
pythonでtweet分析をやってみた ~言論弾圧に負けず、ウソを発信する工作員と戦うためのツール作成~

■イントロ
こんにちは。びりぶです。
この世にはウソの情報が溢れています。
多くの人にその事実を知ってもらい、ウソの情報により不安や心配に陥らず、真実により喜びと希望をもって生活できる世の中になるように、ツイッターで真実を拡散しています。
ただ、ツイッター上には、ウソの情報を広めたい工作員や雇われ工作員が多く存在し、真実の情報が広がらないよう工作活動を行ってきます。
特に、巧妙な工作員は、善人なふりをして近づき、真実にウソを混ぜ、攪乱工作を行ってきます。
そんな工作員の行動がわかるツール、工作員と戦えるツールがないかと考えていたのですが、自分で作ってみようということで、作ってみたので、共有します。
◇この記事を読むとできること
①指定ユーザのフォローユーザの作成日時の分布作成
②指定ユーザのフォロワーの作成日時の分布作成
③指定ユーザの相互フォロワーリスト作成
④指定ユーザのツイート傾向分析
-ツイート時間分布(曜日、平日、土日)
-ツイートワード可視化
◇環境
・anaconda
・spyder 3.3.1
・python 3.7
・windows 10
・tweepy 3.8.0
・matplotlib 2.2.3
◇この記事を書いた人
・pythonは触ったことがあり、基本構文はわかる
・webの知識(HTML,CSSなど)はなし
■手順
--1. 各種インポート
--2. Twitter APIを使用するキーを定義、認証
--3. フォローユーザ、フォロワー情報を取得する関数作成
--4. タイムラインのテキスト情報を取得する関数作成
--5. 分析対象ユーザの名前入力、Twitter API認証
--6. フォローユーザ、フォロワーの作成日時分布
--7. 相互フォロワーチェック
--8. タイムラインテキストをwordcloudで可視化
--9. タイムラインの日時から、活動傾向を分析
■コードの説明
--1.各種インポート
import tweepy
import pandas as pd
import matplotlib as plt
from datetime import timedelta
from word_analyze import wa #-独自に作成した関数wa
import csv各種インポートします。
ここで、tweepyはバージョンにより動作有無が異なるので、エラーが生じた場合は、tweepyのドキュメントを参照下さい。https://kurozumi.github.io/tweepy/index.html
また、今回wordcloudで可視化を行いましたが、本記事では使い方を省略しています。以下などを参考に作成下さい。
https://qiita.com/kaka__non/items/04bf3752f79074baafde
--2. Twitter APIを使用するキーを定義、認証
#-Twitter APIを使用するためのConsumerキー、アクセストークン設定
def getApiInstance():
Consumer_key = ***取得したキーを入力***
Consumer_secret = ***取得したキーを入力***
Access_token = ***取得したキーを入力***
Access_secret = ***取得したキーを入力***
#-認証
auth = tweepy.OAuthHandler(Consumer_key, Consumer_secret)
auth.set_access_token(Access_token, Access_secret)
api = tweepy.API(auth ,wait_on_rate_limit = True, wait_on_rate_limit_notify=True)
return apiTwitter APIを使用するためのConsumerキー、アクセストークンを設定します。コード自体は少ないですが、Twitter API 登録が少し面倒でした。以下のリンクを参考にしました。
https://dev.classmethod.jp/articles/twitter-api-approved-way/
リンク先では、認証に2時間と書いてあったのですが、私がトライした時には即認証されました。以前は審査が大変だったようですが、今は、自動処理のようです。
また、apiのインスタンス作成時に、
wait_on_rate_limit = True,
wait_on_rate_limit_notify=True
にしておくことで、制限なく(制限超えた場合は、15分待機)リクエストを送れるようになるようです。
http://tmngtm.hatenablog.com/entry/2016/11/10/133320
api = tweepy.API(auth ,wait_on_rate_limit = True, wait_on_rate_limit_notify=True)--3. フォローユーザ、フォロワー情報を取得する関数作成
#-フォロワー_info
def getFollowers_info(Api, Id):
#-Cursorを使ってフォロワーのidを逐次的に取得
followers_ids = tweepy.Cursor(Api.followers_ids, id = Id, cursor = -1).items()
followers_ids_list = []
try:
for followers_id in followers_ids:
user = Api.get_user(followers_id)
user_info = [user.screen_name, user.created_at]
followers_ids_list.append(user_info)
print('----------')
print(user_info)
except tweepy.error.TweepError as e:
print(e.reason)
return followers_ids_listCursorを使ってフォロワーのidを逐次的に取得します。
Api.followers_idsでフォロワーのidを取得できます。
followers_ids = tweepy.Cursor(Api.followers_ids, id = Id, cursor = -1).items()
取得したidを順に、リクエストで送り、そのidの情報を取得します。そのご、必要な部分(今回は、スクリーン名:screen_nameと作成日時:created_at)のみを取得し、リストを作成します。
スクリーン名とは、ツイッターの「@○○○」の○○○名前です。
for followers_id in followers_ids:
user = Api.get_user(followers_id)
user_info = [user.screen_name, user.created_at]
followers_ids_list.append(user_info)フォローユーザのリストを作成する場合は、Api.followers_idsをApi.friends_idsに変更します。
--4. タイムラインのテキスト情報を取得する関数作成
#-timeline_info
def gettimeline_info(api, screen_name,df,columns):
num=0
pages=[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17]
for page in pages:
tweets=api.user_timeline(screen_name, count=200, page=page) #-1回200,pageはページの番号
for t in tweets:
t.created_at+=timedelta(hours=9) #-JSTに
se = pd.Series([t.created_at, t.text], columns) #-1行作成
df = df.append(se, ignore_index=True) #-結合
print('----------')
print(t.created_at)
print("num:",num,"page:",page)
num+=1
print(num, 'ツイート表示しました。')
return dfapi.user_timelineで、指定ユーザのタイムラインを新しいほうから取得できます。できるだけ多く取得するため、count=200(最大取得数)とし、page=1~17(最大16回)でページ数分ループを回します。
https://non-face.hatenablog.com/entry/2018/07/15/215614
t.created_at+=timedelta(hours=9) #-JSTに
se = pd.Series([t.created_at, t.text], columns) #-1行作成
df = df.append(se, ignore_index=True) #-結合得られたライムラインの作成日時(created_at)とテキスト(text)をdf.appendで次々と結合して、データフレームを作成します。この時、timedeltaで9時間足して、日本時間(JST)に直しています。
--5. 分析対象ユーザの名前入力、Twitter API認証
def mainについて説明します。
screen_name = input("分析したい人のscreen_nameを入力")
api = getApiInstance()分析したいユーザのスクリーン名を入力できるようinput関数を使っています。対象ユーザの@以下を入力すれば、分析できます。(ブロックされていなければですが。)
先ほど作成した関数getApiInstanceで、認証を行います。
認証するユーザと対象ユーザ間のフォロー関係に関わらず、分析ができます。
--6. フォローユーザ、フォロワーの作成日時分布
#--------------------フォロ-ユーザの作成日時分布------------------------------
f_info_list = getFollow_info(Api = api, Id = screen_name)
df = pd.DataFrame(f_info_list,columns=["user_screen_name","created_at"])
df =df.loc[:,["created_at"]]
df.groupby(df["created_at"].dt.year).count().plot(kind="bar")
plt.pyplot.savefig("follow_created_time.png") 先ほど作成したgetFollow_infoに、apiとスクリーン名を送り、フォローユーザのリスト取得します。
dataframeに変換し、アカウント作成日時(created_at)だけを取得、groupbyで集計しプロットします。ここで、dt.yearとすることで年のdatetimeプロパティにアクセスできます。日ごとの分析にしたい場合は、dt.dayを使えばできます。
https://www.it-swarm.dev/ja/python/pandas%E3%81%AF%E3%80%81%E6%97%A5%E4%BB%98%E3%81%AE%E3%83%92%E3%82%B9%E3%83%88%E3%82%B0%E3%83%A9%E3%83%A0%E3%82%92%E3%83%97%E3%83%AD%E3%83%83%E3%83%88%E3%81%A7%E3%81%8D%E3%81%BE%E3%81%99%E3%81%8B%EF%BC%9F/1050563155/
--7. 相互フォロワーチェック
#--------------------相互フォロワー調査----------------------------------
df = pd.DataFrame(f_info_list,columns=["user_screen_name","created_at"])
df =df.loc[:,["user_screen_name"]]
users_a = list(df["user_screen_name"])
friends_list=[]
with open('./friends_list.csv', 'w') as f:
writer = csv.writer(f)
for user_a in users_a:
a = api.show_friendship(source_screen_name=user_a, target_screen_name=screen_name)
#-a[1]:リストで取り出し、a[0]:タプルで取り出し
if a[1].following: #-フォローしているかチェック
friends_list.append(user_a)
print(user_a)
with open('./friends_list.csv', 'a',newline="") as f:
writer = csv.writer(f, delimiter=",")
writer.writerow([user_a])--6で作成したフォロワーリストをもとに、フォローバックされているかをチェックして、相互フォローを確認します。
少し前までは、API.exists_friendshipで簡単にチェックできたらしいのですが、今はこの関数は使えないようです。(2020/6/14時点)
そのため、api.show_friendshipを用いました。source_screen_nameがtarget_screen_nameをフォローしていれば値が返ってきます。if分で確認し、フォローしていればappendでリストに追加しています。最後にcsvで保存しています。
--8. タイムラインテキストをwordcloudで可視化
#--------------------ツイートワード分析----------------------------------
columns = ["tweet_at","text"]
df = pd.DataFrame(columns=columns)
df = gettimeline_info(api, screen_name,df,columns)
#-wordcloudeでtext可視化
delete_list=["\n","/","#","https","co","こと","ツイート"] #-削除リスト ]
text=list(df.loc[:,["text"]]["text"]) #-text列だけ抜き出し、リストに
wa(delete_list, text) #-別途waという関数作成必要先に作ったgettimeline_infoで指定ユーザのタイムラインを、dfで取得しています。今回は、tweet_at(ツイート日時)とtext(ツイート内容)を取得。その後、wordcloudeで可視化しました。リツイート内に含まれる@RTや頻出単語は、delete_listで除外することで有意のある単語を抽出しています。
--9. タイムラインの日時から、活動傾向を分析
#--------------------ツイート日時分析----------------------------------
#-曜日ごとの表示
df =df.loc[:,["tweet_at"]] #-特定列の抽出
df.groupby([df["tweet_at"].dt.weekday_name]).count().plot(kind="bar", fontsize=5)#.dtを使用すると、datetimeプロパティにアクセス,datetime64[ns]
plt.pyplot.savefig("tweet_week.png")
#-平日の時間分布
df_w = df[df["tweet_at"].dt.weekday_name!=("Sunday"or"Saturday")]
df_w.groupby([df_w["tweet_at"].dt.hour]).count().plot(kind="bar")
plt.pyplot.savefig("tweet_hour_weekday.png")
#-土日の時間分布
df_h = df[df["tweet_at"].dt.weekday_name==("Sunday"or"Saturday")]
df_h.groupby([df_h["tweet_at"].dt.hour]).count().plot(kind="bar")
plt.pyplot.savefig("tweet_hour_holiday.png")最後に、曜日のツイート数、平日・土日それぞれでのツイート日時をgroupbyで集計しプロットしました。
■実行結果
私のツイッターのアカウントで、アカウント分析を行ってみました。
①指定ユーザのフォローユーザの作成日時の分布作成

2018年に、アカウントを作成したユーザを主にフォローしているようです。この世の真実をあばいているラプトブログを拡散している方は2018年から活動されている方が多いので。
②指定ユーザのフォロワーの作成日時の分布作成
省略します
③指定ユーザの相互フォロワーリスト作成
省略します
④指定ユーザのツイート傾向分析
-ツイート時間分布(曜日、平日、土日)
曜日

平日

土日
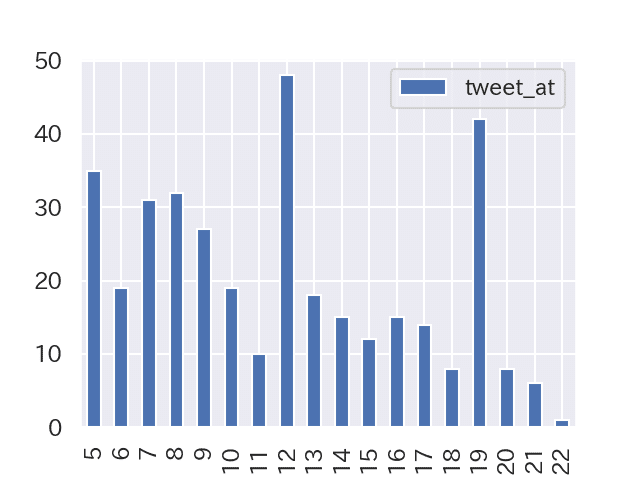
金曜以外は精力的に活動していますね^^
会社員なので、平日は、朝、昼休み、夜にツイートしているようです。
土日はほぼ全時間で活動し、午前のほうが精力的に活動しているようです。23時~5時までは活動ゼロですね^^
いろいろわかりますね。すごい!
-ツイートワード可視化

真実、コロナ、ウソ、ガン、原発、不安あたりが頻出ワードですね。
私がよくツイートしている内容は、
・#コロナはウソ
・#ガンはウソ
・#原発も原爆もウソ
・#真実を知って・・・
・#不安にならないように・・・
ですので、あっていますね。
■最後に
最後までお読み頂き、ありがとうございます。
データをグラフにすると色々見えてきて、面白いですね。
コマンド1つで、簡単なツィート分析ができるようになり、工作員と戦ういい武器となればと思っています。
今回の記事をお読み頂いた、プログラマーの方、ITスキル、データ分析に興味をお持ちの方々、その得た知識を世のために使ってみませんか?
この世を統治している上級国民たちは、我々を奴隷のように扱っています。苦労して身に着けたITスキルを、利益を搾取するだけの上級国民のためにささげるのではなく、希望をもって生きることができる世の中を作るために使ってみませんか?
まずは、この世のウソと真実を知ってみませんか?
なぜ、こんなにも生きにくい世の中なのか?
なぜ、どんなに仕事をしても給料が上がらないのか?
なぜ、何をしても満たされないのか?
真実を知れば、本当に大事なことが見えてきます。
希望をもって生きていけるようになります。
まずは、以下の動画から真実を知ってみて下さい。
多くの方が、真実に導かれますように(^^)
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★
誰でも世界を変えられる
http://rapt-neo.com/?p=39134
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★
■完成したコード
# -*- coding: utf-8 -*-
import tweepy
import pandas as pd
import matplotlib as plt
from datetime import timedelta
from word_analyze import wa #-独自に作成した関数wa
import csv
#-Twitter APIを使用するためのConsumerキー、アクセストークン設定
def getApiInstance():
Consumer_key = ***取得したキーを入力***
Consumer_secret = ***取得したキーを入力***
Access_token = ***取得したキーを入力***
Access_secret = ***取得したキーを入力***
#-認証
auth = tweepy.OAuthHandler(Consumer_key, Consumer_secret)
auth.set_access_token(Access_token, Access_secret)
api = tweepy.API(auth ,wait_on_rate_limit = True, wait_on_rate_limit_notify=True)
return api
#-フォローユーザ_info
def getFollow_info(Api, Id):
followers_ids = tweepy.Cursor(Api.friends_ids, id = Id, cursor = -1).items()
followers_ids_list = []
try:
for followers_id in followers_ids:
user = Api.get_user(followers_id)
user_info = [user.screen_name, user.created_at]
followers_ids_list.append(user_info)
print('----------')
print(user_info)
except tweepy.error.TweepError as e:
print(e.reason)
return followers_ids_list
#-フォロワー_info
def getFollowers_info(Api, Id):
#-Cursorを使ってフォロワーのidを逐次的に取得
followers_ids = tweepy.Cursor(Api.followers_ids, id = Id, cursor = -1).items()
followers_ids_list = []
try:
for followers_id in followers_ids:
user = Api.get_user(followers_id)
user_info = [user.screen_name, user.created_at]
followers_ids_list.append(user_info)
print('----------')
print(user_info)
except tweepy.error.TweepError as e:
print(e.reason)
return followers_ids_list
#-timeline_info
def gettimeline_info(api, screen_name,df,columns):
num=0
pages=[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17]
for page in pages:
tweets=api.user_timeline(screen_name, count=200, page=page) #-1回200,pageはページの番号
for t in tweets:
t.created_at+=timedelta(hours=9) #-JSTに
se = pd.Series([t.created_at, t.text], columns) #-1行作成
df = df.append(se, ignore_index=True) #-結合
print('----------')
print(t.created_at)
print("num:",num,"page:",page)
num+=1
print(num, 'ツイート表示しました。')
return df
def main():
screen_name = input("分析したい人のscreen_nameを入力")
api = getApiInstance()
#--------------------フォロ-ユーザの作成日時分布------------------------------
f_info_list = getFollow_info(Api = api, Id = screen_name)
df = pd.DataFrame(f_info_list,columns=["user_screen_name","created_at"])
df =df.loc[:,["created_at"]]
df.groupby(df["created_at"].dt.year).count().plot(kind="bar")
plt.pyplot.savefig("follow_created_time.png")
#--------------------フォロワー作成日時分布------------------------------
f_info_list = getFollowers_info(Api = api, Id = screen_name)
df = pd.DataFrame(f_info_list,columns=["user_screen_name","created_at"])
df =df.loc[:,["created_at"]]
df.groupby(df["created_at"].dt.year).count().plot(kind="bar")
plt.pyplot.savefig("follower_created_time.png")
#--------------------相互フォロワー調査----------------------------------
df = pd.DataFrame(f_info_list,columns=["user_screen_name","created_at"])
df =df.loc[:,["user_screen_name"]]
users_a = list(df["user_screen_name"])
friends_list=[]
with open('./friends_list.csv', 'w') as f:
writer = csv.writer(f)
for user_a in users_a:
a = api.show_friendship(source_screen_name=user_a, target_screen_name=screen_name)
#-a[1]:リストで取り出し、a[0]:タプルで取り出し
if a[1].following: #-フォローしているかチェック
friends_list.append(user_a)
print(user_a)
with open('./friends_list.csv', 'a',newline="") as f:
writer = csv.writer(f, delimiter=",")
writer.writerow([user_a])
#--------------------ツイートワード分析----------------------------------
columns = ["tweet_at","text"]
df = pd.DataFrame(columns=columns)
df = gettimeline_info(api, screen_name,df,columns)
#-wordcloudeでtext可視化
delete_list=["\n","/","#","https","co","こと","ツイート"] #-削除リスト ]
text=list(df.loc[:,["text"]]["text"]) #-text列だけ抜き出し、リストに
wa(delete_list, text) #-別途waという関数作成必要
#--------------------ツイート日時分析----------------------------------
#-曜日ごとの表示
df =df.loc[:,["tweet_at"]] #-特定列の抽出
df.groupby([df["tweet_at"].dt.weekday_name]).count().plot(kind="bar", fontsize=5)#.dtを使用すると、datetimeプロパティにアクセス,datetime64[ns]
plt.pyplot.savefig("tweet_week.png")
#-平日の時間分布
df_w = df[df["tweet_at"].dt.weekday_name!=("Sunday"or"Saturday")]
df_w.groupby([df_w["tweet_at"].dt.hour]).count().plot(kind="bar")
plt.pyplot.savefig("tweet_hour_weekday.png")
#-土日の時間分布
df_h = df[df["tweet_at"].dt.weekday_name==("Sunday"or"Saturday")]
df_h.groupby([df_h["tweet_at"].dt.hour]).count().plot(kind="bar")
plt.pyplot.savefig("tweet_hour_holiday.png")
#------------------------------------------------
input("何かおすと終了します")
if __name__=='__main__':
main()