プログラミング未経験者が3ヶ月勉強してAIを使ったポケモンのキャラクター画像分類をやってみた

はじめに
こんにちは!
この記事では、プログラミング未経験である私が、AIに特化したプログラミングスクールである Aidemyさん に通い、卒業制作として作成したポケモン画像認識アプリについてご紹介します。
想定する読者
私のように未経験からPythonや機械学習について学ぼうとする方々です。
特に、今後Aidemyさんで「AIアプリ開発講座」を受講される方は、似たような制作課題に取り組まれると思うので、ある程度参考にしていただけるのではないかと思います。
成果物
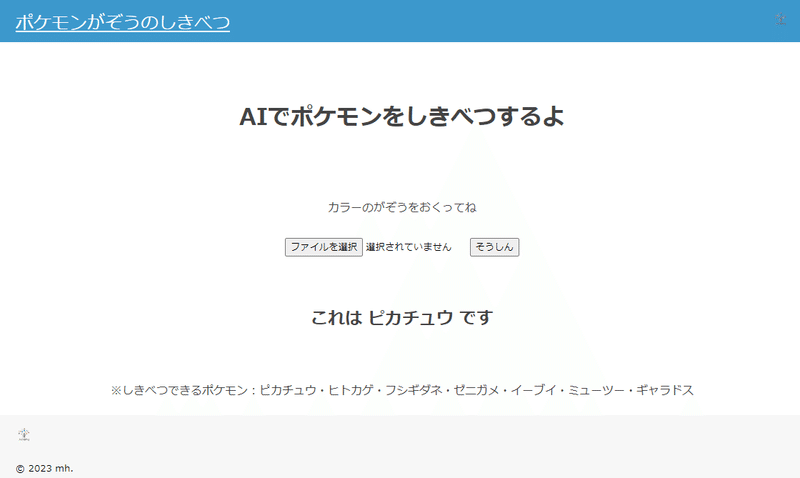
早速ですが、こちらが私が作成したポケモン画像認識アプリです。
現在、ポケモンは1000種類くらいいるみたいですが、今回は、昔からいる以下の7種類の分類にしています。
ピカチュウ
ヒトカゲ
ゼニガメ
フシギダネ
イーブイ
ギャラドス
ミューツー
このアプリで、実際にピカチュウの画像を送ってみると、、、

正解を返してくれます!!
プログラムの詳細
さて、ここからは実際に私が作ったプログラムの詳細についてお話します。
開発環境
Google Colaboratory
Visual Studio Code
画像収集
画像の取得はKaggleに公開されているデータをお借りしました。
Kaggle(カグル)は、企業や研究者がデータを投稿し、世界中の統計課やデータ分析家がその際的モデルを競い合う、予測モデリング及び分析手法関連プラットフォームです。
このデータセットのうち、今回利用した画像とその枚数は、ピカチュウ(164)、ヒトカゲ(131)、ゼニガメ(177)、フシギダネ(148)、イーブイ(143)、ギャラドス(136)、ミューツー(134)です。
Kaggleの画像の枚数がバラバラだったので、調整してだいたい150枚前後になるようにしています。
さて、ここからがGoogle Colaboratoryでの作業です。
まずは、このデータをGoogleドライブにアップ。
Google Colaboratoryでマウントします。
from google.colab import drive
drive.mount('/content/drive')※マウントとは、コンピュータに接続した機器やメディアをコンピュータに認識させ、使える状態にすることです。ここでは、Google Colaboratoryに接続したGoogleドライブの画像データをGoogle Colaboratoryから使えるようにすることを指します。
ライブラリのインストール
Google Colaboratory上で、必要なライブラリをインストールします。
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers画像の読み込み
ポケモンの画像を格納するリストを作成し、画像の前処理を行ったうえで、リストに格納していきます。
画像の一覧を os.listdir をつかって取得し、画像の枚数分 cv2.imread で画像を読み込みます。
cv2.imread で画像を読み込む場合、色の順番がBGR(青、緑、赤)になりますが、後続処理でRGB(赤、緑、青)の順になっている必要があるので、cv2.split をつかって色分解し、cv2.merge で指定の順番に再結合します。
その後、cv2.resize で画像を50×50にそろえて、リストに追加します。
# ポケモンの画像を取得
path_eevee = os.listdir("/content/drive/MyDrive/Colab_Notebooks/pokemon/Eevee/")
path_gyarados = os.listdir("/content/drive/MyDrive/Colab_Notebooks/pokemon/Gyarados/")
path_mew2 = os.listdir("/content/drive/MyDrive/Colab_Notebooks/pokemon/Mewtwo/")
path_pikachu = os.listdir("/content/drive/MyDrive/Colab_Notebooks/pokemon/Pikachu/")
path_charmander = os.listdir("/content/drive/MyDrive/Colab_Notebooks/pokemon/hitokage_Charmander/")
path_bulbasaur = os.listdir("/content/drive/MyDrive/Colab_Notebooks/pokemon/husigidane_Bulbasaur/")
path_squirtle = os.listdir("/content/drive/MyDrive/Colab_Notebooks/pokemon/zenigame_Squirtle/")
# ポケモンの画像を格納するリスト作成
img_eevee = []
img_gyarados = []
img_mew2 = []
img_pikachu = []
img_charmander = []
img_bulbasaur = []
img_squirtle = []
# ポケモンの画像の前処理
for i in range(len(path_eevee)):
path = "/content/drive/MyDrive/Colab_Notebooks/pokemon/Eevee/" + path_eevee[i]
img = cv2.imread(path)
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_eevee.append(img)
for i in range(len(path_gyarados)):
path = "/content/drive/MyDrive/Colab_Notebooks/pokemon/Gyarados/" + path_gyarados[i]
img = cv2.imread(path)
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_gyarados.append(img)
for i in range(len(path_mew2)):
path = "/content/drive/MyDrive/Colab_Notebooks/pokemon/Mewtwo/" + path_mew2[i]
img = cv2.imread(path)
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_mew2.append(img)
for i in range(len(path_pikachu)):
path = "/content/drive/MyDrive/Colab_Notebooks/pokemon/Pikachu/" + path_pikachu[i]
img = cv2.imread(path)
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_pikachu.append(img)
for i in range(len(path_charmander)):
path = "/content/drive/MyDrive/Colab_Notebooks/pokemon/hitokage_Charmander/" + path_charmander[i]
img = cv2.imread(path)
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_charmander.append(img)
for i in range(len(path_bulbasaur)):
path = "/content/drive/MyDrive/Colab_Notebooks/pokemon/husigidane_Bulbasaur/" + path_bulbasaur[i]
img = cv2.imread(path)
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_bulbasaur.append(img)
for i in range(len(path_squirtle)):
path = "/content/drive/MyDrive/Colab_Notebooks/pokemon/zenigame_Squirtle/" + path_squirtle[i]
img = cv2.imread(path)
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_squirtle.append(img)次に、Xに学習データ、yに正解データ(0:イーブイ、1:ギャラドス、2:ミューツー、3:ピカチュウ、4:ヒトカゲ、5:フシギダネ、6:ゼニガメ)を入れていきます。
学習データとテストデータの割合は 7:3 にしました。
# np.arrayでXに学習画像、yに正解ラベルを代入
X = np.array(img_eevee + img_gyarados + img_mew2 + img_pikachu + img_charmander + img_bulbasaur + img_squirtle)
y = np.array([0]*len(img_eevee) + [1]*len(img_gyarados) + [2]*len(img_mew2) + [3]*len(img_pikachu) + [4]*len(img_charmander) + [5]*len(img_bulbasaur) + [6]*len(img_squirtle) )
# 配列のラベルをシャッフルする
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# 学習データと検証データを用意
X_train = X[:int(len(X)*0.7)]
y_train = y[:int(len(y)*0.7)]
X_test = X[int(len(X)*0.7):]
y_test = y[int(len(y)*0.7):]
# データの正規化
X_train = X_train / 255.0
X_test = X_test / 255.0
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
# 正解ラベルをone-hotの形にする
y_train = to_categorical(y_train, num_classes=7)
y_test = to_categorical(y_test, num_classes=7)モデルの定義
今回はVGG16モデルを用いた転移学習を行いました。
転移学習では、すでに学習済みのモデルを使うことで、より少ない画像、より短時間で学習モデルを構築することができます。
VGG16のモデルの後に、独自のモデル top_model を追加し、VGGと連結します。
# モデルにvgg16を使用
input_tensor = Input(shape=(50, 50, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# vggのoutputを受け取り、クラス分類する層を定義
# 中間層をいくつか定義
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='sigmoid'))
top_model.add(Dropout(0.5))
top_model.add(Dense(7, activation='softmax'))
# vggと、top_modelを連結
model = Model(vgg16.inputs, top_model(vgg16.output))
# vggの層の重みを変更不能にする。
for layer in model.layers[:15]:
layer.trainable = False※VGG16は、ILSVRCという画像認識競技会の2014年大会で2位になったモデルで、画像認識でよく使われるものです。VGG16の全体像については以下のページで簡単に説明されています。
コンパイルの実行
OptimizerはSGDを使い、learning_rateは1e-3(10の-3乗)にしました。
# コンパイルの実行
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(learning_rate=1e-3, momentum=0.9),
metrics=['accuracy'])モデルの学習
batch_size=32, epochs=15 にしています。
# 学習の実行
history = model.fit(X_train, y_train, batch_size=32, epochs=15, validation_data=(X_test, y_test))
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])モデルの予測
このモデルは0~9の値を返してくれるようになっているので、結果を見てぱっとわかるように、各数字に対応するキャラクターを日本語で返してくれるようにしています。
# モデルの予測
for i in range(10):
x = X_test[i]
plt.imshow(x)
plt.show()
pred = np.argmax(model.predict(x.reshape(1,50,50,3)))
if pred == 0:
print(str(pred) + "イーブイ")
elif pred == 1:
print(str(pred) + "ギャラドス")
elif pred == 2:
print(str(pred) + "ミューツー")
elif pred == 3:
print(str(pred) + "ピカチュウ")
elif pred == 4:
print(str(pred) + "ヒトカゲ")
elif pred == 5:
print(str(pred) + "フシギダネ")
else:
print(str(pred) + "ゼニガメ")予測結果のプロット
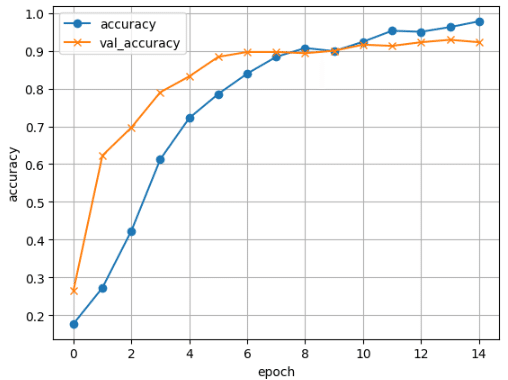
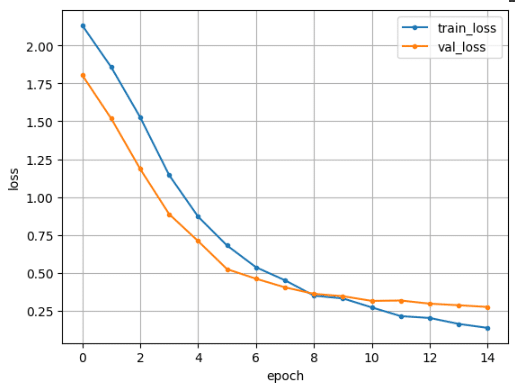
matplotlobを用いて、学習が進むごとに正解率と損失関数がどのように変化するかの結果を可視化するためのコードを書いていきます。
#正解率の結果プロット
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.grid()
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
#損失関数の結果プロット
train_loss=history.history['loss']
val_loss=history.history['val_loss']
epochs=len(train_loss)
plt.plot(range(epochs), train_loss, marker = '.', label = 'train_loss')
plt.plot(range(epochs), val_loss, marker = '.', label = 'val_loss')
plt.legend(loc = 'best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()結果、、、
損失0.27 正解率0.92 とそれなりに高い精度のモデルが出来上がりました。

Test loss: 0.2758461833000183
Test accuracy: 0.9225806593894958学習結果を見ると 、テストデータの正解率(Val_accuracy)は、6回目くらいでおよそ90%くらいになっています。
モデルの出力
このモデルをアプリに活用するため、model.h5としてダウンロードします。
# モデルのデータ出力
from google.colab import files
# resultディレクトリを作成
result_dir = "result"
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 学習したモデルを保存
model.save(os.path.join(result_dir, "model.h5"))
files.download("/content/result/model.h5")HTML・CSSの作成
Flaskフレームワークを使用して、アプリのインターフェースを作成しました。コードは、Aidemyさんの講座の Flask入門 のものを参考にしました。
※HTML
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>AIでポケモン画像を識別 </title>
<link rel="stylesheet" href="./static/stylesheet.css">
</head>
<body>
<header>
<img class="header_img" src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<a class="header-logo" href="#">ポケモンがぞうのしきべつ</a>
</header>
<div class="main">
<h1>AIでポケモンをしきべつするよ</h1>
<p>カラーのがぞうをおくってね</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file">
<input class="btn" value="そうしん" type="submit">
</form>
<div class="answer">
<h2>{{answer}}</h2>
</div>
<p>※しきべつできるポケモン:ピカチュウ・ヒトカゲ・フシギダネ・ゼニガメ・イーブイ・ミューツー・ギャラドス
</p>
<footer>
<img class="footer_img" src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<small>© 2023 mh. </small>
</footer>
</body>
</html>
※CSS
header {
background-color: #3d98cc;
height: 60px;
margin: -8px;
display: flex;
flex-direction: row-reverse;
justify-content: space-between;
}
.header-logo {
color: #fff;
font-size: 25px;
margin: 15px 25px;
}
.header_img {
height: 25px;
margin: 15px 25px;
}
.main {
height: 470px;
}
h1 {
color: #444444;
margin: 90px 0px;
text-align: center;
}
p {
color: #444444;
margin: 30px 0px 30px 0px;
text-align: center;
}
.answer {
color: #444444;
margin: 70px 0px 70px 0px;
text-align: center;
}
form {
text-align: center;
}
footer {
background-color: #F7F7F7;
height: 100px;
margin: -8px;
position: relative;
}
.footer_img {
height: 25px;
margin: 15px 25px;
}
small {
margin: 15px 25px;
position: absolute;
left: 0;
bottom: 0;
}工夫したポイント
最も試行錯誤した点は、正解率をいかに上げるかです。
今回私は以下のことを行いました。
分類するクラス数を変える
画像の前処理をする
ハイパーパラメータを調整する
それぞれについて、簡単に記載します。
1. 分類するクラス数を変える
AIに分類させるクラス数(キャラクターの種類)が多くなるほど、用意する画像が増えたり、学習が難しくなります。
今回、はじめは10クラスでトライしていましたが、その場合、いろんなパラメータを触ってみても正解率は85%程度でとどまってしまいました。
そこでクラス数を7に減らしたところ、正解率が向上し、90%を超えるようになりました。(たくさんの種類の分類できた方が楽しいので、クラス数は多い方がいいと思いますが、、、)
2. 画像の前処理を行う
画像の前処理としては、正規化を行いました。
# データの正規化
X_train = X_train / 255.0
X_test = X_test / 255.0X_train、y_train をそれぞれ255.0で割っています。
X_train、y_train は画像データなので、それぞれ0から255の値になっています。255.0で割ることで、0~1の範囲の数値に修正していることになります。
後工程で使っている活性化関数のsigmoidでは、取りうる値の範囲は0~1なので、入力も0~1範囲にする方がよいためです。
※正規化の処理をしない場合、それ以外のパラメータを全く変えないと、正解率が10~20%くらいでとどまってしまいました。
3. ハイパーパラメータを調整する
今回私が主に触ったハイパーパラメータは、主に以下です。
Optimizer:SGD ※learning_rate=1e-3(10の-3乗)
batch_size:32
epoch:15
# コンパイルの実行
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(learning_rate=1e-3, momentum=0.9),
metrics=['accuracy'])
# 学習の実行
history = model.fit(X_train, y_train, batch_size=32, epochs=15, validation_data=(X_test, y_test))learning_rateははじめ1e-4(10の-4乗)を使ったところ、なかなか収束しませんでしたが、1e-3にすることで、すぐに収束するようになりました。
※leanrng_rate=10e-4 の場合、epoch数50でも正解率は90%に到達せず

※leanrng_rate=10e-3 の場合、epoch数6くらいで正解率90%に到達

これらを行うことで、無事に正解率90%以上のポケモン画像認識アプリを作成することができました。
が、やりながら、「もっと学習すればいろんな引き出しができるだろうな」とも思っていましたので、今後もいろいろと勉強していきたいと思います。
おわりに
今回このAidemyさんの講座を受講したことで、機械学習の基礎に加えて、WEBサービスの基本的な仕組みを理解し、実装することができました。
AIに関するニュースが毎日飛び交う昨今なので、私のような非エンジニアでも一定以上のプログラミングスキルやAIスキルを身に着けておくことは重要だと思います。
今回学習したことを踏まえ、今後はPythonを使ったデータ分析等も学んでみようと思います。
最後までお読みいただきありがとうございました。
同じ講座を受講される方々や、似たようなものを作成される方々にとって、この記事が参考になれば幸いです!
参考
以下、本記事を記載するにあたり参考にしたページです。
この記事が気に入ったらサポートをしてみませんか?