
【初心者が】日本全国の気温を予測してみました

気象庁から気温データをダウンロードして日本全国の気温予測をしてみました。
私の環境
Python3
MacBook Air
Chrome
Google Colaboratory
気温データの中身
期間:1872年~2019年
場所:札幌、東京、名古屋、大阪、広島、福岡
私のレベル
プログラミング初心者
ダウンロードしたときのデータの状態
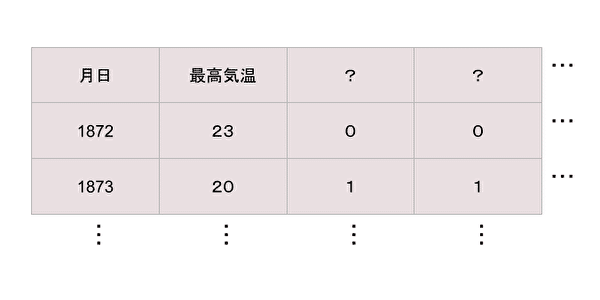
ダウンロードしたとき最高気温と他によくわからないデータが2列ありました。
また、日本語が列タイトルに入っていました。
それと、上に空白の行が2行ありました。
ところどころ空白の欄がありました。(欠損値)
データ前処理
ダウンロードしたそのままの状態では気温予測ができません。
なので、まずダウンロードしたデータをテキストエディットで開いて、日本語をローマ字か英語に直します。
それが終わったらGoogle laboratoryで最高気温のデータを読み込みます。
# show upload dialog
from google.colab import files
uploaded = files.upload()
最高気温のCSVを読み込めたら、headを使って上の5行だけ出力してどんな状態か確認します。
import pandas as pd
Maximum_monthly_temperature = pd.read_csv('./Maximum_monthly_temperature.csv', engine='python', header=1,index_col=0,encoding = 'shift_jis')
print(Maximum_monthly_temperature.head())
先ほどテキストエディットで確認したときにあった上の空白2行と、2列目3列目にあった0と1の列を、削除します。
でもその前に必要なモジュールのインポートをします。
インポートしないで進めつつモジュールエラーが起きたら書き込んでいく方法でもいいと思います。
import pandas as pd
import numpy as np
import math
import knnimpute as knnimp
import matplotlib.pyplot as plt
from IPython.core.display import display
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers.recurrent import SimpleRNN, LSTM
from keras.layers import Dense, Activation, Dropout
from sklearn.metrics import mean_squared_error上の2行削除のコード
def pre_function(input_data):
input_data = input_data.reset_index()
input_data = input_data.drop( [0,1] ,axis=0)
return input_data必要のない列を削除するコードと欠損値を補完するコード
def delete_nun(pre_data):
pre_data = pre_data.drop(columns=["level_0",0])
pre_data = pre_data.astype(np.float32)
matrix = pre_data.values
missing_mask = np.isnan(matrix)
result = knnimp.knn_impute_few_observed(matrix, missing_mask, 3)
pre_data = pd.DataFrame(result, columns = pre_data.columns)
if 'level_23' in pre_data.columns:
pre_data = pre_data.drop(columns=["level_2","level_3","level_4","level_6","level_7","level_8","level_10","level_11","level_12","level_14","level_15","level_16","level_18","level_19","level_20","level_22","level_23"])
elif 'level_17' in pre_data.columns:
pre_data = pre_data.drop(columns=["level_2","level_3","level_5","level_6","level_8","level_9","level_11","level_12","level_14","level_15","level_17"])
return pre_dataknnimpは欠損値の補完をするコードです。
単一代入法(ホットデック法)と言います。
これは欠損していないデータから似ているデータを探し出して代入してくれます。
CSVファイルの読み込む形式
def read_temperature(csv_file):
temperature = pd.read_csv(csv_file, engine='python', encoding = 'shift_jis',header=None)
temperature =pre_function(temperature)
temperature = delete_nun(temperature)
#display(temperature)
return temperature
最高気温データを読み込みます。
Maximum_monthly_temperature = read_temperature('./Maximum_monthly_temperature.csv')データ前処理終わり。
学習用データとテスト用データに分ける
3分の1をテスト用データにします。

スケールを使います。
scaler = MinMaxScaler()
Maximum_monthly_temperature = scaler.fit_transform(Maximum_monthly_temperature)scaler.fit_transformとのちに出てくるscaler.inverse_transformが同じ数字出ないとあとでエラーになります。
なのでprintでscaler.fit_transformとscaler.inverse_transformの数字をここで確認しておきます。
print(scaler.fit_transform(Maximum_monthly_temperature).shape)
print(scaler.inverse_transform(Maximum_monthly_temperature).shape)trainとtestを分けるコードを書きます。
train_size = int(len(Maximum_monthly_temperature) * 0.67)
test_size = len(Maximum_monthly_temperature) - train_size
train, test = Maximum_monthly_temperature[0:train_size,:], Maximum_monthly_temperature[train_size:len(Maximum_monthly_temperature),:]create_datasetという関数を作ってdataXとdataYに分けるコードを書きます。
def create_dataset(Maximum_monthly_temperature, look_back=1):
dataX, dataY = [], []
for i in range(len(Maximum_monthly_temperature)-look_back-1):
xset = []
for j in range(Maximum_monthly_temperature.shape[1]):
a = Maximum_monthly_temperature[i:(i+look_back), j]
xset.append(a)
dataY.append(Maximum_monthly_temperature[i + look_back, 0])
dataX.append(xset)
return np.array(dataX), np.array(dataY)look_backとは、前のデータを数字分参照することです。

例えば1872年のデータは12ヶ月の気温データがあります。
なのでlook_backは12とします。
そうすると13こ目が12こ分前のデータを参照してくれます。
直前12個のデータを元に予測を行うということです。
look_back = 12
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)配列を形状変換する
次はtrainXとtestXをreshapeします。
reshapeとは、1行だったものを2行にしたり3行にしたり、2列にしたり3列にしたりして配列を組み直すことです。

カッコの中の数字が元の配列と違うとエラーになります。
LSTM予測モデルを作る
今回気温予測は時系列データなのでLSTMを使います。
LSTMとはLong-Short Term Memoryの略で、長期的にデータを保持することができるモデルです。
株価予測や売り上げ予測などの時系列データによく使われます。
最初のインポートでfrom keras.layers.recurrent import SimpleRNN, LSTMと書いたと思います。
SimpleRNNもデータを保持することができるモデルですが、長期的なものは保持できません。
なのでRNNとLSTM、二つを使って予測していきます。

上の図はLSTMの構造です。
入ってきたデータと前のデータが足されてシグモイド関数によって0から1の間の数字に変換されます。
それが忘却の重みになって、CECとTanhに入っていきます。
CECに入って足されたものが次のCECとなり、
Tanhに入って掛けられたものが前のデータになります。
ちょっとずつ前のデータが保持されていくのがLSTMというモデルです。
model = Sequential()
model.add(LSTM(4, input_shape=(testX.shape[1], look_back)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(trainX, trainY, epochs=1, batch_size=1, verbose=2)epochsのところが何回学習するかを決めるところです。
1とすれば1回学習されます。
1000とすれば1000回学習されます。
数字が多いほど計算に時間がかかります。
モデルが完成したらtrainXとtestXを予測します。
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
pad_col = np.zeros(Maximum_monthly_temperature.shape[1]-1)zerosとは2~6列をゼロで埋めるコードです。
inverse_transformをしているので1列になっています。
これを6列に直します。
そうしないとinverse_transformとscaler.inverse_transformの表の形状が合わなくてエラーが起きます。
def pad_array(val):
return np.array([np.insert(pad_col, 0, x) for x in val])
trainPredict = scaler.inverse_transform(pad_array(trainPredict))
trainY = scaler.inverse_transform(pad_array(trainY))
testPredict = scaler.inverse_transform(pad_array(testPredict))
testY = scaler.inverse_transform(pad_array(testY))平方平均二乗誤差を計算する
平方平均二乗誤差はRMSEと書いたりします。
平方平均二乗誤差とは、誤差の二乗を平均して平方根した数字のことです。
生じた誤差を評価する指数、精度を表してくれます。
下のコードは学習用データtrainとテスト用データtestの誤差による精度を表しくれます。
trainScore = math.sqrt(mean_squared_error(trainY[:,0], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(testY[:,0], testPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))この数値を見たりプロットした図の線を見ながらどのくらいの精度が出たかを見ます。
数字が小さいほど精度がいいということになります。
プロットする
# shift train predictions for plotting
trainPredictPlot = np.empty_like(Maximum_monthly_temperature)
trainPredictPlot[:, :] = np.nan
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict
# shift test predictions for plotting
testPredictPlot = np.empty_like(Maximum_monthly_temperature)
testPredictPlot[:, :] = np.nan
testPredictPlot[len(trainPredict)+(look_back*2)+1:len(Maximum_monthly_temperature)-1, :] = testPredict
# plot baseline and predictions
plt.figure(figsize=(100,10))
plt.plot(scaler.inverse_transform(Maximum_monthly_temperature)[ : ,0], label="Sapporo"[:50])
plt.plot(scaler.inverse_transform(Maximum_monthly_temperature)[ : ,1], label="Tokyo"[:50])
plt.plot(scaler.inverse_transform(Maximum_monthly_temperature)[ : ,2], label="Nagoya"[:50])
plt.plot(scaler.inverse_transform(Maximum_monthly_temperature)[ : ,3], label="Osaka"[:50])
plt.plot(scaler.inverse_transform(Maximum_monthly_temperature)[ : ,4], label="Hiroshima"[:50])
plt.plot(scaler.inverse_transform(Maximum_monthly_temperature)[ : ,5], label="Fukuoka"[:50])
plt.plot(trainPredictPlot[:50])
plt.plot(testPredictPlot[:50])
plt.legend()
plt.show()1872年から2019年までのデータをプロットするので
plt.figure(figsize=(100,10))
と書いて表を大きくします。

147年分を予測したのでとても長いグラフになってしまいました。
なので分割して画像が出るように100年単位でプロットしたいと思います。
trainPredictPlot = np.empty_like(Maximum_monthly_temperature)
trainPredictPlot[:, :] = np.nan
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict
# shift test predictions for plotting
testPredictPlot = np.empty_like(Maximum_monthly_temperature)
testPredictPlot[:, :] = np.nan
testPredictPlot[len(trainPredict)+(look_back*2)+1:len(Maximum_monthly_temperature)-1, :] = testPredict
for i in range(18):
print("index:", i*100, "~", (i+1)*100)
fig = plt.figure(figsize=(10,6))
plt.plot(scaler.inverse_transform(Maximum_monthly_temperature)[i*100:(i+1)*100,0], label="Sapporo")
plt.plot(scaler.inverse_transform(Maximum_monthly_temperature)[i*100:(i+1)*100,1], label="Tokyo")
plt.plot(scaler.inverse_transform(Maximum_monthly_temperature)[i*100:(i+1)*100,2], label="Nagoya")
plt.plot(scaler.inverse_transform(Maximum_monthly_temperature)[i*100:(i+1)*100,3], label="Osaka")
plt.plot(scaler.inverse_transform(Maximum_monthly_temperature)[i*100:(i+1)*100,4], label="Hiroshima")
plt.plot(scaler.inverse_transform(Maximum_monthly_temperature)[i*100:(i+1)*100,5], label="Fukuoka")
plt.plot(trainPredictPlot[i*100:(i+1)*100, :], label="Train")
plt.plot(testPredictPlot[i*100:(i+1)*100, :], label="Test")
plt.legend()
plt.show()すると100年単位でグラフがプロットされます。
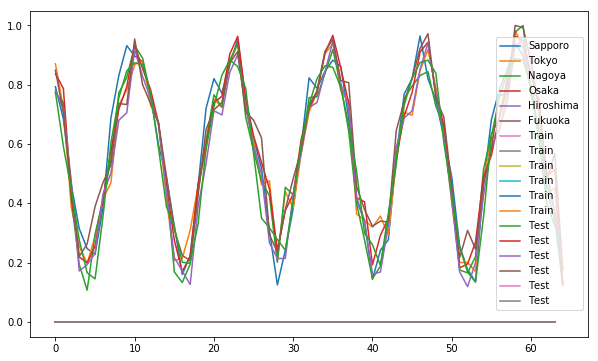
これで予測結果がどうなっているか見れると思います。
でもこれだとどれがどのことを指しているかわかりずらいので表示するデータを限定しようと思います。

札幌とtrainとtestを表示して見ました。
このモデルでは1回しか学習していないですが、札幌とテストデータがだいたい同じところにきています。
学習回数を増やせばもっといい精度が出せるのかなと思いました。
まとめ
機械学習を始めて、初めて予測までやったので間違っているところがあるかもしれませんが、アウトプットができてとても勉強になりました。