
Yahoo!知恵袋から子育ての悩みを分析してみた

子育て中の主婦が、Yahoo!知恵袋の投稿をもとに「子育て・育児の悩み」をnlplotで可視化、BERTopicsでクラスタリングしてみました。
テキストアナリティクスやBERTopicにご興味のある方、子育てについてどんな相談がされているのかにご興味ある方向けです。
かなり長文なので、目次からご興味のあるセクションに飛んでください🖱️
1. はじめに
今回のテーマ
第一子が誕生してからというもの、インターネットが大親友になった絶賛子育て中の私。
育休、何ヶ月取ろう?寝ない…なんで?
ミルクの飲み具合、足りてる?保育園見学っていつするの?
夜中に熱出た!イヤイヤ期、詰んだ…などなど、
子供が生まれてから新種の悩みが増え、すぐネット検索で対処法や解決策を探してしまいます(現在進行形)。
「子育ての悩みは一生尽きない」と言った母の言葉が響く、そんな今日この頃。巷では異次元の少子化対策が話題ですが、ふと「皆は実際、子育てのどんなことで悩んでいるのだろう?」と思いました。
ということで、今回はYahoo!知恵袋の投稿をもとに、
一体どんな子育て・育児に関する相談があるのか?をBERTopicを使ってクラスタリングしてみました。

プログラミング環境
MacBook Air (M1)で、PyCharmまたはGoogle Colaboratory上でPython3を使用しました。
私のプログラミングレベル
Python初心者のため、Aidemyで4ヶ月ほど講座受講しました。
2. 作成したプログラムと流れ
分析までの流れ
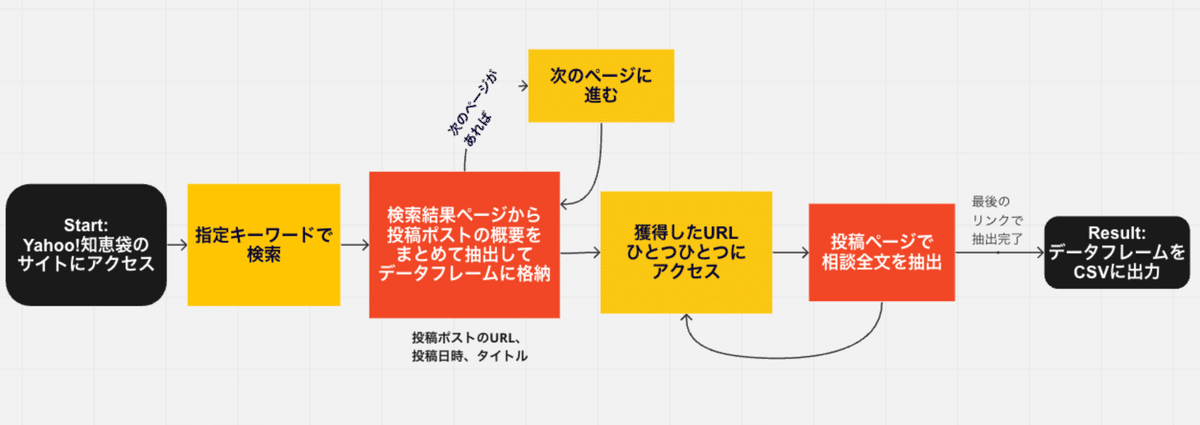
今回は下図の流れで分析を行いました。

使用したコードのファイルは、こちらのGitHubから確認できます。
2-1. スクレイピングでデータ取得
まずは分析に必要なデータを集めました。
TwitterかYahoo!知恵袋を検討していたのですが、今年からTwitter APIが有料となりスクレイピングが難しくなったようです。
元々、子育ての「悩み・相談」を深掘りしたかったので、今回はYahoo!知恵袋からデータを抽出しました。
こちらのコードをベースに、Seleniumを使ってYahoo!知恵袋から投稿文をスクレイピングするコードを作成しました。
Seleniumとは?
元々はWebアプリケーションの操作を自動化するためのテストツールで、人に代わってWebブラウザなどでの操作を実行してくれます。
Seleniumを使うことで、Yahoo!知恵袋のサイトにアクセス→キーワード検索→検索結果データの取得を自動化できました。
スクレイピングのコードの流れは、下記図のようになっています。
スクレイピングのコード
まずはSeleniumからwebdriverをインポートし、ブラウザを起動しています。(注:PyCharmでローカル環境で実装したので、別途事前にSeleniumをインストールしました。)
# ---------------------------------------------------------------------------------------
# ブラウザ起動に使うライブラリをインポート
# ---------------------------------------------------------------------------------------
from selenium import webdriver
import time
from time import sleep
# ---------------------------------------------------------------------------------------
# 処理開始
# ---------------------------------------------------------------------------------------
# ブラウザをheadlessモード実行
print("\nブラウザを設定")
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('chromedriver', options=options)
driver.implicitly_wait(10)
# サイトにアクセス
print("サイトにアクセス開始")
# 特定のURLでブラウザを起動する - Google Japanサイト
driver.get("https://www.google.com/?hl=ja")
time.sleep(3)
# サイトのタイトルでGoogleが起動されているか確認
print("サイトのタイトル:", driver.title)
print("\nお疲れさまです。\n処理が完了しました。")次にスクレイピングの際に使う関数を3つ作成しました。
analysis_action 関数
検索結果ページから、検索に使用したキーワード、検索結果ページで表示される投稿のリンク先、投稿日時、投稿タイトルを取得します。
# -----------------------------------------------------------------
# 関数の設定
# -----------------------------------------------------------------
def analysis_action():
# まず検索結果ページに出てくる投稿リンクを取得
xpath1 = "//li/h3/a"
elems = driver.find_elements(by=By.XPATH, value=xpath1)
# 取得した要素を1つずつ表示
out_puts = []
if (len(elems) == 0):
# 検索結果ページからリンクがうまく取れていない場合はエラー分を出力(デバグ用)
print("ページは存在しないよ〜")
else:
# 検索結果ページからリンクが取得できていたら各情報をout_dicに格納していく
for i, elem in enumerate(elems):
out_dic = {}
# 使用キーワードを格納
out_dic['query_key'] = keyword
# 投稿ポストのURLを格納
url = elem.get_attribute('href')
out_dic['rs_link'] = url
# 投稿ポストの見出しを格納
out_dic['summary'] = elem.text
# 投稿ポストの日時をCSS_SELECTORで見つけて格納
css_date = f'#sr > ul > li:nth-child({i + 1}) > p.ListSearchResults_listSearchResults__information__3uanU > span.ListSearchResults_listSearchResults__informationDate__10t00 > span:nth-child(3)'
date = driver.find_element(by=By.CSS_SELECTOR, value=css_date)
out_dic['post_date'] = date.text
out_puts.append(out_dic)
return out_putsnext_page_action関数
検索結果ページで、「次のページへ」がある場合に次ページへ遷移する。
次のページがない場合は、「次のページはないよ〜」とメッセージを出力して教えてくれます。
# -----------------------------------------------------------------
def get_post(url):
class_name = 'ClapLv1TextBlock_Chie-TextBlock__3X4V5'
driver.get(url)
elements = driver.find_elements(by=By.CLASS_NAME, value=class_name)
texts = []
for element in elements[:1]:
texts.append(element.text)
return texts
get_post関数
獲得した投稿ポストのリンクにアクセスして、投稿の本文を抽出します。
# -----------------------------------------------------------------
def next_page_action():
# 現在のページから次のページを読み込むアクションを実行する
rtn = False
# 次へボタンのクリック
elems = driver.find_elements(By.XPATH, '//*[@id="pg_low"]/div/a[*]')
# 現在のページを出力
print("ページ遷移前のurl:")
print(driver.current_url)
# 次のページがない場合にメッセージを出力(デバグ用)
if (len(elems) == 0):
print("次のページは存在しないよ〜")
else:
for elem in elems:
if (elem.text != "次へ"):
continue
url = elem.get_attribute('href')
driver.get(url)
rtn = True
break
return rtn関数が出来上がったら、下記コードで早速スクレイピングしていきます。
# -----------------------------------------------------------------
# スクレイピングの実行
# -----------------------------------------------------------------
# さらに必要なライブラリのインポート
from selenium.webdriver.common.by import By
#from selenium.webdriver.support.select import Select
import pandas as pd
# -----------------------------------------------------------------
# スクレイピングするサイトのURL、使用キーワード、検索するページ数を指定
SQRAPING_URL = "https://chiebukuro.yahoo.co.jp/"
PAGE_LIMIT = 100
KEYWORDS = ['子育て', '育児', '子育て 悩み', '育児 悩み']
# !curl ipinfo.io
for keyword in KEYWORDS:
# キーワードを出力
print(keyword)
# 指定URLにアクセス
driver.get(SQRAPING_URL)
print("website accessed successfully")
# 取得したい要素のXPathを設定、要素を取得
# 検索ボックスのXpath
xpath999 = '//*[@id="Top"]/div/div[1]/div[2]/nav/div[1]/div/div/div/input'
search_boxes = driver.find_elements(by=By.XPATH, value=xpath999)
if len(search_boxes) > 0:
search_box = search_boxes[0]
# キーワードを入れて検索
search_box.send_keys(keyword)
# 検索ボタンが入っている入れ物を探す
search_button_container = driver.find_elements(By.CLASS_NAME, "SearchBox_searchBox__wrap__2zBaE")
# 検索ボタンが入っている箇所を見つかったら、そこから検索ボタンを取得してクリックする
if len(search_button_container) > 0:
search_button = search_button_container[0].find_element(By.CLASS_NAME, 'cl-noclick-log.SearchBox_searchBox__inputButton__2OXXW')
search_button.click()
sleep(2)
# 想定しているページで想定したキーワードで検索できているかを、スクショでチェック
driver.save_screenshot(keyword + "screenshot.png")
else:
# 検索ボタンが見つからない時は下記メッセージを出力(デバグ用)
print("No search button container found.")
else:
# 検索ボックスが見つからない時は下記メッセージを出力(デバグ用)
print("No search boxes found.")
# 検索結果が表示されたら、検索結果の各ページから要素を取得。
# 取得した要素をpandasに格納してcsvに書き出す
d = analysis_action()
analysis_list = []
text_list = []
#sort = Select(driver.find_element(By.XPATH, '//*[@id="SearchResults"]/div/div[2]/div[2]/div[2]/div/div/label/select'))
#sort.select_by_value('6')
# 前述したページ数の数だけ次のページに進んでいく
for page in range(PAGE_LIMIT):
print("ページ %dを実行中" % page)
sleep(5)
# 次のページに遷移する
rtn = next_page_action()
if rtn == False or page >= PAGE_LIMIT:
break
# 知恵袋の質問リストを格納する
if len(d) > 0:
analysis_list.extend(d)
df = pd.DataFrame(analysis_list)
# for page...で取得したリンクにひとつひとつアクセスして、投稿文を取得。
# 同じデータフレームに格納していく
for link in df['rs_link']:
text_list += get_post(link)
df['text'] = pd.DataFrame(text_list)
# キーワードごとにcsvに出力していく
csv_file_name = keyword + ".csv"
df.to_csv(csv_file_name, encoding="utf_8_sig")
driver.close()
driver.quit()途中経過
「子育て」「育児」「子育て 悩み」「育児 悩み」の検索結果をスクレイピングしたところ、計4000件ありました。
漠然と、「1万件くらいあった方が良いかな?」と思い、更に投稿ポストを集めることにしました。
今度は、検索後に結果をソートしてから(投稿日が新しい順・閲覧数が多い順)、データ抽出していきます。
まず追加のライブラリをインポート
from selenium.webdriver.support.select import Select次に、if len(search_button_container) > 0: のセクションに、下記コードを追記して実行。
if len(search_button_container) > 0:
search_button = search_button_container[0].find_element(By.CLASS_NAME, 'cl-noclick-log.SearchBox_searchBox__inputButton__2OXXW')
search_button.click()
sleep(2)
# 追記部分
sort = Select(driver.find_element(By.XPATH, '//*[@id="SearchResults"]/div/div[2]/div[2]/div[2]/div/div/label/select'))
# 20 = sort by newer post dates, 6 = sort by # of views
sort.select_by_value('20')
sleep(2)
driver.save_screenshot(keyword + "screenshot.png")最後に、ソートした結果からデータを抽出。
csv_file_nameを少し変更して、それぞれを「Sort_by_latest_posts_子育て.csv」「Sort_by_views_子育て.csv」のように、別csvファイルとして保存しました。
csv_file_name = "Sort_by_latest_post_" + keyword + ".csv"データチェック
全てのCSVファイルが出力された後、とりあえず抽出したデータファイルを全てざっと見てみました。
思った感じに抽出できていましたが、同じ投稿を複数ファイルで見かけ、データの重複を確認しました(データ前処理セクションで詳しく)。
データ前処理に入る前に、各ファイルを再度データフレームとして読み込み、全てのデータをdf_allと名付けた新規データフレームに格納しました。
frames = [df1, df2, df3, df4, df5, df6, df7, df8, df9, df10, df11, df12]
df_all = pd.concat(frames, ignore_index=True)前処理に入る前にデータフレームの形をチェック。
合計ポスト数は12040件でした。
→ 2-2. データ前処理に続く
おまけ:スクレイピングでの学び - Google Colaboratoryではアクセスできないサイトもある?
最初はGoogle Colaboratoryで実装していたのですが、スクレイピングがやっとできた!と思った翌日、何度試しても返り値が空白に。大ピンチ。
サイトの仕様が変わったのかチェックしたり、1日かかって色々模索しました。
試してみたやったこと
一つ一つのコードブロックが実行されるか確認作業
関数のアウトプットが、ちゃんと期待しているものと同じか再度確認
そもそもアクセスしているページが自分の思っていページと相違ないかを、driver.save_screenshot("test.png")を使ってチェック。
最後のdriver.save_screenshotで確認したところ、「Yahoo!知恵袋はイギリス・EU圏からはアクセスできないよ!」というページになっていました。Google Colaboratoryのリージョン?が変わったのか、ヨーロッパからサイトにアクセスしていたようです。
Google Colaboratoryでリージョン変更はどうやら難しいようだ…ということで、PyCharmを使ってローカルPCからやってみるとできました!
2-2. データの前処理
抽出したデータファイルで投稿文を確認していくなかで、以下の点を確認できたので、クレンジングしていきました。
重複投稿を削除
投稿日時から投稿年だけを抽出
全角、半角の統一と重ね表現の除去
URLの削除
記号の削除(参考コード)
# ---------
# 重複投稿を削除
# ---------
# リンク、投稿見出し、投稿文での重複数をチェック
print("rs_link duplicates\n" + str(df_all.duplicated('rs_link').value_counts()))
print("summary duplicates\n" + str(df_all.duplicated('summary').value_counts()))
print("text duplicates\n" + str(df_all.duplicated('text').value_counts()))
# 投稿文がダブっているものを削除
df_all.drop_duplicates(subset='text', keep='first', inplace=True)
df_all.reset_index(inplace=True)
# 処理後のチェック
print(df_all.head(10))
print(df_all.tail(10))
print("df_all shape post cleaning duplicates \n" + str(df_all.shape))
# --------
# 投稿日時から投稿年を別途抽出
# --------
df_all['post_date'] = pd.to_datetime(df_all['post_date'])
df_all['post_year'] = df_all['post_date'].dt.year
print(df_all['post_date'].dtype)
df_all = df_all.sort_values(by=['post_date'])
# 処理後のチェック
print(df_all['post_date'].head(10))
# --------
# 全角、半角の統一と重ね表現の除去、URLの削除、記号の削除
# --------
# httpが含まれているか確認
print(df_all['text'].str.contains('http').sum())
# 必要ライブラリのインポート
import re
import neologdn
def cleaning_post(text):
#全角・半角の統一と重ね表現の除去
normalized_text = neologdn.normalize(text)
#URLの削除
text_without_url = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', '', normalized_text)
#記号、改行 \n の削除
code_regex = re.compile('[!"#$%&\'\\\\()*+,-./:;<=>?@[\\]^_`{|}~「」〔〕“”〈〉『』【】&*・()$#@。、?!`+¥%]')
text_without_url = code_regex.sub(' ', text_without_url)
tmp = re.sub(r'(\d)([,.])(\d+)', r'\1\3', text_without_url)
text_replaced = tmp.replace("\n", ' ').replace('\r', ' ')
return text_replaced
# 関数の適応
df_all['text_clean'] = df_all['text'].apply(cleaning_post)数字の置換も検討しましたが、年齢別の悩みなども見られたので、今回はとりあえず数字の置換なしのままにしています。
データチェック
全ての処理を終えて、投稿数を再チェック。
1916件削除され、残り10124件ありました。
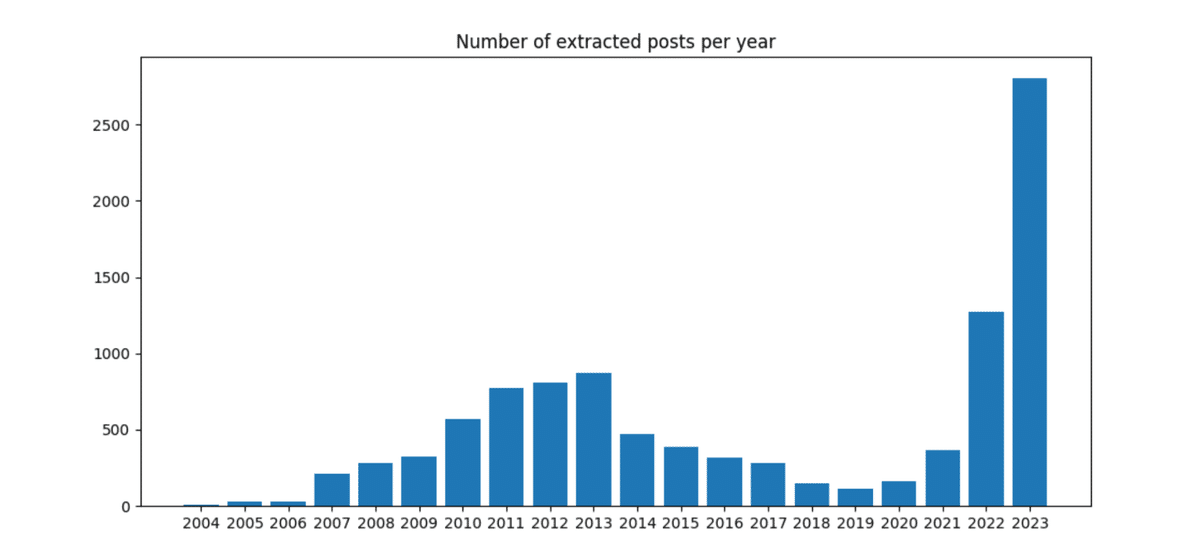
把握のため、投稿年の分布を可視化しました。
# ---------
import matplotlib.pyplot as plt
x = df_all['post_year'].unique().tolist()
y = df_all.groupby('post_year')['post_year'].count()
plt.bar(x, y, width=0.8, bottom=None, data=None, tick_label=x)
plt.title('Number of extracted posts per year')
plt.show()
# ---------スクレイピングで投稿日時の新しい順でも取得しているので、2023年が圧倒的に多めとなりました。
データチェック時に、投稿文が結構長いなと気付いたので、平均文字数も確認しました。平均540文字と、長めです。
# ---------
import numpy as np
df_all["text_counts"] = df_all["text"].apply(lambda x: len(x))
print("Average length of posts")
print(df_all['text_counts'].mean())2-3. 形態素解析
今回は投稿をクラスタリングする前に、ざっとどんな単語が使われているのか可視化したかったので、可視化の準備としてMecabを使って形態素解析を実行しました。
形態素解析とは?
形態素解析は、自然言語処理(Natual Language Processing / NLP)の一部です。
日頃私たちが使っている言葉(=自然言語)を、言語において意味を持つ最小の単位(=形態素)にまで分解し、一つ一つの品詞を判別させる文字列抽出法です。
日本語の形態素解析では、JanomeやMecabというライブラリを使って可能です。
実際に形態素解析をしてみましょう。
例えば、「今日の夕飯はガパオライスにしよう。」を Mecabで解析すると、下画像のような結果が帰ってきます
import MeCab
tagger = MeCab.Tagger()
text = "今日の夕飯はガパオライスにしよう。"
result = tagger.parse(text)
print(result)今日 名詞,副詞可能,*,*,*,*,今日,キョウ,キョー
の 助詞,連体化,*,*,*,*,の,ノ,ノ
夕飯 名詞,一般,*,*,*,*,夕飯,ユウハン,ユーハン
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
ガパオライス 名詞,一般,*,*,*,*,*
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
しよ 動詞,自立,*,*,サ変・スル,未然ウ接続,する,シヨ,シヨ
う 助動詞,*,*,*,不変化型,基本形,う,ウ,ウ
。 記号,句点,*,*,*,*,。,。,。
EOSMecabを使って、投稿文を形態素解析してみる
今回の可視化では「名詞、動詞、形容詞、固有名詞」のみを使います。
Mecabで形態素解析した後に、「名詞、動詞、形容詞、固有名詞」の原型のみを抽出する関数を組みました。
今回は新語なども拾うMecabの辞書「mecab-ipadic-neologd」に設定して実行しました。こちらを参考にさせていただきました。
文章中でよく使われる単語「こと」「もの」などは抽出されないように指定しています。
# --------
# 形態素解析
# --------
import MeCab
def sep_by_mecab(text):
m = MeCab.Tagger ("-d/opt/homebrew/lib/mecab/dic/mecab-ipadic-neologd")
node = m.parseToNode(text)
word_list=[]
while node:
hinshi = node.feature.split(",")[0]
#名詞、動詞、形容詞のみを抽出する
if hinshi in ["名詞","動詞","形容詞","固有名詞"]:
#if hinshi in ["名詞", "動詞", "形容詞"]:
origin = node.feature.split(",")[6]
#抽出したくない単語を、stopwprdとして設定する
if origin not in ["*","する","いる","なる","てる","れる","ある","こと","もの"] :
word_list.append(origin)
node = node.next
return word_list
df_all['text_wakati'] = df_all['text_clean'].apply(sep_by_mecab)
print(df_all.head(10))
df_all.to_csv("all_parenting_concern_posts.csv", encoding="utf_8")
df_2023 = df_all.query('post_year == 2023').reset_index()
print(df_2023.shape)
df_2023.to_csv("2023_parenting_concern_posts.csv", encoding="utf_8")2-4. キーワードを可視化してみる
データ前処理後に10,124件あった投稿数ですが、nlplotを使ったキーワードの可視化とBERTopic(次セクション)では、2023年の投稿だけを使いました。
nlplotは1万件の投稿でも問題なく実装でたのですが、後述のBERTopic分析をGoogle Colaboratoryで実行した際、GPUメモリ不足で分析が進まなかったので。
2023年に投稿された子育て・育児に関する投稿、合計2,765件を抽出して、
可視化の準備が完了しました!
今回はnlplotを使い可視化してみました。
nlplotとは?
「自然言語の基本的な可視化を手軽にできるようにしたパッケージ」で、たかぱい@takapy0210さんがこちらでライブラリを公開してくださっています。
wordcloudや棒グラフ、共起ネットワークなど、色々な可視化が簡単にできるようです👏🏼
まず最初に、「子育て・育児」の投稿でどんなキーワードが使われているのかをざっとみてみたかったので、wordcloudで可視化してみました。
Wordcloudとは?
分析対象の文章から出現頻度が高い単語を選び、その出現頻度の合わせて文字の大きさを変えて視覚化する手法です。
# --------
# nlplot
import nlplot
from plotly.offline import iplot
import matplotlib.pyplot as plt
npt = nlplot.NLPlot(df_2023, target_col='text_wakati')
stopwords = ["の","ん","ない","てる","一","これ","私","ところ","ため","思う","やる","せる","くれる","よう","みる","さん","そう","くださる"]
fig_wc = npt.wordcloud(
width=1000,
height=600,
max_words=100,
max_font_size=100,
colormap='tab20_r',
stopwords=stopwords,
mask_file=None,
save=False
)
plt.figure(figsize=(8.0, 6.0))
plt.imshow(fig_wc, interpolation="bilinear")
plt.axis("off")
plt.show()
子育てにまつわる色々な言葉が出てきました。
こうして見るだけでも、「子供」だけではなく、「言う・しまう・結婚・妊娠・出産・仕事・自分」などなど、多種多様な悩みがありそうだと見えてきました。
ここまでで気になった点
wordcloudと共起ネットワークで「有馬線」と出ていたのが気になり、投稿の原文と形態素解析されたデータを確認しました。
すると「ありません」という言葉が「有馬線」に変換されているではないですか!気が付かなかった…。
こちらを参考にMecabの辞書をunidicで試してみたところ、「有馬線」と解析されませんでした。使用する文の傾向によって、辞書を変更して試してみるのも大事かもしれません。
2-5. BERTopicでクラスタリング
最後に、数ある子育て・育児投稿をクラスタリングしてみました。
文章をベクトルに変換するembedding手法を使う「BERTopic」を使うのがよさそう、ということで、今回はBERTopicでチャレンジします!
BERTopicって何?
BERTopicサイトには、“トランスフォーマーと c-TF-IDF を活用して高密度のクラスターを作成するトピックモデリング手法で、トピックの説明に重要な単語を残しつつ、トピックを簡単に解釈できるようにします。” と書かれています。
ふむ。初心者の私はすぐに理解できず…。もう少し詳しく勉強してみました。BERTopic は、以下のプロセスを使って、文書などからトピック表現を作成してくれるようです。
(注・BERTopic初心者のため、思い違いあるかも)

日本語ではSansan Tech Blogさんの記事、英語ではBERTopic Explained(動画)やこちらの記事 が分かりやすかったです。
早速BERTopicを実装してみた!
BERTopicが何をしているのか理解が深まったところで、こちらの記事(日本語)とこちらの記事(英語)を参考に、Yahoo!知恵袋の投稿データで実装してみました。
PyCharmでは実行が進まなかったので、ここからGoogle Colaboratoryで実行しています。
まずは対象データの入ったファイルをGoogle Colaboratoryへアップロード。
from google.colab import files
uploaded = files.upload()ファイルのデータをデータフレームに格納。
import pandas as pd
import io
df_2023 = pd.read_csv(io.BytesIO(uploaded["2023_parenting_concern_posts.csv"]))データフレームの対象コラムを docsというリストに格納しました。
docs = df_2023['text_clean'].tolist()これでデータの準備は完了です!
続いて、BERTopicをインストールしました。
# BERTopic
!pip install bertopic
from bertopic import BERTopic次に、モデルを設定していきます。
最初はembedding_modelを"all-MiniLM-L6-v2"、クラス数は"auto"に設定してみました。
model = BERTopic(
embedding_model="all-MiniLM-L6-v2",
language="japanese",
calculate_probabilities=True,
verbose=True,
nr_topics="auto"
)モデルが設定できたところで、fit_transformで実装します。
topics, probs = model.fit_transform(docs)実行完了すると、下のような表示が出ます。

こちらの画像はご参考まで。42トピックから27つに削減したよーと出ています。)
初回モデルの実装結果
まず、なぜかトピックは2つと出力されました。
詳しくチェックするために、model.get_topic_info()でトピックの概要をチェックしてみました。トピックを表す重要語のリスト(Representationコラム)を見てみると、接続詞だったり「よろしくお願いします」などのように、単語ではなく文が出力されました。

Name:各トピックの名称
Representation:各トピックを表す重要語たち
Representative_Docs:各トピックの代表的なdocs(今回の場合は投稿文)
モデルのチューニング(モデル2)
原因を探るため、BERTopicのFAQを確認した所、下記のような記載がありました。
「BERTopic のデフォルト モデル (all-MiniLM-L6-v2) は、英語のドキュメントには適切に機能しますが、多言語ドキュメントやその他の言語の場合、paraphrase-multilingual-MiniLM-L12-v2 モデルが優れたパフォーマンスを示しました」
モデル2では、embedding_modelを”paraphrase-multilingual-MiniLM-L12-v2”に変更して再実行しました。
model = BERTopic(
embedding_model="paraphrase-multilingual-MiniLM-L12-v2", #ここ変更しました
language="japanese",
calculate_probabilities=True,
verbose=True,
nr_topics="auto"
)モデル2の実装結果
再度トピックの概要をチェックすると、トピック数は24まで増え、それらしくなった気が!
でもまだまだトピックを表す重要語が接続詞だったり、文が多めなのが気になりました。

カウント数が最大となったTopic -1は、生成されたトピックに割り当てられていない外れ値を指していて、こちらは無視されるようです。
モデルのチューニング2回目(モデル3)
おそらく日本語と英語の違いだったり、使用データの特徴もあるのか?と思い、色々とトライ&エラーしてみたところ、 ”Using BERTopic on Japanese Texts - Tokenizer Updated” という記事を発見!
早速記事を参考にして、まずはstopwordsに使う単語が格納されているtxtファイルをアップロードした後、tokenize_jpという関数を作成。こちらをvectorizerとして設定しました。
# -----------
# stopwordsとなる単語が入っているtxtファイルのアップロード
from google.colab import files
uploaded2 = files.upload()
# -----------
# アップロードを終えたらdecodeする
import io
io.StringIO(uploaded2["stopwords-ja.txt"].decode("utf-8"))
# -----------
# tokenize_jpの設定
import locale
locale.getpreferredencoding = lambda: "UTF-8"
! pip install mecab-python3 unidic-lite
import MeCab
def tokenize_jp(docs):
# Read stopwords from file
with open('stopwords-ja.txt', encoding='utf-8') as f:
stopwords = set(f.read().split())
#for doc in docs:
words = MeCab.Tagger("-Owakati").parse(docs).split()
# Remove stopwords from words
words = [w for w in words if w not in stopwords]
return words
vectorizer = CountVectorizer(tokenizer=tokenize_jp)新たに設定したvectorizerをモデルに追記、モデル2の結果をもとにクラス数は20に変更しました。
model = BERTopic(
embedding_model="paraphrase-multilingual-MiniLM-L12-v2",
vectorizer_model = vectorizer, #ここ追加しました
language="japanese",
calculate_probabilities=True,
verbose=True,
nr_topics="20" #ここ変更しました
)
モデル3の実装結果
再度実装し、トピック概要をチェックしてみたところ、トピックの重要語が単語で表現され良い感じになりました!

トピックを可視化
まだまだモデルの微調整はできそうですが、トピックが良い感じで抽出されたところで、上位10個のトピックを下記2つの方法で可視化しました。
BERTopicも様々な可視化オプションがありますが、今回はTopic Word Scoresと Intertopic Distance Mapを使います。
Topic Word Scores
各トピック表現の c-TF-IDF スコアから棒グラフを作成することで、トピック間およびトピック内の相対的な c-TF-IDF スコアからインサイトを得ることができます。
今回は上位10トピックの重要語を視覚化しました。
model.visualize_barchart(top_n_topics=10)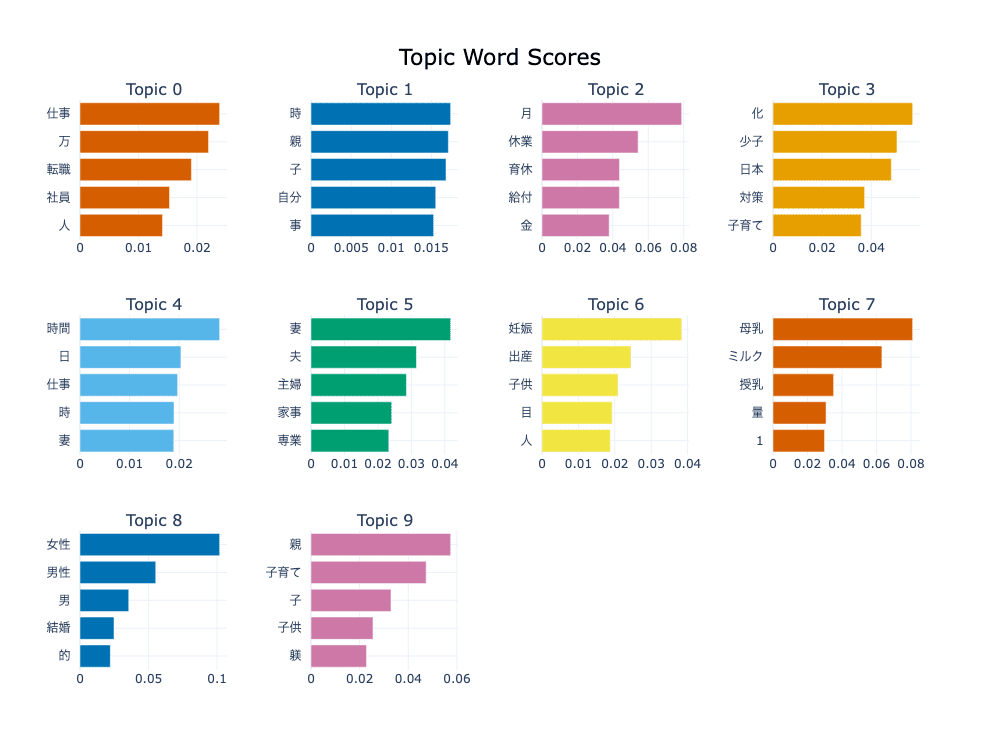
Intertopic Distance Map
トピックを構成する単語に基づいて、本来人間の脳で考えられる以上にある次元を、2次元などの人間でも理解できる次元に変換してトピックを視覚的にプロットしてくれます。
model.visualize_topics(top_n_topics=20,
title='<b>Intertopic Distance Map - Top 10 Topics</b>',
width=1200,
custom_labels=True)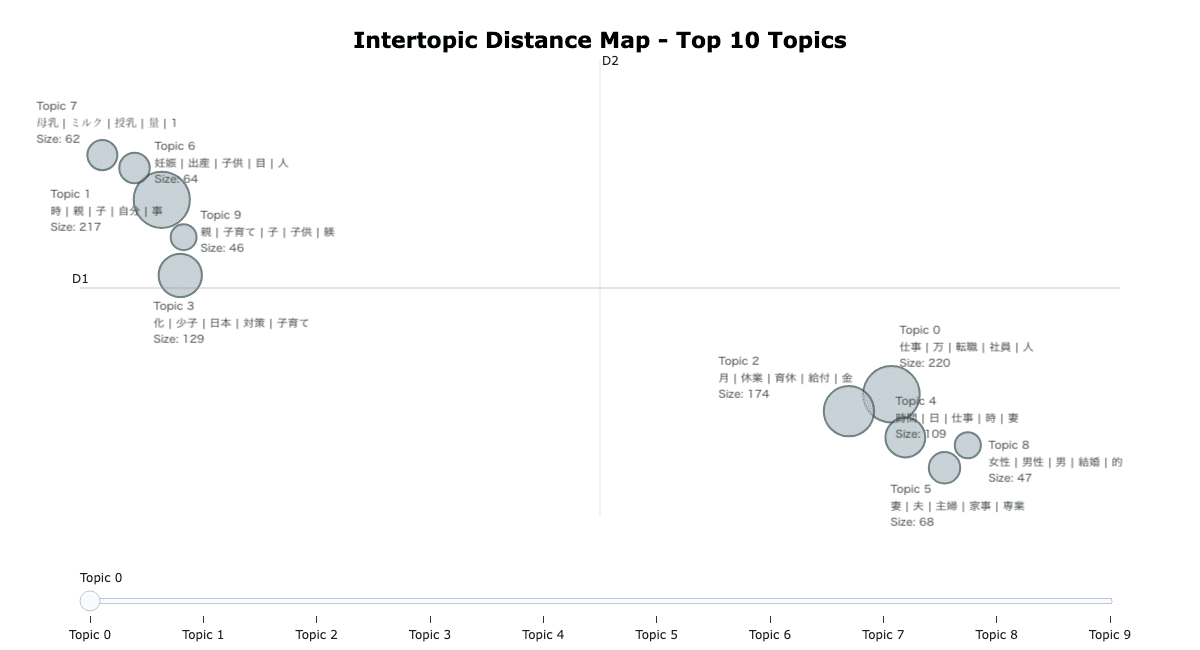
トピックが互いに近いほど、共通の単語が多いそうです。つまり、似ているトピック同士は近くに、似ていないものは互いから離れてマッピングされています。
円の大きさはトピック内のdocsの数を表しています。
今回の場合、円が大きいほど、より多くの投稿文がそのトピックに属していることを意味しています。
Topic Word Scoresと Intertopic Distance Mapを2つ表示することで、どのようなクラスターがあるのか見えてきました。
最後に、クラスタリングの結果を次のセクションで詳しくみていきます。
3. Yahoo!知恵袋の投稿から見えた子育ての悩み
前セクションでクラスタリングした子育て投稿の上位10トピックを、Intertopic Distance Mapを使って詳しく見ていきましょう。
大きく左上と右下の2つのグループに分かれています。
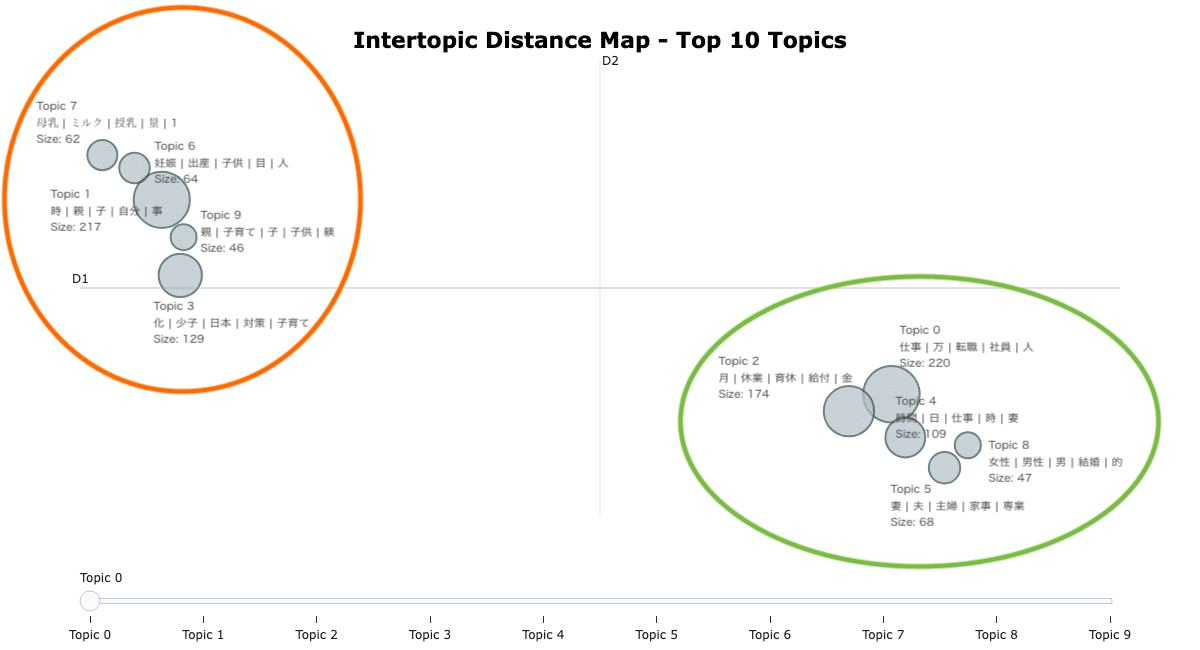
まずは左上のグループから。
トピックの詳細をより理解するためにmodel.get_representative_docs(topic=トピックの番号)で指定トピックを代表する文書(投稿)もチェックしました。

Topic 7: 母乳やミルクについて
産後数ヶ月〜断乳までの母乳育児やミルクの量についての相談。
「母乳をなかなか吸えない」というものから、「助産院に相談しても母乳を続けろと言われる」「 母乳育児を頑張れない自分がダメな母親に感じて毎日辛い」といった母乳神話にまつわるストレスも投稿されていました。
Topic 6: 妊娠中や出産・産後のトラブルについて
産後の恨みは一生物と言いますが、「切迫流産で妊娠初期から出産間近まで入院し出産」 など妊娠中のトラブルから、「自然分娩じゃないと子供は可愛くない そんなの母親じゃないって言われた」「産後早い段階で夫の風俗通いが発覚」「出産後子育てしていく自信がない」など、産後に起こった人間関係や出来事についての相談が多く見られました。
Topic 1: 自分の親との関係、親から受けた育児について
Topic 6と隣接しているTopic 1では、子育て中の親だけではなく、育てられてきた子供側の相談が目に入りました。
「子供の頃に親が無責任で 家事育児を放棄していた」や「親を許せない」といったような子供という立場からの悩み、親との関係に悩む相談が見られました。
Topic 9: 自分自身の子育てについて
Topic 1と隣接しているTopic 9では、現役子育て世代から寄せられた子育ての難しさや正しい子育て・躾に関する相談が見られました。
「子育てって難しい」「やり過ぎると過干渉 毒親だの言われ やらなさ過ぎると放置児だの色々これまた言われる」「子育て方針の合わない親子と距離を置く事にした」など、どうするのが正解なのか?を探しているような相談が投稿されていました。
Topic 3: 日本政府の少子化対策について
左上のグループ最後のトピックは、今話題の政府の少子化対策についての相談というより、「国民負担率を上げずに少子化対策を行うことを政府は考えているのか」「子育て世代に1万円給付を検討するだけで終わりますか」のような疑問を投げる投稿が見られました。子育て中ではない方々の声も多く見られました。
次は右下のグループを見ていきましょう。

Topic 0: 子育て中の仕事・転職、家計をやりくりするための手取りや貯金について
子育てにお金はつきものですが、子育て中の働き方と時間、給与のバランスに悩んでいる声が多いようです。
生活費・教育費を賄うために転職活動をしているけれど、「面接で残業について問われ落ちまくっています」という相談や、仕事・子育て・家事の両立がなかなか上手くいかず「在宅勤務ができる仕事に転職したい」、ローンや教育費を考えると稼ぎたいけど「正社員になると休みが取りにくい」「時間減らして給与抑えて扶養に入った方がいいのか」といった相談がありました。
Topic 2: 育休と給付金について
育児休業の制度や「このような場合は給付金はどうなるのか」という相談。
「保育園に入園できなかった為 育児休業給付金の期間延長を申請したが給付金は?」という不安の声や、「1人目の育休復帰から2人目の産前休暇に入るまで数ヶ月しか空いていない場合」など。育休制度は少し分かりにくいのかもしれません。
Topic 4: 夫婦間での家事子育ての分担と可処分時間について
共働き、専業主婦の家庭どちらの相談もありました。夫婦で分担しているけど、お互いに分担量に不満があったり(「これ以上何を求めるんだと言われました」など)、できるだけのことをしてくれるけど基本はワンオペで「1人で子供の世話をしていると のんびりしていた時間も帳消しになってしまいます 」「いつまでこれが続くんだろうと先が見えなくてしんどい」と言った声が投稿されていました。
また、「時間ができても、あれもやらなきゃ、これもやらなきゃと気持ち的に休まらない」といったような悩みも。
上記3つのトピックでは、子育て中の働き方とお金、夫婦での子育て分担(共働き・専業に関わらず)に関するの悩みが隣接しています。
では最後に、残り2つのトピックを見ていきましょう。
Topic 8: 結婚・子育てにおける男女の「役割」について
サイズは大きくないですが、相談というより「男女の役割について自分の意見についてどう思うか」を聞いている投稿がクラスタリングされていました。
「将来の結婚相手には家事をお任せして育児は分担、女性には専業主婦かパートかアルバイトをして欲しいが これは差別意識が強いのか」といった投稿から、「男性にばかり負担」という投稿もありました。現代の男女はお互いに色々と求められている期待が多くて大変なのかもしれません。
Topic 5: 妻の家事・子育てについて
妻の家事・子育てについての相談が見られました。
専業主婦家庭の声が多めでしたが、共働き家庭の声もちらほら。専業主婦の妻が仕事を始めたいが家事育児分担で喧嘩になったという相談、そして、妻の子育てについての不満もありました。一方で、「妻が子育てで常にイライラしていて少しずつ壊れていくようで それが何よりも辛い」といったような心配の声も。
Topic 8と5では、男女・夫婦の役割やあり方についての意見と相談投稿が多く、男女ともに結婚や子育てのあり方(正解はないと思いますが)の悩みがあるようです。
考察のまとめ&気付き
全トピックを詳しく見ていくと、左上のグループは親子関係や子育て方法に関する相談が大半を占めていました。
一方で右下のグループでは、子育て中の働き方やお金、夫婦の家事育児分担の悩み、そして男女・夫婦の役割に関する投稿が代表的な話題でした。

今回は「子育ての悩み」が知りたいと思い分析に取り組みました。
子育てに関する悩みだから、「今子育て中のパパママの『子供』についての相談が大半だろうなぁ」と勝手ながら思い込んでいました。
しかし実際に分析してみると、子育てをしている人だけでなく、自分が育てられた環境や自身の親との関係に悩んでいる人、少子化対策に疑問を持っている人など、想定していた以上に多種多様な子育て関連の投稿があり、「子育ての悩み」=「子育て中の人が悩むこと」という思い込みが自分の中であったな…という点が私にとっての気付きでした。
子供の有無に関わらず、みんな何かしら「子育て」に繋がる悩みを持っているのかもしれません。データを使って俯瞰的に見る大切さを再認識できたプロジェクトでした。
4. 最後に
今回初めて自然言語処理、BERTopicを使ってクラスタリングを実行してみましたが、プログラミング講座で学んだ内容を実装してみる面白さを体験できました。
(うまくいかない時のフラストレーションも今となってはいい経験)
今後は下記3点を改善していきたいです。
投稿の長さが与える影響:
平均の文字数が540と、使用したデータの文字数が多めだったかもと思いました。何行も文がある投稿は文に切り分けるなど改善の余地があるのかもしれません。2023年以前の投稿も含めた分析:
今回は2023年の投稿だけを使用したので、今後は当初抽出した1万件分の投稿を使っての分析ができないか挑戦してみます。上位10トピック以下も含めた分析とBERTopicでの外れ値の削減:
Topic -1と分類された投稿が多いのでは?と気になったので、こちらの外れ値削減方法を参考にして再実装してみたいと思います。
上記以外にも自分で気付けていない改善点もありそうですが、スクレイピングからBERTopicの実装まで経験は今後の糧になりそうです!
次回はまた別トピックで、教師あり学習など他の分析手法にも挑戦してみたいと思います。
長い長い長文を最後まで読んでくださった皆様、お読みいただきありがとうございました😊
この記事が気に入ったらサポートをしてみませんか?