
Snowflakeで半構造化データを扱ってみた

分析屋の中田(ナカタ)です。
Snowflakeの半構造化データ操作を試してみました。
半構造化データとは
一般に、Excel管理できるようなテーブルデータを構造化データ
それ以外を非構造化データと呼びます。
非構造化データには画像・動画・音声・半構造化データなどがあります。
今回のテーマの半構造化データは、テーブルデータほどガッチリ管理されていないものの
JSONやXMLのように決まったフォーマットを持つテキストを指します。
今回やること
以下リンク先の、Snowflakeの学習用サイトに登場する半構造化データ用の関数を元に
半構造化データの練習をします。
Tasty Bytes:半構造化データ | Snowflake Documentation
環境
Snowflakeのエディション:エンタープライズ版
クラウド:AWS(東京リージョン)
事前準備
先述の学習用サイトで手順を進めると、様々な練習用テーブルが作成されます。
そのうちの以下のデータを使用します。
データベース名:frostbyte_tasty_bytes
スキーマ名:raw_pos
テーブル名:menu
カラム名:menu_item_health_metrics_obj
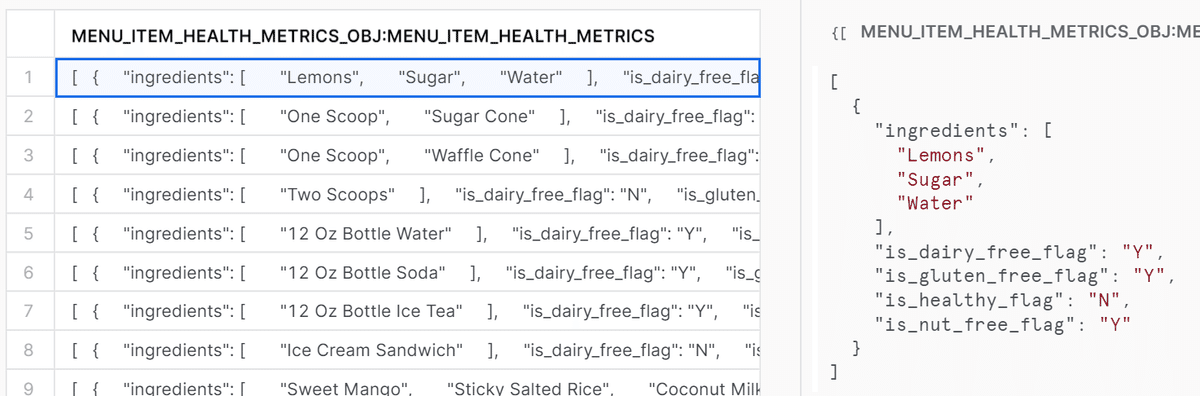
データは以下の通り、JSON形式になっています。
このデータに対して、半構造化データ用の関数を試していきます。
SELECT
m.menu_item_health_metrics_obj
FROM
frostbyte_tasty_bytes.raw_pos.menu m
;
1行目のデータをコピペしたものは以下の通りです。
{
"menu_item_health_metrics": [
{
"ingredients": [
"Lemons",
"Sugar",
"Water"
],
"is_dairy_free_flag": "Y",
"is_gluten_free_flag": "Y",
"is_healthy_flag": "N",
"is_nut_free_flag": "Y"
}
],
"menu_item_id": 10
}まずは第1階層として
"menu_item_health_metrics"
"menu_item_id"
の2属性があります。
さらに
"menu_item_health_metrics"の値は配列で
"ingredients"
"is_dairy_free_flag"
"is_gluten_free_flag"
"is_healthy_flag"
"is_nut_free_flag"
という5属性のJSON形式です。
さらに"ingredients"は値として配列を持っています。
ドット表記
半構造化データから、特定の属性のデータを抽出します。
そのためにはドット表記と呼ばれる記法を使用します。
サンプルとして以下のデータを用意しました。
SELECT * FROM sample_json;
上記のように、JSON形式でネストされたデータについては下記のクエリで値を取得します。
SELECT
json_data:"col1"."col2"."col3"
FROM
sample_json
;
Snowflakeの学習用サンプルデータでも同様にドット表記を用いて
まずは第1階層を取得してみます。
--ドット表記
SELECT
m.menu_item_health_metrics_obj:"menu_item_health_metrics"
FROM
frostbyte_tasty_bytes.raw_pos.menu m
;
第1階層の"menu_item_health_metrics"の中身を取得できました。
ここから配下の”ingredients”の値を取得するために以下のクエリを書きたくなりますが
これは失敗します。
SELECT
m.menu_item_health_metrics_obj:"menu_item_health_metrics"."ingredients"
FROM
frostbyte_tasty_bytes.raw_pos.menu m
;
このデータはJSON形式でネストされているわけではなく
配列になっています。

上記画像のように、角かっこ [ ] で囲まれているものは配列です。
この中身はJSON形式の第2階層としてドット表記でアクセスできず
“ingredients”というキーがないとしてNULLが返ってきます。
FLATTEN関数
配列をほぐすため、FLATTEN関数を使用します。
例として、[1,2,3]という配列をほぐすクエリを書きます。
SELECT
VALUE
FROM
TABLE(FLATTEN(input => PAESE_JSON('[1,2,3]')))
;FLATTEN関数の引数inputに対して、PARSE_JSON関数で文字列の[1,2,3]を半構造化データとして認識させています。
戻り値としてVALUEという項目があり、これがほぐされた結果です。
TABLE関数によって、FLATTEN関数の結果をテーブルとしてFROM句に指定できるようにしています。

ここまで散々でてきた「配列をほぐす」というのは
1行に[1,2,3]の配列としてまとまっていたデータを、上記画像のように複数行に分けて縦に分割することです。
ちなみにGoogleスプレッドシートやPythonのNumPyにも、同様のFLATTEN関数が存在します。

さっそく、学習用データも配列をほぐしてみます。
対象は以下のデータです。
SELECT
menu_item_health_metrics_obj:menu_item_health_metrics
FROM
frostbyte_tasty_bytes.raw_pos.menu
;
このSELECT文をまるごとFLATTEN関数の引数inputに渡せばいいのかな?
ということでこんなクエリを書くとエラーになります。
SELECT
obj.VALUE:"ingredients"
FROM
TABLE(FLATTEN(input => SELECT menu_item_health_metrics_obj:menu_item_health_metrics FROM frostbyte_tasty_bytes.raw_pos.menu)) obj;
そのままぶちこんでもダメらしいので書き換えます。
LATERAL結合
SELECT
obj.VALUE:"ingredients"
FROM
frostbyte_tasty_bytes.raw_pos.menu m,
LATERAL FLATTEN (input => m.menu_item_health_metrics_obj:menu_item_health_metrics) obj
;無事、ingredientsの値を取得できています。

ここで使用したLATERAL結合とは
FROM 左側テーブル , LATERAL (右側インラインビュー)
の形式で使用します。
右側インラインビューは、SELECT文やFLATTEN関数を指定します。
適当なサンプルテーブル(tbl1とtbl2)を作ってLATERAL結合してみます。
tbl1の中身

tbl2の中身

SELECT
*
FROM
tbl1
,LATERAL (SELECT * FROM tbl2)
;結果は以下の通りです。

これって・・・いわゆる直積ですね。
この使い方だとCROSS JOIN(もしくはカンマ単体)と同じですが
LATERAL結合は左側テーブルの列を、右側で使用することができます。
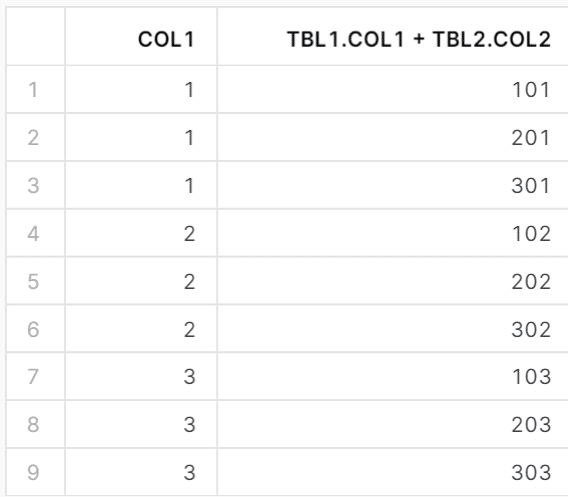
例えば以下のクエリです。
SELECT
*
FROM
tbl1
,LATERAL (SELECT tbl1.col1 + tbl2.col2 FROM tbl2)
;
CROSS JOINではエラーになります。
SELECT
*
FROM
tbl1
CROSS JOIN (SELECT tbl1.col1 + tbl2.col2 FROM tbl2)
;
通常はJOINの右側を、左側の行を使って動的に変えることはできません。
CROSS JOINで同じ結果を作るなら、右側テーブルを固定して以下のように書きます。
SELECT
tbl1.col1
,tbl1.col1 + tbl2.col2
FROM
tbl1
CROSS JOIN tbl2
;LATERAL結合の右側は、左側テーブルを使って動的に変えられるということで
これも相関サブクエリの一種と言えます。
話を戻しまして・・・
FLATTEN関数で配列をほぐしたい場合は
FROM 元のテーブル , LATERAL FLATTEN (input => 元のテーブル.配列のカラム)
という書き方になります。
ということでLATERAL FLATTENはワンセットでよく登場するようです。
配列の要素
学習用テーブルの半構造化データを解析していき
配列まで分解できました。
配列の要素へのアクセスは、プログラミングの配列同様にインデックス番号でアクセスします。
インデックス番号は0番はじまりです。
以下は、配列の最初の要素を調べるクエリです。
SELECT
obj.VALUE:"ingredients"[0]
FROM
frostbyte_tasty_bytes.raw_pos.menu m,
LATERAL FLATTEN (input => m.menu_item_health_metrics_obj:menu_item_health_metrics) obj
;
行によって要素数が違ってもOKです。
以下はインデックス番号2(つまり3番目の要素)を取得するクエリですが
要素数が1つや2つの行はNULLが表示されます。
SELECT
obj.VALUE:"ingredients"[2]
FROM
frostbyte_tasty_bytes.raw_pos.menu m,
LATERAL FLATTEN (input => m.menu_item_health_metrics_obj:menu_item_health_metrics) obj
;
最後に
半構造化データはメリット・デメリットがあるため扱いには要注意です。
メリットとしては、カラムを動的に追加することができる点です。
デメリットとしては、テーブルのように制約を指定できない点です。
いわゆるEAVアンチパターンになるため、最初からJSON型を選択するのではなく
必要な場面になれば使うという認識になります。
例えば、アプリケーション側で属性情報を自由に追加したいという要求があった場合
JSON型のカラムを持たせると良さそうです。
ここまでお読みいただき、ありがとうございました!
この記事が少しでも参考になりましたら「スキ」を押していただけると幸いです!
これまでの記事はこちら!
株式会社分析屋について
弊社が作成を行いました分析レポートを、鎌倉市観光協会様HPに掲載いただきました。
ホームページはこちら。
noteでの会社紹介記事はこちら。
【データ分析で日本を豊かに】
分析屋はシステム分野・ライフサイエンス分野・マーケティング分野の知見を生かし、多種多様な分野の企業様のデータ分析のご支援をさせていただいております。 「あなたの問題解決をする」をモットーに、お客様の抱える課題にあわせた解析・分析手法を用いて、問題解決へのお手伝いをいたします!
【マーケティング】
マーケティング戦略上の目的に向けて、各種のデータ統合及び加工ならびにPDCAサイクル運用全般を支援や高度なデータ分析技術により複雑な課題解決に向けての分析サービスを提供いたします。
【システム】
アプリケーション開発やデータベース構築、WEBサイト構築、運用保守業務などお客様の問題やご要望に沿ってご支援いたします。
【ライフサイエンス】
機械学習や各種アルゴリズムなどの解析アルゴリズム開発サービスを提供いたします。過去には医療系のバイタルデータを扱った解析が主でしたが、今後はそれらで培った経験・技術を工業など他の分野の企業様の問題解決にも役立てていく方針です。
【SES】
SESサービスも行っております。