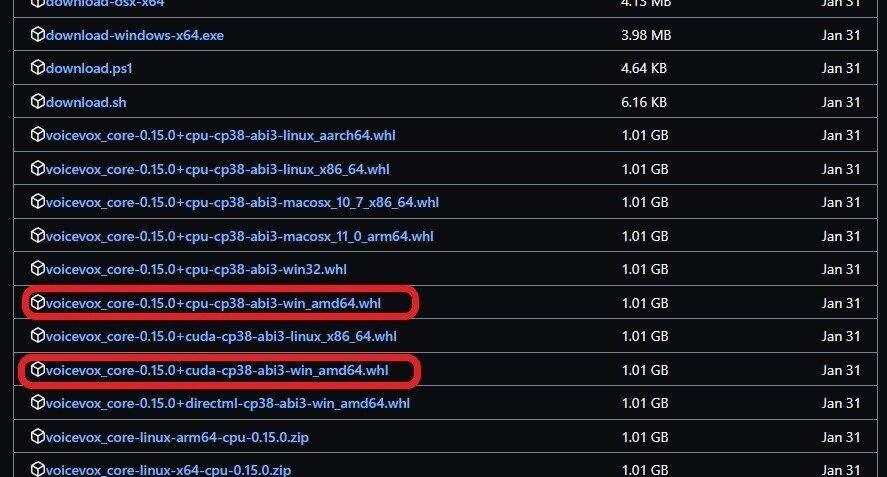
先ほどのライブラリのリンク集の下から適切なものを選ばなければならない。
一般的なwindowsユーザーならwin_amd64と書かれている以下の形式のものから選ぶことになる。
voicevox_core-version+cpu-cp38-abi3-win_amd64.whl
voicevox_core-version+cuda-cp38-abi3-win_amd64.whl
GPUで動かすならcudaを選ぶ。
今回はCPUでバージョン0.15.0を選ぶ。
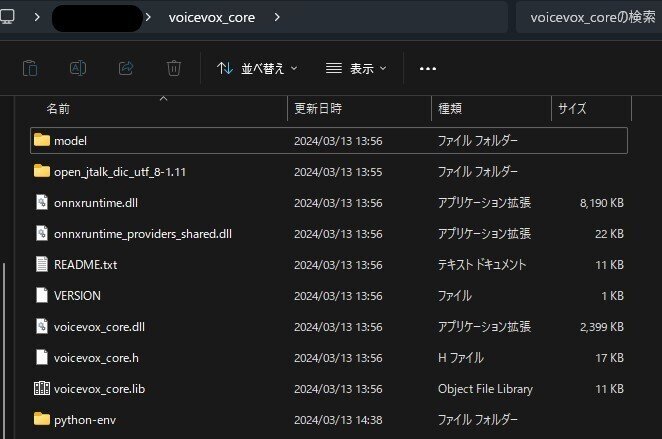
> pip install https://github.com/VOICEVOX/voicevox_core/releases/download/0.15.0/voicevox_core-0.15.0+cpu-cp38-abi3-win_amd64.whl以下のファイルの配置になりました。
実行してみる
ルートディレクトリで以下のコードを実行して、ファイルが書き出されるか確認する。
from pathlib import Path
from voicevox_core import VoicevoxCore, METAS
core = VoicevoxCore(open_jtalk_dict_dir=Path("open_jtalk_dic_utf_8-1.11"))
speaker_id = 1 #ずんだもん
text = "こんにちは、これはテストなのだ。"
core.load_model(speaker_id) # 指定したidのモデルを読み込む
wave_bytes = core.tts(text, speaker_id) # 音声合成を行う
with open("test_zundamon.wav", "wb") as f:
f.write(wave_bytes) # ファイルに書き出す以下のコードで、簡易的に再生できる。
import pyaudio
from io import BytesIO
import wave
# 生成された音声データ(wave_bytes)を再生する
def play_audio(wave_bytes):
# BytesIOオブジェクトを使用してメモリ上にwaveファイル形式でデータを格納
wave_io = BytesIO(wave_bytes)
wave_obj = wave.open(wave_io, 'rb')
# PyAudioの初期化
p = pyaudio.PyAudio()
# ストリームを開く
stream = p.open(format=p.get_format_from_width(wave_obj.getsampwidth()),
channels=wave_obj.getnchannels(),
rate=wave_obj.getframerate(),
output=True)
# データを読み込んで再生
data = wave_obj.readframes(1024)
while data:
stream.write(data)
data = wave_obj.readframes(1024)
# ストリームを閉じる
stream.stop_stream()
stream.close()
# PyAudio終了
p.terminate()
# 生成した音声を再生
play_audio(wave_bytes)
参考:
この記事が気に入ったらサポートをしてみませんか?