


記事一覧

【ComfyUI】ローカル最高性能のi2v動画生成「CogVideoX-5B-I2V」をためす
「CogVideo」シリーズは、ローカルで使える動画生成AIの中で現時点で最も高性能なモデルです。ただ従来のモデルはText-To-Video(テキスト指示からの動画生成)に用途が限られていました。
今回、新たにImage-To-Video(画像からの動画生成)に対応した「CogVideoX-5B-I2V」が公開されたので、ComfyUIで試してみました。
本記事は2024/9/21時点のCo

【ComfyUI】FLUX.1 の生成画像を「EasyAnimate」で動かす
FLUX.1の登場により、ローカルで高品質な画像生成が楽しめるようになりました。FLUX.1で生成した画像をそのままローカルで動画化できればもっと嬉しいです。
ということで、Alibabaグループが開発しているオープンウェイトの動画生成AI「EasyAnimate」をComfyUIで試してみました。
最大144フレームの動画が生成でき、Stable Video Diffusionなど他のIma

【AIアニメ】ComfyUIとSunoでシンプルなアニメMVをつくる
最近、音楽生成AIサービスのレベルが大きく上がっているようです。半年ほど前に話題になった「Suno」と後発の「Udio」が機能を競い合っていて、生成の質も使い勝手も大幅に改善しています。
今回Sunoのv3.5で遊んだので、例によってComfyUIで生成した動画素材と楽曲を合わせてMV風のシンプルなアニメにしてみました。
この記事はその作業メモです。
Suno(v3.5)で楽曲を生成する

【AI動画生成】ComfyUIでポカリスエットCM風の動画をつくる
生成AI用の画像/映像作成ツール「ComfyUI」とその拡張機能の「ComfyUI-AnimateDiff-Evolved」を使って、CM風のショート動画を作ってみたので、その時の反省メモです。
実写系の動画生成もちゃんと試しておこうと思い、一昔前のポカリスエットのCMのイメージで30秒程度の動画を作ってみました。
カット1:砂浜にとめた自転車
冒頭のカットは、自転車の写ったフリー画像をお借
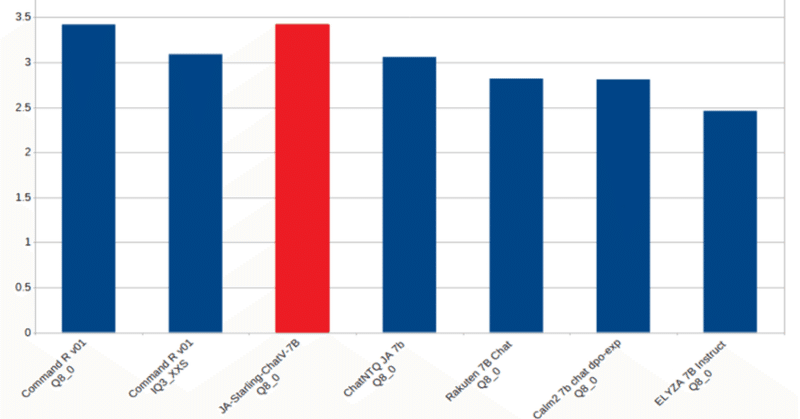
饒舌な日本語ローカルLLM【Japanese-Starling-ChatV-7B】を公開しました
最近LLMコミュニティから生まれた小型MoEモデル「LightChatAssistant-2x7B」の日本語チャット性能がとても良いため、モデル作者さんが用いた手法(Chat Vector+MoEマージ)を後追いで勝手に検証しています。
その過程で複数のモデルを試作したところ、7Bクラスとしてはベンチマークスコアがやたら高いモデルが出てきたので「Japanese-Starling-ChatV-7

【AIアニメ】ComfyUIではじめるStable Video Diffusion
11月21日にStabilityAIの動画生成モデル「Stable Video Diffusion (Stable Video)」が公開されています。
これによりGen-2やPikaなどクローズドな動画生成サービスが中心だったimage2video(画像からの動画生成)が手軽に試せるようになりました。
このnoteでは「ComfyUI」を利用したStable Videoの使い方を簡単にまとめま

AnimateDiffでドット絵アニメをつくる / Pixel Art with AnimateDiff
AnimateDiffでドット絵アニメを作ってみたらハマったので、ワークフローをまとめてみました。
ComfyUI AnimateDiffの基本的な使い方から知りたい方は、こちらをご参照ください。
1. カスタムノード特別なカスタムノードはありません。以下の2つだけ使います。
https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved

ComfyUI AnimateDiff + LCM-LoRAによる高速な動画生成を試す
StableDiffusionを高速化するLCM-LoRAを応用したAnimateDiffワークフローが話題になっていたので、さっそく試してみました。
LCM-Loraを使うと8以下のStep数で生成できるため、一般的なワークフローに比べて生成時間を大幅に短縮できるようです。
ワークフローComfyUI AnimateDiffの基本的な使い方から知りたい方は、こちらをご参照ください。
今回試

【AIアニメ】AnimateDiffでアニメが作れるか?(2)
前回の記事のつづきで、AnimateDiffをつかった短い「アニメ」を試作しています。
一部の場面ではキャラにリップシンク(口パク)をさせたいので、動画と並行して声(セリフ)の生成にも手をつけます。
カット「もう11月だよ」
「ちょっと前まであんな暑かったのに…」と言う姉(りりこ)に対して、妹(みいこ)が返答する場面です。
カット2と同じくモデルは「Counterfeit-V3.0」で、オ

GPT 3.5-turboが20Bパラメータという話の後日談
TL;DR 論文著者によれば「論文に書いたパラメータ数の出所はForbesの記事であり、その記事にソースの記載はない」とのこと。
10月26日にarxivに掲載された論文で、GPT 3.5-turboのパラメータ数が200億(20B)という記載があり、数日前に話題になった。
論文著者が(OpenAIと提携している)Microsoftの研究者だったこともありバズったものらしい。
この件に関して

【AIアニメ】AnimateDiffでアニメが作れるか?(1)
AnimateDiffを使うと数秒のアニメーションなら手軽に作れます。これらを編集してセリフをつければ、ちょっとしたショートアニメ作品も作れるのでは?と思いました。
以前に試したもの
アニメ用のAI音声合成(Koeiromap)などは、以前の記事で試したことがあります。当時の投稿はこちら。
ただ肝心のアニメーションについては、AI動画生成がまだ難しかったので、静止画を中心とした編集にせざるを
ComfyUI-LCMによるVid2Vidの高速変換を試す(Latent Consistency Models)
Latent Consistency Models(LCM)は、最小限のステップ数で迅速に推論できる新たな画像生成モデルです。
例えば768x768の画像が2~4ステップ程度で生成できるとのこと(Stable Diffusionだとざっくり20ステップくらい)。
このLCMをComfy UIの拡張機能として実装したのが「ComfyUI-LCM」です。
Comfy UI-LCMを使ったVid2