
Word Mover's DistanceでコピペESを見つける。

エントリーシートの例文や正解がネット上にあふれている現代。本来エントリーシートでは、候補者自身が体験したことを本人の表現で語って欲しいところです。
ネットにある例文をまるっとコピーして、もしくはちょろっといじってエントリーしているのかどうか確認すべく、簡単な自然言語処理で「コピペES発見器」を実装してみます。
方針
よくあるのはこんな感じ。
例文①
私の強みは、ゴールから逆算し、すべきことを明確にしてきちんと計画を立てられるところだ。
私は大学で体育会サッカー部に所属し、日々練習に励んでいた。同じポジションには高校時代にインターハイに出場した経験のあるライバルもいて、一年生のときはスタメンとして一試合も出場できなかった。…
例文②
私の強みは、ゴールから逆算し、すべきことを明確にしてきちんと計画を立てられるところです。
私は大学で体育会バスケ部に所属し、日々練習に励んでいました。同じポジションには高校時代にインターハイに出場した経験のあるライバルもいて、1年生のときはスタメンとして1試合も出場できませんでした。…
丁寧語!競技が違う!そして漢数字とアラビア数字!
※文章は適当です。
今回は、文章の類似度を測ることで、パクりなのかどうかを見分ける方法を考えていきます。文章の類似度を測るタスクには色々な方法がありますが、今回はWord Mover's Distance(WMD)を利用します。理論についてはこちらが詳しいですが、要は単語間の意味合いの差の総和を計測するということをやっていきます。直感的に、上記の例文のような差であれば、類似度が高いと判断してくれそうです。
コード
まずは必要なライブラリの読み込み。
分かち書き(単語への分解)を行うためにMeCab、WMDを計算するためにgensimとpyemdをimportしておきます。
処理の進捗状況を可視化するためにtqdmもimportします。これは任意です。
# ライブラリ・学習済みモデル読み込み
import numpy as np
import MeCab
from tqdm.autonotebook import tqdm
import pyemd
from gensim.models import KeyedVectors
from gensim.test.utils import datapath今回は学習済みベクトルを利用してWMDを計算します。配布元はこちら。
# Wikipedia エンティティベクトルの読み込み
nwjc_model = KeyedVectors.load_word2vec_format(
datapath('entity_vector/entity_vector.model.txt'),
binary=False
)正しく読み込めているでしょうか。語数、次元数を確認しましょう。
# 語数, 次元数
print(len(nwjc_model.vocab), nwjc_model.vector_size)
1015474 200用意しておいたcsvファイルを読み込みます。
### 判定対象テキスト読み込み・分かち書き
data = pd.read_csv('sample.csv', dtype = {'code':str})
文書を読み込んで分かち書きを行い、WMDを計算する準備をします。
tagger = MeCab.Tagger("-Owakati")
text_tokenized = list()
for t in data['text']:
str_output = tagger.parse(t)
text_tokenized.append(str_output)text_tokenizedは、単語ごとに空白区切りになっているテキストのリストです。
![]()
### Word Mover's Distance
text_wmd = pd.DataFrame([{'id' : code, 'text' : text.split()} for code, text in zip(data['code'], text_tokenized)])
text_wmd.set_index('id', inplace=True)DataFrameの形にして準備完了です。

いよいよWMDの計算。総当たりで計算していく必要があります。
例えば、文書Aと文書Bの類似度を測り、次に文書Aと文書C、最後の文書まで読み込んだら次は文書Bと文書C、というような形です。
文書数を5として図にするとこんな感じ。1から10まで順番に処理していきます。

%%time
df_sim = pd.DataFrame()
i = 0
for s, id_s in zip(tqdm(text_wmd.text, desc='LargeLoop'), text_wmd.index):
i += 1
for t, id_t in zip(tqdm(text_wmd.text[i:], desc='SmallLoop', leave=False), text_wmd.index[i:]):
df_sim = pd.concat([df_sim, pd.DataFrame({'similarity' : nwjc_model.wmdistance(s, t), 'comp1' : id_s, 'comp2': id_t}, index=[id_s + ',' + id_t,])])tqdmでこんな感じのプログレスバーを表示しています。
(アニメーション止まらなくてウザいかも…)
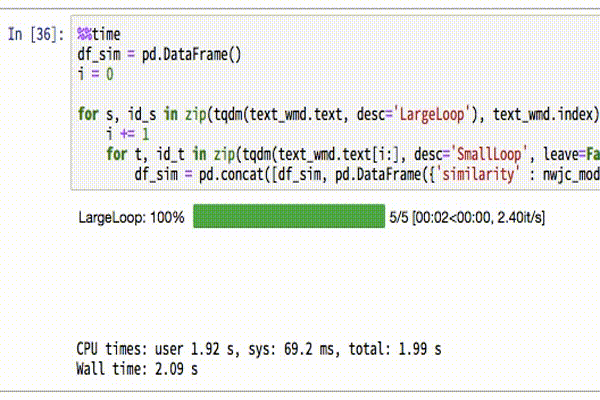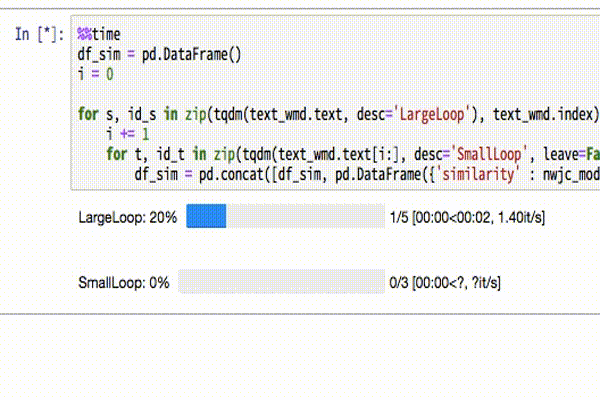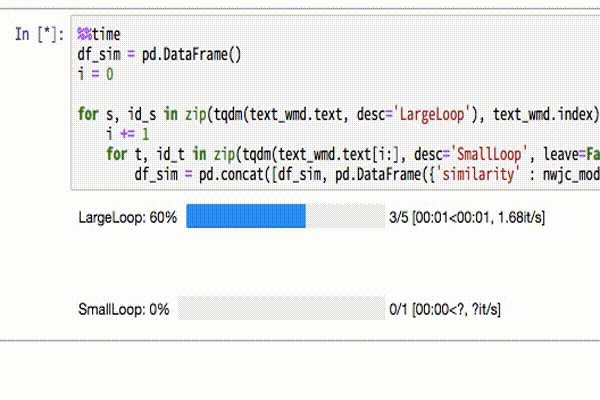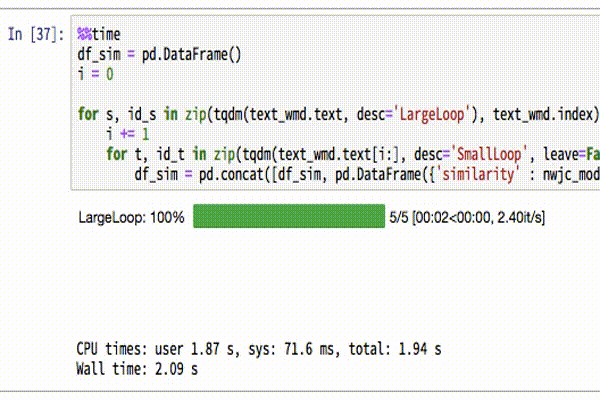
計算結果を見てみましょう。
df_sim.sort_values('similarity', ascending=True)
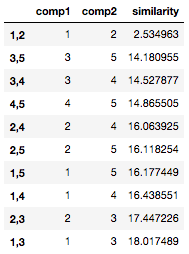
一番上の行、例文①と例文②の類似度が飛び抜けて高く出ています。
前年のES合格者のデータや、ウェブ上にあるESの例文などを比較対象として用いれば、WMD無事にコピペESを見抜くことができそうです。
少し実務で使ってみましたが、閾値は実際の文書を見て判断するのがよさそうです。
課題
WMDは総当たりで計算していく必要があるので、実際に運用するには実行に時間がかかることがネックになりそうです。
例えば、1000件のESに自由記述欄が1つあって、各々の類似度を測る場合、(999+1)×999 / 2 = 499500回の計算が必要になります。1回の計算を0.1秒で行えたとしても、単純計算で約14時間かかる計算です。
gensimのword2vecのように簡単に並列処理を行うオプションもないようですので、工夫して並列処理を組むなどの手当てが必要そうです。
この記事が気に入ったらサポートをしてみませんか?