コスパのいい選手は誰だ?年俸10億円縛りでチームを作ってみる【Python初心者日記No.13】

こんにちは、ashです。このnoteをご覧いただきありがとうございます。
このnoteは、「Python」×「野球」をテーマにした日々のプログラミング学習記録です。
今回やること
2019年シーズン開始時点の推定年俸を使い、選手の合計年俸10億円以内でチームを作ってみたいと思います。ルールは次のとおりです。
・DH制ありで野手9名+投手3名(先発、中継ぎ、抑え)
・年俸は2019年シーズン開始時点のデータを使用
・ポジションの配置は、2019年に主に守っていたものに限定
・10億円のうち、投手と野手への配分は自由
なお、これは里崎智也さんのYouTubeチャンネルの企画と同じ内容です。
私のチーム作りのコンセプトは次のとおりです。
・まずは年俸に比して成績が良い選手(コスパがいい選手)からポジションを埋めていく
・余った予算で弱いポジションを補強していく
・感覚ではなく、あくまでも数値ベースで選手を決定する
・基準とする指標として、野手はwOBA、投手はDIPSを使用する
・年俸が決定される要素は成績だけではなく、たとえばファンサービスやプレー外でのチームへの貢献も含まれるが、これらは定量化できないため、今回の検証では考慮しない
なお、野手は「2019年シーズンに300打席以上」、投手は「2019シーズンに100イニング以上(先発)」、「2019シーズンに50イニング以上(中継ぎ、抑え)」の選手を選出の対象とします。
データソース
プロ野球データFreak(https://baseball-data.com/)からデータをお借りしました。
書いたコード
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
# 行数の表示を増加
pd.set_option("display.max_rows", 1000)
df_g = pd.read_html('https://baseball-data.com/19/player/g/')[0]
df_yb = pd.read_html('https://baseball-data.com/19/player/yb/')[0]
df_t = pd.read_html('https://baseball-data.com/19/player/t/')[0]
df_c = pd.read_html('https://baseball-data.com/19/player/c/')[0]
df_d = pd.read_html('https://baseball-data.com/19/player/d/')[0]
df_s = pd.read_html('https://baseball-data.com/19/player/s/')[0]
df_l = pd.read_html('https://baseball-data.com/19/player/l/')[0]
df_h = pd.read_html('https://baseball-data.com/19/player/h/')[0]
df_e = pd.read_html('https://baseball-data.com/19/player/e/')[0]
df_m = pd.read_html('https://baseball-data.com/19/player/m/')[0]
df_f = pd.read_html('https://baseball-data.com/19/player/f/')[0]
df_bs = pd.read_html('https://baseball-data.com/19/player/bs/')[0]
concat_list = [df_g,df_yb,df_t,df_c,df_d,df_s,df_l,df_h,df_e,df_m,df_f,df_bs]
df = pd.concat(concat_list)
df['年俸(推定)'] = df['年俸(推定)'].str.replace('万円', '')
df['年俸(推定)'] = df['年俸(推定)'].str.replace(',', '')
df['年俸(推定)'] = df['年俸(推定)'].astype(int)
# indexの始まりを0にリセット
df_info = df.reset_index(drop=True)
##########
df2 = pd.read_html('https://baseball-data.com/19/stats/hitter2-all/tpa-1.html')[0]
df3 = pd.read_html('https://baseball-data.com/19/stats/hitter3-all/tpa-1.html')[0]
df4 = pd.read_html('https://baseball-data.com/19/stats/hitter4-all/tpa-1.html')[0]
df5 = pd.merge(df2, df3)
df_batter = pd.merge(df5, df4)
df_batter = df_batter.round(3)
df_batter.columns = df_batter.columns.droplevel(0)
df_batter = df_batter.drop(['順位'], axis=1)
##########
df = pd.merge(df_info, df_batter, how='outer', on='選手名')
df = df[df['打席数'] >= 300]
df['wOBA'] = round((0.692*df['四球']+0.73*df['死球']+0.865*(df['安打']-df['二塁打']-df['三塁打']-df['本塁打'])+1.334*df['二塁打']+1.725*df['三塁打']+2.065*df['本塁打'])/(df['打数']+df['四球']+df['死球']+df['犠飛']), 3)
df['OPS'] = df['OPS'].astype(float)
df['RC27'] = df['RC27'].astype(float)
df['XR27'] = df['XR27'].astype(float)
df['wOBA'] = df['wOBA'].astype(float)
df['SR/OPS'] = round(df['年俸(推定)']/df['OPS'], 0)
df['SR/RC27'] = round(df['年俸(推定)']/df['RC27'], 0)
df['SR/XR27'] = round(df['年俸(推定)']/df['XR27'], 0)
df['SR/wOBA'] = round(df['年俸(推定)']/df['wOBA'], 0)
drop_col1 = ['No.','守備','生年月日','年齢','年数','身長','体重','血液型','投打','出身地','試合','打数','安打','得点','二塁打','三塁打','本塁打','塁打','打点','盗塁','盗塁刺','犠打','犠飛','四球','敬遠','死球','三振','併殺打','出塁率','長打率','NOI','GPA','IsoP','IsoD','RC','XR','RC27','XR27','BABIP','SecA','TA','四死球','本塁打率','三振率','四球率','PSN','BB/K']
df = df.drop(drop_col1, axis=1)
df['SR_mean'] = sum(df['年俸(推定)']) / len(df['年俸(推定)'])
df['SR_diff'] = df['年俸(推定)'] - df['SR_mean']
df['SR_square'] = df['SR_diff'] ** 2
df['SR_varuance'] = sum(df['SR_square']) / len(df['年俸(推定)'])
df['SR_sqrt'] = np.sqrt(df['SR_varuance'])
df['SR_deviation']= round(df['SR_diff'] * 10 / df['SR_sqrt'] + 50,3)
df['wOBA_mean'] = sum(df['wOBA']) / len(df['wOBA'])
df['wOBA_diff'] = df['wOBA'] - df['wOBA_mean']
df['wOBA_square'] = df['wOBA_diff'] ** 2
df['wOBA_varuance'] = sum(df['wOBA_square']) / len(df['wOBA'])
df['wOBA_sqrt'] = np.sqrt(df['wOBA_varuance'])
df['wOBA_deviation']= round(df['wOBA_diff'] * 10 / df['wOBA_sqrt'] + 50,3)
df['wOBA_com'] = round(df['wOBA_deviation'] / df['SR_deviation'], 3)
drop_col2 = ['SR_mean','SR_diff','SR_square','SR_varuance','SR_sqrt','wOBA_mean','wOBA_diff','wOBA_square','wOBA_varuance','wOBA_sqrt']
df = df.drop(drop_col2, axis=1)
df = df.sort_values('wOBA', ascending=False)
print(df)
# 散布図を作成、選手名をラベルに設定
for i, txt in enumerate(df['選手名'].values):
plt.scatter(x=df['wOBA_com'], y=df['年俸(推定)'])
plt.annotate(txt, (df['wOBA_com'].values[i], df['年俸(推定)'].values[i]))
# 散布図に出力
plt.xlabel('wOBA_com')
plt.ylabel('年俸(推定)')
plt.grid(True)
plt.show()結果
次の散布図が出力されました。

分析レポート
まずは上の図について説明します。
12人の合計年俸が10億円という制限がありますので、スター選手ばかりを選出することはできません。なので、まずはコスパのいい選手=低年俸で高いパフォーマンスを発揮する選手を探します。
今回の検証にあたり、打者についてはwOBAを指標におきました。
したがって、まずは年俸とwOBAの関係性について散布図で確認します。

x軸にwOBA、y軸に年俸をおいていますので、基本的にはグラフは右肩上がり(=年俸が高ければwOBAも高い)になると想定されますが、概ねそのような結果となっています。
では、コスパが高い選手はどこにいるのでしょうか?コスパが高い選手=年俸が低くてwOBAが高い選手と定義できますので、このグラフで言うと右下に位置する次の選手がコスパが高いといえそうです。
・鈴木誠也選手
・グラシアル選手
・ブラッシュ選手
・吉田正尚選手
・森友哉選手
その他にも、年俸5,000万円クラスの選手でコスパが高い選手が何人かいそうですが、グラフ上では密集していてわかりにくいですね。そこで、300打席以上の選手の中で、①年俸と②wOBAの偏差値をとり、年俸偏差値に対してwOBA偏差値の高い選手を探してみます。

上の表では、SR_deviationで年俸偏差値、wOBA_deviationでwOBA偏差値、wOBA_comでSR_deviationとwOBA_deviationの比率を計算し、wOBA_comの高い順でランク付けしています。
たとえば森選手はSR_deviationが45.594なので、打席300以上の選手の中では年俸は低いですが、wOBA_deviationが67.486なので、非常に高いパフォーマンスを発揮しています。
今回のチーム編成にあたっては年俸の上限がありますので、この中ではロメロ選手、福田選手、バティスタ選手、村上選手、荻野選手あたりが候補に入ってきそうです。
ここで、SR_deviationについて留意が必要です。たとえば年俸が高くパフォーマンスも高い山田選手、坂本選手あたりは、SR_deviationが高すぎるため、相対的にwOBA_comが低く計算されてしまいます。これはwOBAの分散に対して、年俸の分散が広く、球界トップクラスの年俸だとかなり高い偏差値が計算されてしまっているためです。いずれにしても今回の検証では高年俸の選手は採用できないので、現状の方法で進めます。(この点について、なにか適切な比較方法があればご指摘いただけると幸いです!)

チーム編成にあたっては、wOBA_comが高い選手から選手し、余った予算で弱いポジションを補強していきます。投手については、打者と同様の方法で、DIPSを指標にした次のランキングからコスパのいい選手を採用します。
その結果、次の選手でチームを編成することができました。

合計年俸は9億8,000万円です。
半数以上は侍JAPANメンバーで構成されており、なかない良いチーム編成となったのではないでしょうか。森選手、鈴木誠也選手、吉田正尚選手、山本由伸選手あたりは10億円チームの常連ですが、福田選手、荻野選手、中川選手あたりの年俸も低いながら高パフォーマンスを発揮した選手を選出できました。また、グラシアル選手、松井裕樹選手は年俸が高いため、通常は選出しにくいところですが、年俸以上に高いパフォーマンスを発揮していたため、選出の対象となりました。
なお、今回の検証は2019年シーズン開始時点の年俸データを使用しましたが、2020年シーズン開始時点の年俸データを使用する場合、次のようなチーム編成となります。

合計年俸は9億8,740万円です。
上で選出したメンバーの多くは2019年の活躍で年俸が上がったため、半数近くが入れ替えとなりました。森選手、吉田正尚選手が年俸2億円に到達しましたが、wOBA_comはまだまだ上位にランク付けされますので、コストはかかりますが選出の対象となりました。森選手と吉田正尚選手で圧迫されたコストは、井上選手、安部選手、ロメロ選手、村上選手、守屋選手を選出することで全体のバランスをとっています。
2019年のチームと比べるとやや戦力ダウン感が否めませんが、各チームの主力級は選出できているため、十分に戦えるチームになったのではないかと思います。
さいごに
今回は里崎さんの企画に乗り、感覚値ではなくあくまでも数字ベースでチーム編成をしてみました。ご参考までに私のチーム(左側)と里崎さんのチーム(右側)を比較してみます。(なお、里崎さんのチームの合計年俸が9億円だそうですので、単純比較はできません)
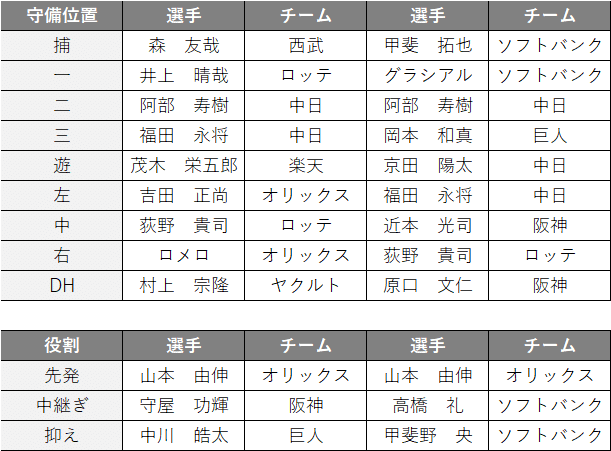
阿部選手、福田選手、荻野選手、山本由伸選手はかぶっていますが、それ以外の人選は異なりますね。
今回の検証では、守備度外視で打撃指標だけでチームを編成しましたが、守備指標を考慮するともう少し違った結果になるかもしれません。守備を含めた総合指標でのチーム編成も次の機会にチャレンジしてみたいと思います。
サポート頂けると活動のはげみになります!