現場で使える機械学習活用 ~その③プロジェクトで頻出する問題の対応~

はじめに
このブログは、「現場で使える機械学習活用」をテーマにした4部作のうち3作目です。これらの4部作では「いかにして機械学習を使って現実世界の問題を解決するか」を軸に、陥りやすいポイントやコツを解説していきます。
第3回目はプロジェクトで頻出する問題とどう向き合い、解決すればよいかを見ていきます。
プロジェクトで頻出する問題の対応 ←イマココ
機械学習プロジェクトで頻出する問題
機械学習プロジェクトを進めていく上で、色々な問題につきあたります。この記事では、代表的な問題をとりあげ、その性質と対策を見てきます。ここで解説するテーマは以下4つです。
学習時と実運用時のデータ分布変化への対応する
評価情報漏洩 (data leakage) を防ぐ
短絡学習 (shortcut learning) を防ぐ
少ないデータで頑健な評価をする
1. 学習時と実運用時のデータ分布変化への対応する
「データの分布」という言葉が機械学習周辺ではよく出てきて、「AというデータセットとBというデータセットのデータの分布が同じ」といった使われ方をよくします。「データの分布」は多くの場合「2つのデータセット、AとBが同じ母集団から抽出された標本か」という解釈が可能です。
機械学習は「学習したデータ分布」の性質を学んでいるので、実運用時に「学習したデータ分布」とかけ離れたデータを使うと精度が劣化します (下図) 。

しかし、開発時、つまりプロジェクト期間中使っているデータと実運用時に流れてくるデータの分布が異なることはしばしばあります。ここでは、実運用でのばらつきが既知としたときに、データ拡張によって分布のばらつきを補強する手法について見ていきます。
データ拡張とは、データに適当な変換をかけることによりデータを増やす手法です。データ拡張を利用して、あらかじめ想定できるばらつきを学習データに取り込んでおくことができます。例えば、画像に写っているものが犬か猫を分類する2値分類問題を考えてみます(下図)。

いくつか色や配置の種類、角度がありますが、それらはラベル(犬や猫)と相関はないものとします。偶然にも、集められた学習データでは対象の犬猫の色が赤、黒で、犬猫が中央に写っているデータしか取れませんでした。しかし、実運用では犬猫が端に寄っていたり、角度がついた画像であったり、紫や緑の犬猫が写っている画像を分類しなければならない場合があることがわかっています。何度か述べたように、機械学習モデルは学習したデータの分布内部では上手く動作しますが、学習データ分布から外れたもの、つまりこの場合では紫や黒の物体や端に写った物体で上手く推論できる保証はありません。
この例題のように、あらかじめ実運用データにおける「分布のずれ」の方向性が想定できる場合、「分布のずれ」方向に集中してデータ拡張をかければ実運用時の精度劣化をカバーできます(下図)。

この場合は、学習データ中の犬猫の色を緑や紫に変えたものや、位置をずらしたもの、少し回転を加えたものを人工的に作成するデータ拡張が有効です。実運用時に入ってくる緑や紫の犬猫や、角度がついた画像、端に犬猫が映った画像を学習データ分布に取り込むことができるので、実運用時の精度劣化を防ぐことができます。このとき、無闇やたらに色々な変換をかけたデータ拡張を行うのではなく、実運用時のデータ分布のずれに沿った変換をかけることが大切です。
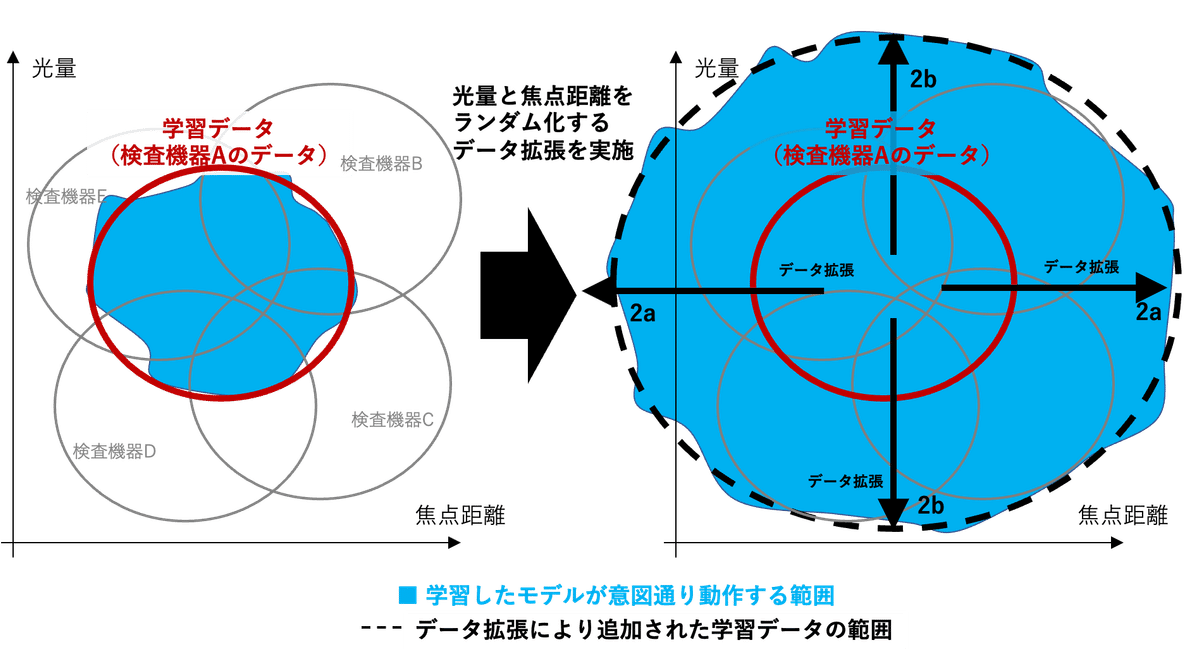
もう少し産業界の実情に沿った例として、【学習・評価データとしては1つの検査機器(検査機器Aとする)で撮影した画像しか使えないが、実運用時は不特定多数の検査機器の画像を処理する】という例を考えてみます。学習時のデータ分布、つまり検査機器Aから撮影される画像データ分布と実運用時のデータ分布、つまり検査機器A以外の検査機器で撮影される画像のデータ分布が大きくずれていると、実運用時に精度の大幅な劣化が想定されます。
しかし、この検査機器のメーカー保証の範囲から、画像撮影の焦点距離が中心スペックより最大で ±a だけズレること、撮影時の光量が中心スペックより最大で ±b だけズレることがわかっていたとします。この場合は、メーカーの保証範囲分より多めに焦点距離と光量をばらつかせたデータを学習データから作るデータ拡張が有効です。具体的に言うと、データをある範囲で無作為にボケさせたり(焦点を合わなくする)、明度をある範囲で無作為に変化させたデータを学習データに加えます。これにより、検査機器がメーカーの保証範囲内のばらつきの範囲を学習データに含ませることができます。この時、メーカーの保証範囲よりも大きな範囲でばらつかせると、機械学習モデルがカバーできる範囲がより広くなります。
2. 評価情報漏洩 (data leakage) を防ぐ
ここでは「適切に実運用時の精度を見積もる」を軸に、評価情報漏洩(data leakage)の問題点と対策をみてきます。通常、機械学習モデルを学習した後に、評価データを使って精度などの評価指標を確認します。これを実施する主な目的は「実運用時の精度を見積もることで、実運用に耐えうるかを評価する」ことです。しかし、学習/確認/評価データの分割を不適切に行うなど評価情報漏洩が発生し、正しく実運用時の精度を見積もれないことがあります。ここでは、どのような場合に評価情報漏洩が発生するのか、そして、それの発生をどのように防ぐのか、について説明します。
機械学習プロジェクトで扱うデータセットは、学習データ(train data)、過学習の検知などを行う検証データ(validation data)、擬似的な未知データとして性能検証をする評価データ(test data)の3つに分割します。これ以外の分割方法もありますが、説明のためいったん無視します。
一見、何も考えずに単純に分割すれば良いように思えますが、分割の仕方が不適切だと過学習により実運用時で全く機能しない機械学習モデルができます。データの分割は実運用時の想定に合わせてすべきです。具体的に言うと、実運用データを母集団から抽出する方法と同じような方法で行うべきです。
例えば、2010年から10年分の各地の湿度/温度/降水量等を記録したデータがあり、数日分のデータを入力として1週間先の天気を予測するという問題設定を考えます (下図) 。

その際、とりあえず学習データとして7年分、検証データとして1年分、評価データとして2年分のデータというように割り振るとします。この場合の実運用時の想定は、学習したモデルで (現在データが存在しない) 2021年以降の天気を正しく予測する、ということです。この場合、実運用時を想定した際の適切な分割方法の1例は2010~2016年を学習データ、2017年のデータを検証データ、2018,2019年のデータを評価データに割り振る方法です。
逆に不適切なデータ分割方法は、無作為(ランダム)に7・1・2年分のデータを抽出して、学習・検証・評価データそれぞれに割り振るという分割方法です(下図)。

不適切な分割をすると、評価データにおいて100%近い性能が出るにもかかわらず、実際に運用してみると全く予測が当たらないという事態に陥る可能性があります。
なぜこのようなことが起こるかを考えてみましょう。まず初めに機械学習モデルは x を入力し、y を出力する関数だということを思い出してみます。無作為に抽出してしまうと、連続した日にちのデータが学習・検証・評価にそれぞれに割り振られてしまいます。そして、それらの連続した日にちのデータは遠い未来や遠い過去のデータと比較すると、類似度が高いデータにです (下図)。

つまり、本来未知であるはずの評価データや、パラメーター更新に使われないはずの検証データと非常に似たデータが学習データに含まれています。そのため学習データに対して過適合 (overfit) する、つまり学習データをまる覚えしたとしても、検証データ・評価データともに損失が上昇せずに100%近い異常な高精度予測モデルができ上がってしまうわけです。このような本来未知であるべき情報が学習データに漏れている状態を評価情報漏洩(data leakage)と呼びます。
評価情報漏洩の状況下で学習したモデルは適切な入力データと出力データの関係を学んでおらず、学習データをまる覚えしているモデルになりやすいです。そのため、実運用時で学習データと異なるデータが来た場合に上手く動作する保証はありません。一方、適切に分割したデータではこのようなことがないため、モデルを正当に評価する準備が整っています(下図)。

この評価情報漏洩の怖いところは、別のデータセットで評価するまで過学習していることが分からない点です。一度やってしまうと大きな損害になりかねないので、データの分割は慎重にやりましょう。
また、この設定では評価データで非常に高い精度が出ます。第 1 回目で解説したように、高い精度に到達することは非常に難しいことですので、高すぎる精度が出たら評価情報漏洩を疑ってもよいかもしれません。
データ分割以外でも評価情報漏洩が発生することがありますが、拙著「現場で活用するための機械学習エンジニアリング」に記載していますので、興味ある方はご覧ください。
3. 短絡学習 (shortcut learning) を防ぐ
まず下図を見てください。学習データが左側で、推論すべき未知のデータが右側です。右側のデータの正解ラベルはAとBどちらでしょうか。

読者の方々は形の情報をもとに、ラベルはAだと予測された方が多いのではないでしょうか。しかし、機械学習でこれを学習させるとBと予測するかもしれません(下図)。なぜならば、ラベルを判断する特徴量として、形の他に物体の位置という情報があるからです。良く図を観察すると、ラベルAでは左上と右下のエリアに物体が配置されていますが、ラベルBでは左下と右上のエリアに物体が配置されていることが分かります。このように想定していない情報で学習してしまうことを短絡学習 (shortcut learning, Robert et al., 2020) と呼びます。

短絡学習は、通常の学習と同じようにデータから特徴を読み取った結果起こっていることなので、想定外の短絡学習を防ぐことは基本的に難しいです。ただし、あらかじめ想定できる要素の短絡学習をさせない方法はあります。ある要素や特徴量を推論の根拠にさせないために、それをただのノイズとしてモデルが捉えられるような仕組みを作ったり、そのような要素を学習前に削除しておくことで、短絡学習を防ぐことが可能です。
データ拡張によって位置情報をランダム化し、モデルが判断根拠とすることを防いだ例を下に示します。

もう少し現実的な例として Geirhosらの研究 (Geirhos et al., 2019) を見てみましょう。下図の (c) は人間が見ると外形情報をもとに「猫」と判断しますが、機械学習 (CNNベース) はテクスチャをベースに判断しているため「インド象」と判断しており、猫は上位 3 つにすら入っていません。

外形から判断してほしければ、テクスチャ情報をランダム化すればよいです。Geirhosらは Stylized ImageNet (下図) というデータセットを提案し、それで学習したモデルはImageNetで学習したモデルよりも外形情報をベースに判断していることを確認しています。

4. 少ないデータで頑健な評価をする
学習データが少ない場合は、データ拡張や事前学習済みモデルなどを使えばデータの少なさを補うことが可能です。しかし、学習データはある程度の量を確保したとしても、評価データが少ない状態で実運用時の精度を保証することは非常に大変です。
例えば、評価用に確保できるデータは数百程度しかなくて、実運用時に流動する数十万規模のデータを捌いた時の精度を見積もる必要があるかもしれません。このような状況では純粋に数の力だけで評価しようと思うと不可能です。しかし、工学的な視点に立ち、ドメイン知識を用いて「危なそうなところをあらかじめ押さえておく」という手法を取れば、評価の質をあげることができます。
通常、原材料や工作機械などには保証値というものが設けられています。合成樹脂であれば粘度や硬化速度のばらつき、プレス機であればプレス時の圧力のブレ幅などがそれです。それらの値のブレがある方向にいくと製品が不良になる可能性が高くなる、という危険なブレの方向性が存在することがあります。その危険なブレの方向のリスク上限値を評価することで精度を担保させるという戦略です。
これを具体的に考えるため、検査機器に搭載する四角と星形の製品を分類するアプリ(機械学習モデル)の精度評価をするという簡単な例を考えてみましょう (下図)。

この例では、新規検査機器にのせる画像分類アプリを、検査機器のスペック中心値を使って画像分類モデルを開発しています。実際に製造する検査機器は、スペック中心値とは明るさや焦点距離が少しばらついた状態にありますが、そのままの状態で調整を行わず運用をすることを考えます。個々の検査機器で調整を行わないため、製造された検査機器で撮影される画像は、学習データ(スペック中心値で撮影した画像)と比較して少しぼやけたり、明暗が異なるデータになっています。そのばらついた画像をうまく分類できるかを評価したい、という問題設定です。
この明るさや焦点が少しずれたデータが流れてくる「実運用時のデータのブレに対する精度の変化」をいかにして数少ない評価データで評価してやるかというのがこの例題で大切な部分です。もう少し具体的にいうと、焦点距離と明るさの製品スペックの中心値である焦点距離10 mm, 明るさ15 lm(ルーメン)から、製品の保証範囲内 (焦点距離10±1 mm, 明るさ15±2 lm)で検査機器のスペックがばらついた場合、どの程度の精度になるのかを評価する、という問題です。この場合、判定を間違うリスクが高くなるのは、画像が(焦点が合わずに)ぼやける、かつ、光加減が良くない条件、つまり上図でいうと4つの角の条件です。この悪条件でのリスクを示すことができれば、実運用時の精度を担保できそうです。
合計 1400 個の評価サンプルを光加減と焦点の条件ごとに振り分けて評価したのが下図左です。ここでは検査機器の保証値にしたがって、考えられる最悪条件で不良検出の精度がどうなるかを評価しています。保証範囲を超えた最悪条件でも 90% 程度の精度が出ており、実運用時にどのようなスペックの検査機器に搭載したとしても、理論上は検査機器のスペックは黒枠の保証範囲内で収まっているはずなので、黒枠外の最悪条件以上の精度で分類してくれることを期待できます。もちろん光加減と焦点以外のリスクがある場合はこの評価だけでは十分ではありませんが、リスクがある程度想定できる場合は有効な評価手段だと言えます。何も考えずに 1400 個のサンプルをスペック中心値のみで評価をした例 (下図右) と比較すると、評価の質が全く違います。こちらでは、明るさや焦点距離に対するリスクの大きさが全くわかりませんし、最悪条件でどの程度正しく判定してくれるかも分かりません。

仮にその最悪条件を反映したデータが実在しなくても、データに適切な変換を加えることでも疑似的に同じような評価ができます。例えば、光加減は画像に明度の操作をすること再現できますし、焦点距離も画像の解像度を下げることで疑似的に再現できます。このように疑似的に作成した最悪条件でどの程度の精度が出るかを確かめるのも、簡単にできる有効な評価方法です。
終わりに
第3回目では、プロジェクトで頻出する問題とどう向き合い、解決すればよいかを説明しました。実際のプロジェクトはこれ以外にも困難な問題が発生しますが、鉄則としては「データと向き合う」です。機械学習はデータからさまざまなことを学べますが万能ではありませんので、我々がデータを見て機械学習のサポートをしないとなりません。
次回の記事では、説明性があるAI (XAI) とその活用方法について見ていきます。
このブログのように、「いかにして機械学習を使って現実世界の問題を解決するか」を解説した本を書いています。ここで書いたことより詳しく書いていますので、気になった方はぜひ手に取ってみてください。
記事を書くために、多くの調査や論文の読み込みを行っております。情報発信を継続していくためにも、サポートをいただけると非常に嬉しいです。