
scikit-learn 分類 - k近傍法(2)

今日のMusic : Above & Beyond 2004 @ BBC
今回は、ここのParameter Tuning 以下をフォローしながら、kのチューニングと結果の検証の仕方を学ぶ。
[1] 必要ライブラリとデータを読む。print(__doc__)は、moduleの説明を掻き出してくれる。たとえば、下の"Automatically ... "の文章。
[2]で人間にも読みやすいようにpandasでdata formatを作りデータをみる。

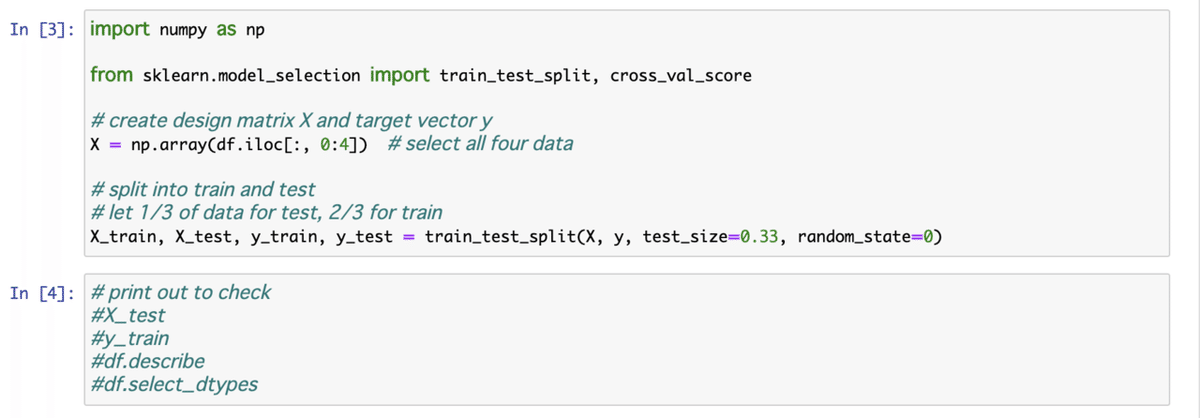
[3] データを訓練用とテスト用に分ける。
[4] 途中で、色々印刷して正しいことをしているか確認すること!
[5] (同じ分類に入る)お隣さんの数kを適当にここでは3として、分類を検証する値Accuracyを求めてみる。

[6] 次に、kを1から50まで奇数として変数にして検証してみる(tuning)。
cross_val_scoreは、 cross-validation(交差検証)によりscoreで精度の検証を行う。この例ではClassification(分類)を行っているので、"accuracy”の方法でスコアを求める(Ref.)。
ここで、以下に気をつける。元のtutorialではmseをplotしているが、1からaccuracyを引けば求められる。
・Classification(分類) → Accuracy → reward function (報酬関数)→ 大きい方が良い
・Regression(回帰) → MSE → loss function (損失関数) → 小さい方が良い
エラーも見てみたいので、書き出す。confidence interval(CI, 信頼区間)とerror barの大きさに注意(Ref.)。
・95% CI → error bar = 2×std
・68% CI → error bar = std

[7] plotする。

本当は、kをここで見つけたbest fitの5として前回作ったような分類のplotをデータの種類 4つ、2D plotを計6個(=4C2)作って、前回のと比較しようかと思ったが、次に行きたいので、skipする。
また、本当はCVの値(ここでは10と設定)のtuningも必要か?
この記事が気に入ったらサポートをしてみませんか?