
異常検知始めました。

こんばんは!データサイエンティストの力太郎です。
みなさんは深夜に無性に音声データの異常検知するアルゴリズムを作りたくなったことはありますか?
私はいまその状態です。
深夜だけに深層学習のAutoEncoderを使って深夜テンションで実装します。
はじめてなので調べながらやっていきます。
深層学習を使った異常検知ってこうやってやるんだぁーという感じで”ざっくり”と分析の流れを一緒に捉えて行きましょう。
【本Noteの対象読者】
異常検知が出来るようになりたいDS初心者
異常検知初心者のレベル感を把握したい玄人
1.やりたいこととデータの把握
今回は工場の稼働音データを使って、異常を検知するというテーマで分析をします。正常音300データで学習した後に、異常が混じった学習してない未知のデータについて異常か否かを判定します。Signateというデータ分析コンペサイトを参考にしています。
また今回はF1 Scoreでモデルを評価します。F1 Scoreの詳しい説明は割愛しますが、要するに正常も異常もバランス良く予測するモデルを作れということです。他人の記事ですが分かりやすく説明されていたので記事を紹介しますね。
2.データの可視化
テーマとモデルの評価指標を明確にしました。次は実際にデータを確認してみましょう。

上記で正常データと異常データをグラフにしました。直感的には正常音のデータと異常音のデータの違いは分からないですね。実際に統計量を確認してみましょう。

明らかに異常の時は振幅に差が出ることが分かりますね。本来であればデータをもっと詳しく理解するべきかもしれませんが、AutoEncoderは特徴量を自分で作らなくても予測できるので、これぐらいにしておきましょう。雑で怒られそうですが、流れを知りたいので早速モデルをつくっていきます。
3.モデル作成(AutoEncoder)
AutoEncoderは、入力データを内部の次元表現に圧縮するエンコーダー部分と、その低次元表現から元の入力データを再構築しようとするデコーダ部から構成されます。一度データを圧縮することでデータの特徴を掴むことが出来ます。正常データにフィッティングしたモデルは、異常データを入力すると上手く予測できません。この時の上手く予測出来なかった度合いを異常度として、異常検知を行うという訳です。今回は一旦以下のような形で学習を進めていきます。
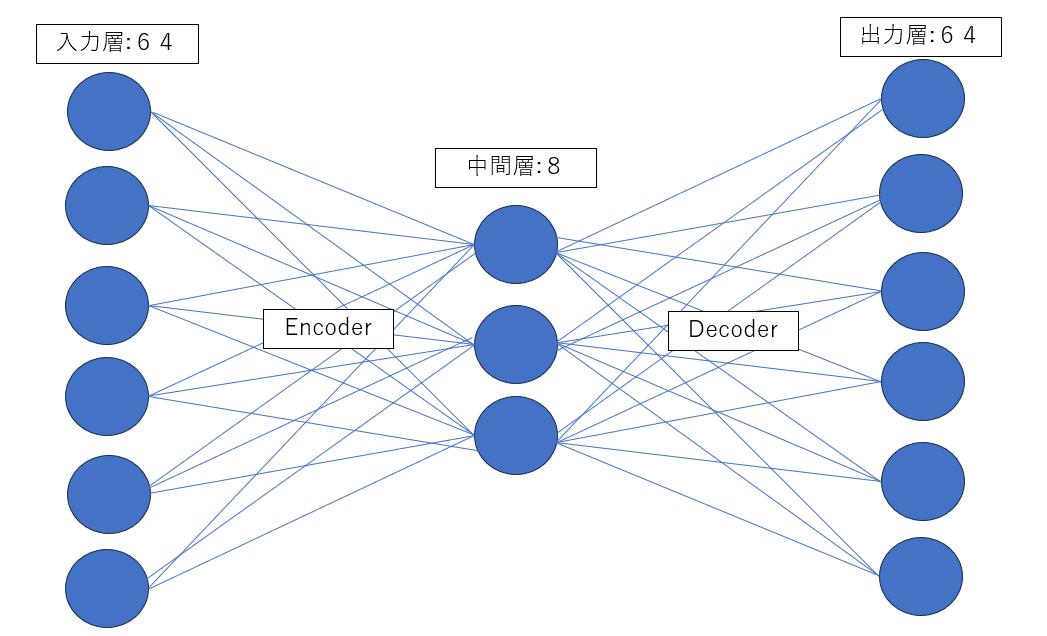
今回のデータは一つの塊が16000データです。このことを踏まえてコーディングします。活性化関数にはrelu関数を使います。なぜrelu関数にするの?という質問は初心者なので受け付けません。(ほかにもシグモイド系、EUL系などがあります)一旦今後の課題としてモデルを作らせて下さい。以下コードです。
from keras.models import Sequential
from keras.layers import Dense, BatchNormalization, Activation
# データの次元数を設定
inputDim = 160000
model = Sequential()
# Encoder部分
model.add(
Dense(64, input_shape=(inputDim,))
) # 大きな入力サイズに対応するために、もう少し大きな層を使用
model.add(BatchNormalization())
model.add(Activation("relu"))
model.add(Dense(8)) # 圧縮された表現
model.add(BatchNormalization())
model.add(Activation("relu"))
# Decoder部分 (入力を再構成)
model.add(Dense(64))
model.add(BatchNormalization())
model.add(Activation("relu"))
# 元の入力次元と同じサイズの出力層
model.add(Dense(inputDim)) # 元の次元数に戻す
# モデルのコンパイル
model.compile(optimizer="adam", loss="mean_squared_error")モデルが出来ましたね。そしたら実際に学習させて、テストデータを入れてみましょう。以下でまず学習します。AutoEncoderは正常なデータだけで学習するモデルなので、X_trainで学習してX_trainで評価します。
history = model.fit(X_train, X_train, epochs=10, batch_size=50, validation_split=0.2)では実際に予測してみましょう。テストデータは正常150、異常50のデータについて予測を行います。df_testというデータフレームにラベル付きのtestデータが入っています。
from sklearn.metrics import confusion_matrix, accuracy_score, f1_score
# ラベル列を除外してテストデータを準備
test_X = df_test.drop(columns=["label"]).values
# ラベルを取得
test_y = df_test["label"].values
# 予測(再構成)
test_pred = model.predict(test_X)
# 再構成誤差を計算
test_score = np.mean(np.square(test_X - test_pred), axis=1)
# 閾値を設定(例:再構成誤差の75パーセンタイル)
threshold = np.percentile(test_score, 75)
# 閾値を超えるものを異常と判定
pred_labels = np.where(test_score > threshold, 1, 0)
from sklearn.metrics import confusion_matrix, accuracy_score
# 混同行列を計算
conf_matrix = confusion_matrix(test_y, pred_labels)
print("Confusion Matrix:\n", conf_matrix)
# 精度を計算
accuracy = accuracy_score(test_y, pred_labels)
print("Accuracy:", accuracy)
# F1スコアを計算
f1 = f1_score(test_y, pred_labels)
print("F1 Score:", f1)何とかできましたね。今回は異常を判定する閾値を75%としました。
はたして結果は・・・
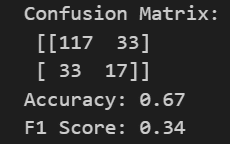
正解率67%!最初に作ったモデルとしてはまずまずではないでしょうか。
一旦疲れたので、この辺にして終わろうかと思います。
6.まとめ
いかがだったでしょうか。もっとハイパーパラメータチューニングしなくていいの?とか色々突っ込みはありそうですが、何とかモデルをつくれました。初学者にとっては一旦動くことで、詳しく勉強しようと思えるので、こんな感じで良いと思ってます笑
一方でモデル改善が予測の醍醐味でもあるので、続編でそのあたりやろうかなと思います。
読んで頂きありがとうございました!
この記事が気に入ったらサポートをしてみませんか?