【ローカルLLM】llama.cppの「投機的サンプリング」を試す
llama.cppに「Speculative Sampling(投機的サンプリング)」という実験的な機能がマージされて話題になっていた。
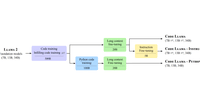
この手法については、OpenAIのKarpathy氏が以下のポストで解説している。
この説明を素人頭で解釈するに、人間がスマホの予測変換を利用して文章を書くのに似ている。
大型のLLMでイチから推論させると時間がかかるので、先に軽量のLLMに候補となるトークンを提案させる。メインのLLMは、提案されたトークンで良いなら、そのまま採用す