
SEO担当者必見!Googleの検索アルゴリズムが漏洩:今後のSEO対策の詳細

下記のリーク記事によると、Googleの検索アルゴリズムに関する内部ドキュメントが漏洩し、ランキングシステムや機能についての詳細が明らかになりました。特に注目すべき点は、Googleが「ドメインオーソリティ」や「クリックのランキングへの影響」を使っていないと公言していたにもかかわらず、実際にはそれらが使用されていることが判明したことです。この漏洩により、SEO業界にとって重要な洞察が得られました。
漏洩の原因については、記事によると内部関係者が関与していた可能性が高いとのことです。具体的な原因や状況については詳細に明らかにされていませんが、内部の人間による情報流出が疑われています。この漏洩は、機密情報がどのように保護されているかに関する懸念を引き起こしています。以下、全文の翻訳を掲載していきます。
漏洩したアルゴリズムの詳細
Google の内部マイクロサービスは、Google Cloud Platform が提供するものを反映しているようですが、廃止された Document AI ウェアハウスの内部バージョンのドキュメントが、クライアント ライブラリのコード リポジトリに誤って公開されました。このコードのドキュメントは、外部の自動ドキュメント サービスによってもキャプチャされました。
変更履歴によると、このコード リポジトリの間違いは 5 月 7 日に修正されましたが、自動化されたドキュメントはまだ有効です。潜在的な責任を制限するために、ここではリンクしませんが、そのリポジトリのすべてのコードは Apache 2.0 ライセンスの下で公開されているため、それを目にしたすべての人に、とにかくそれを使用、変更、配布する能力を含む広範な権利が付与されています。

Googleは嘘をついていた
Google が長年にわたって私たちに伝えてきたこと/嘘をついてきたことに基づいて、最も興味深いランキング システムと機能 (少なくとも、この大規模なリークをレビューした最初の数時間で見つけることができたもの) のいくつかを文脈化することです。
14,000のランキング機能などが記載されています
API ドキュメントには、次のような 14,014 個の属性 (機能) を持つ 2,596 個のモジュールが表されています。
モジュールは、YouTube、アシスタント、ブック、動画検索、リンク、ウェブ ドキュメント、クロール インフラストラクチャ、内部カレンダー システム、People API のコンポーネントに関連しています。Yandex と同様に、Google のシステムはモノリシック リポジトリ (または「モノレポ」) で動作し、マシンは共有環境で動作します。つまり、すべてのコードが 1 か所に保存され、ネットワーク上のどのマシンも Google のシステムの一部になることができます。

漏洩したドキュメントには、API の各モジュールの概要が示されており、概要、タイプ、関数、属性に分類されています。私たちが確認している内容のほとんどは、ランキング システム全体でアクセスされ、SERP (検索エンジン結果ページ - ユーザーがクエリを実行した後に Google が表示するページ) を生成するさまざまなプロトコル バッファー(または protobuf) のプロパティ定義です。

APIドキュメントが注目すべき嘘を暴露
Google の広報担当者は、SEO 担当者の行動をコントロールするために、システムのさまざまな側面で私たちを誤解させ、ミスリードしようと努力してきました。この用語には重い歴史があるため、これを「ソーシャル エンジニアリング」と呼ぶことはしません。代わりに「ガスライティング」と呼びましょう。Google の公式声明は、意図的に嘘をつくのではなく、潜在的なスパマー (および多くの正当な SEO 担当者) を騙して、検索結果に影響を与える方法を私たちに悟らせないようにするためのものでしょう。
以下では、Google 社員の主張と、限られたコメントを添えてドキュメントからの事実を紹介しますので、ご自身で判断してください。
「ドメイン オーソリティ」は使用していないは嘘
Google の広報担当者は、「ドメイン オーソリティ」は使用していないと何度も述べています。
ドメイン オーソリティを使用しないと言っているということは、Moz の「ドメイン オーソリティ」という指標を特に使用していないと言っている可能性があります。また、Web サイトに関連する特定の主題 (またはドメイン) のオーソリティまたは重要性を測定していないと言っている可能性もあります。この意味論による混乱により、サイト全体のオーソリティ指標を計算または使用しているかどうかという質問に直接答えることができません。
ウェブサイト作成者を支援するための情報の公開に注力している Google 検索チームのアナリスト、ゲイリー・イリーズ氏は、この主張を何度も繰り返しています。

そして、ゲイリーだけではありません。「Google 検索関係を調整する検索アドボケート」のジョン・ミューラーは、このビデオで「私たちにはウェブサイトの権威スコアはありません」と明言しました。
実際には、ドキュメントごとに保存される圧縮品質シグナルの一部として、Google は「siteAuthority」と呼ばれる機能を計算します。

この指標が下流のスコアリング機能でどのように計算され、どのように使用されるかは具体的にはわかりませんが、それが存在し、ランキング システムで使用されていることは確実にわかっています。
クリックで使用して Web 検索のランキングを上昇下降
最近、 DOJ 反トラスト裁判における Pandu Nayak の証言で、 Glue および NavBoost ランキング システムの存在が明らかになりました。NavBoost は、クリック主導の手段を使用して Web 検索のランキングを上昇、下降、または強化するシステムです。Nayak は、Navboost は 2005 年頃から存在し、これまで 18 か月分のクリック データを使用していたと述べています。このシステムは最近更新され、13 か月分のデータを使用するようになり、Web 検索結果に重点を置いています。一方、Glue と呼ばれるシステムは、他のユニバーサル検索結果に関連付けられています。しかし、その暴露以前から、クリック ログを使用して結果を変更する方法を具体的に示す特許がいくつかありました (2007 年のTime Based Ranking特許を含む)。
Google の公式声明を無批判に繰り返す記事
また、クリック数を成功の尺度として用いることは、情報検索におけるベストプラクティスであることもわかっています。Google は機械学習主導のアルゴリズムに移行しており、ML ではパフォーマンスを改良するために応答変数が必要であることもわかっています。この驚くべき証拠にもかかわらず、Google の広報担当者の誤った指示や、検索マーケティングの世界全体で Google の公式声明を無批判に繰り返す記事が公開されているため、SEO コミュニティでは依然として混乱が続いています。
1 つの大きなシグナルが他のシグナルを支配するのを防ぐ機能
ゲイリー・イリーズは、このクリック測定の問題に何度も言及しています。あるとき、彼は、Google 検索エンジニアのポール・ハールが2016 年の SMX West でのライブ実験に関する講演で述べたことを補強し、 「クリックをランキングに直接使用するのは間違いだ」と述べました。
実際には、Navboost にはクリック信号に完全に焦点を当てた特定のモジュールがあります。
そのモジュールの概要では、これを「ランキング システムの 1 つである Craps のクリックとインプレッションのシグナル」と定義しています。以下に示すように、悪いクリック、良いクリック、最後の最長クリック、圧縮されていないクリック、および圧縮されていない最後の最長クリックはすべて、メトリックとして考慮されます。Google の「場所の顕著性に基づいてローカル検索結果にスコアを付ける」特許によると、「圧縮は、1 つの大きなシグナルが他のシグナルを支配するのを防ぐ機能です。」つまり、システムはクリック データを正規化して、クリック シグナルに基づく暴走操作が行われないようにします。Google の社員は、特許やホワイト ペーパーに記載されているシステムが必ずしも実際のシステムと同じではないと主張していますが、NavBoost が Google の情報検索システムの重要な部分でなければ、構築して組み込むのは無意味なことです。
SERP 位置で期待されるクリック数を獲得していない
クリックベースの測定の多くは、インデックス シグナルに関連する別のモジュールにも含まれています。測定の 1 つは、特定のドキュメントに対する「最後の有効なクリック」の日付です。これは、コンテンツの衰退 (または時間の経過によるトラフィックの減少) も、ランキング ページがその SERP 位置で期待されるクリック数を獲得していないことによるものであることを示しています。
「Navboost」という名前が 84 回指定
さらに、ドキュメントではユーザーを投票者として表し、そのクリックが投票として保存されます。システムは不正なクリックの数をカウントし、国とデバイスごとにデータをセグメント化します。
また、セッション中にどの結果が最も長くクリックされたかも保存されます。したがって、検索を実行して結果をクリックするだけでは不十分で、ユーザーはそのページでかなりの時間を費やす必要があります。長いクリックは、滞在時間と同様に検索セッションの成功の尺度ですが、このドキュメントには「滞在時間」と呼ばれる特定の機能はありません。それでも、長いクリックは事実上同じことの尺度であり、この件に関するGoogle の声明と矛盾しています。
さまざまな情報源によると、 NavBoost は「すでに Google の最も強力なランキング シグナルの 1 つ」だそうです。漏洩したドキュメントでは、「Navboost」という名前が 84 回指定されており、タイトルに Navboost を冠したモジュールが 5 つあります。また、サブドメイン、ルート ドメイン、URL レベルでのスコアリングを検討しているという証拠もあり、これは本質的に、サイトの異なるレベルを異なる方法で扱っていることを示しています。
サンドボックスは存在した
Googleの広報担当者は、ウェブサイトが年齢や信頼シグナルの欠如に基づいて隔離されるサンドボックスは存在しないと断言し、現在は削除されたツイートで、ジョン・ミュラー氏は、ランキングの対象となるまでにどのくらいの時間がかかるかという質問に「サンドボックスは存在しない」と回答しました。
しかしながら、PerDocData モジュールのドキュメントには、特に「配信時に新しいスパムをサンドボックス化するために」使用される hostAge という属性が示されており、サンドボックスがあることがわかりました。
ページ品質スコアに関連するモジュールの 1 つは、Chrome からのサイトレベルのビュー測定機能を備えています。サイトリンクの生成に関連していると思われる別のモジュールにも、Chrome 関連の属性があります。
GOOGLE のランキング システムのアーキテクチャ
ドキュメントで参照されているさまざまなシステムに基づくと、100 を超えるさまざまなランキング システムがある可能性があります。これらがすべてのシステムではないと仮定すると、おそらく個別のシステムのそれぞれが「ランキング シグナル」を表しており、Google がよく話す 200 のランキング シグナルは、そのようにして得られたものなのかもしれません。
Jeff Dean 氏の「Google でのソフトウェア システムの構築とそこから学んだ教訓」という講演では、Google の初期のバージョンでは、各クエリを 1,000 台のマシンに送信し、250 ミリ秒未満で処理して応答していたと述べられています。また、システム アーキテクチャの抽象化の初期バージョンを図式化しました。この図は、Super Root が Google 検索の頭脳であり、クエリを送信して最後にすべてをまとめることを示しています。

著名な研究エンジニアである Marc Najork 氏は、最近のGenerative Information Retrieval プレゼンテーションで、RAG システム (別名 Search Generative Experience/AI Overviews) を使用した Google 検索の抽象化モデルを紹介しました。この図は、結果のさまざまなレイヤーを処理する一連の異なるデータ ストアとサーバーを示しています。

内部告発者Zach Vorhies 氏のリースしたスライド
Google の内部告発者、Zach Vorhies 氏が、Google 内のさまざまなシステムの関係を内部名で示すこのスライドをリークしました。これらのいくつかはドキュメントで参照されています。

これら 3 つの高レベル モデルを使用すると、これらのコンポーネントがどのように連携するかについて考え始めることができます。ドキュメントから収集した情報によると、この API はGoogle の Spanner上に存在しているようです。Spanner は基本的に、グローバルにネットワーク化された一連のコンピューターを 1 つとして扱いながら、コンテンツのストレージとコンピューティングの無限のスケーラビリティを可能にするアーキテクチャです。
確かに、ドキュメントだけからすべての関係をつなぎ合わせるのはやや困難ですが、Paul Haahr の履歴書には、いくつかの名前付きランキング システムが何をするのかについての貴重な洞察が示されています。私が知っているものを名前でハイライトし、機能ごとに分類してみます。
クロールの仕組みについて
クロールする
Trawler – Web クロール システム。クロールキューを備え、クロール レートを維持し、ページが変更される頻度を把握します。
インデックス作成
Alexandria –コアインデックスシステム。
SegIndexe r –階層化されたドキュメントをインデックス内の階層に配置するシステム。
TeraGoogle –ディスク上に長期保存されるドキュメントのセカンダリ インデックス システム。
レンダリング
HtmlrenderWebkitHeadless – JavaScript ページのレンダリング システム。奇妙なことに、これは Chromium ではなく Webkit にちなんで名付けられています。ドキュメントには Chromium についての言及があるので、Google は当初 WebKit を使用していて、Headless Chrome の登場後に切り替えたと考えられます。
処理
LinkExtractor –ページからリンクを抽出します。
WebMirror –正規化と複製を管理するためのシステム。
ランキング
ムスタング –主要なスコアリング、ランキング、サービングシステム
Ascorer – 再ランキング調整の前にページをランク付けする主要なランキング アルゴリズム。
NavBoost –ユーザー行動のクリックログに基づいた再ランキング システム。
FreshnessTwiddler –新鮮さに基づいてドキュメントを再ランク付けするシステム。
WebChooserScorer –スニペットのスコアリングで使用される機能名を定義します。
サービング
Google Web Server – GWS は、Google のフロントエンドがやり取りするサーバーです。ユーザーに表示するデータのペイロードを受信します。
SuperRoot –これは Google 検索の頭脳であり、Google のサーバーにメッセージを送信し、結果の再ランク付けと表示のための後処理システムを管理します。
SnippetBrain –結果のスニペットを生成するシステム。
Glue –ユーザーの行動を利用して普遍的な結果をまとめるシステム。
クックブック –シグナルを生成するシステム。実行時に値が作成されるという兆候があります。
前述したように、これらのドキュメントにはさらに多くのシステムが概説されていますが、それらが何をするのかは完全には明らかではありません。たとえば、上の図の SAFT と Drishti もこれらのドキュメントに示されていますが、その機能は不明です。
TWIDDLERS とは何ですか?
Twiddler 全般に関するオンライン情報は限られているため、ドキュメントで遭遇するさまざまな Boost システムをより適切に文脈化できるように、ここで説明する価値があると思います。
検索アルゴリズムの後に実行される再ランク付け機能
Twiddler は、主要な Ascorer 検索アルゴリズムの後に実行される再ランク付け機能です。WordPress のフィルターやアクションの動作に似ており、表示される内容はユーザーに表示される直前に調整されます。Twiddler は、ドキュメントの情報検索スコアを調整したり、ドキュメントのランクを変更したりできます。多くのライブ実験や、私たちが知っている名前付きシステムは、このように実装されています。この Xoogler が示すように、これらはさまざまな Google システムで非常に重要です。

結果の種類を具体的に制限することで多様性を促進
Twiddlers はカテゴリ制約を提供できます。つまり、結果の種類を具体的に制限することで多様性を促進できます。たとえば、著者は特定の SERP にブログ投稿を 3 件だけ許可するように決定できます。これにより、ページ形式に基づいてランキングが絶望的である場合を明確にできます。
GoogleがPandaのようなものはコアアルゴリズムの一部ではないと言った場合、それはおそらく、再ランキングのブーストまたは降格の計算のためのTwiddlerとして開始され、その後、主要なスコアリング機能に移動されたことを意味します。サーバー側とクライアント側のレンダリングの違いに似ていると考えてください。
おそらく、Boost サフィックスを持つ関数はすべて、Twiddler フレームワークを使用して動作します。ドキュメントで特定されている Boost の一部を次に示します。
ナビブースト
品質向上
リアルタイムブースト
ウェブイメージブースト
SEO の実施方法に影響を与える可能性のある重要な発見
では、あなたが本当に知りたいことを見てみましょう。Google は私たちが知らなかった、または確信が持てなかったことを何を行っているのでしょうか。また、それが SEO の取り組みにどのような影響を与えるのでしょうか。
パンダアップデートの仕組み
Panda がロールアウトされたとき、多くの混乱がありました。これは機械学習ですか? ユーザー シグナルを使用しますか? 回復するにはなぜ更新またはリフレッシュが必要ですか? サイト全体ですか? 特定のサブディレクトリのトラフィックが失われたのはなぜですか?
Panda は Amit Singhal の指揮の下でリリースされました。Singhal は、観測可能性が限られているため、機械学習に断固として反対していました。実際、Panda のサイト品質に焦点を当てた一連の特許がありますが、私が注目したいのは、目立たない 「検索結果のランク付け」です。この特許は、Panda が私たちが考えていたよりもはるかにシンプルであることを明確にしています。主に、ユーザーの行動と外部リンクに関連する分散信号に基づいてスコアリング モディファイアを構築することでした。このモディファイアは、ドメイン レベル、サブドメイン、またはサブディレクトリ レベルで適用できます。
「システムは、独立リンクの数と参照クエリの数からリソース グループの修正係数を生成します (ステップ 306)。たとえば、修正係数は、グループの独立リンクの数とグループの参照クエリの数の比率にすることができます。つまり、修正係数 (M) は次のように表すことができます。
M=IL/RQ、
ここで、IL はリソース グループに対してカウントされた独立リンクの数であり、RQ はリソース グループに対してカウントされた参照クエリの数です。」
参照クエリはもう少し複雑
独立リンクは基本的にルートドメインのリンクと考えられているものですが、参照クエリはもう少し複雑です。特許では次のように定義されています。
「特定のリソース グループに対する参照クエリは、特定のリソース グループ内のリソースを参照するものとして分類された、以前に送信された検索クエリである可能性があります。特定の以前に送信された検索クエリを特定のリソース グループ内のリソースを参照するものとして分類することは、特定の以前に送信された検索クエリに、特定のリソース グループ内のリソースを参照すると判断された 1 つ以上の用語が含まれているかどうかを判断することを含む可能性があります。」
このドキュメントにアクセスできるようになったので、参照クエリが NavBoost からのクエリであることは明らかです。

これは、Panda の更新が、Core Web Vitals の計算機能と同様に、クエリのローリング ウィンドウに対する更新に過ぎなかったことを示唆しています。また、リンク グラフの更新が Panda ではリアルタイムで処理されなかったことも意味している可能性があります。
繰り返しになりますが、Panda の別の特許である「サイト品質スコア」でも、参照クエリとユーザーの選択またはクリックの比率であるスコアが検討されています。
役立つコンテンツ アップデートから回復するには
ここでの肝心なことは、ランキングを維持したいのであれば、より幅広いクエリを使用してより多くのクリックを成功させ、より多様なリンクを獲得する必要があるということです。概念的には、非常に強力なコンテンツがそれを実現するので、それは理にかなっています。より質の高いトラフィックを誘導してユーザー エクスペリエンスを向上させることに重点を置くと、ページがランキングに値するというシグナルが Google に送信されます。役立つコンテンツ アップデートから回復するには、同じことに重点を置く必要があります。
著者は明確な特徴である
EEAT については多くのことが書かれています。多くの SEO 担当者は、専門性と権威を評価することがいかに曖昧であるかという理由で、信じていません。また、私は以前、Web 上で著者マークアップが実際にどれほど少ないかを強調しました。ベクター埋め込みについて学ぶ前は、著者が Web 規模で十分に有効なシグナルであるとは信じていませんでした。

ページ上のエンティティがその作成者でもあるかどうかを判断
また、ページ上のエンティティがページの作成者でもあるかどうかを判断します。これを、これらのドキュメントで紹介されているエンティティと埋め込みの詳細なマッピングと組み合わせると、著者の包括的な測定が行われていることは明らかです。
降格
ドキュメントでは、一連のアルゴリズムによる降格について説明されています。説明は限られていますが、言及する価値はあります。Panda についてはすでに説明しましたが、私が目にした残りの降格は次のとおりです。
アンカーの不一致 –リンクがリンク先のターゲット サイトと一致しない場合、そのリンクは計算で順位が下がります。前にも述べたように、Google はリンクの両側の関連性を求めています。
SERP 降格 – SERP から観察された要因に基づいて降格を示すシグナル。クリック数によって測定される可能性のある、ページに対するユーザーの潜在的な不満を示唆します。
ナビゲーションの降格 – おそらく、これはナビゲーション方法が不十分であったり、ユーザー エクスペリエンスに問題があるページに適用される降格です。
完全一致ドメインの降格 – 2012 年後半、Matt Cutts は完全一致ドメインがこれまでほどの価値を得られないと発表しました。降格には特定の機能があります。
製品レビューの降格 –これについては具体的な情報はありませんが、降格としてリストされており、おそらく2023 年の最近の製品レビューの更新に関連しています。
場所の降格 – 「グローバル」ページと「スーパー グローバル」ページが降格される可能性があるという兆候があります。これは、Google がページを場所に関連付け、それに応じてランク付けしようとしていることを示しています。
ポルノ業界の降格 –これはかなり明白です。
その他のリンクの降格 –次のセクションで説明します。
これらすべての潜在的な降格は戦略を策定する上で役立ちますが、正直に言えば、結局のところは強力なユーザー エクスペリエンスを備えた優れたコンテンツを作成し、ブランドを構築することに尽きます。
リンクは依然としてかなり重要だと思われる
リンクはそれほど重要ではないとみなされているという最近の主張を反証する証拠は見当たりません。繰り返しますが、これは情報がどのように保存されるかではなく、スコアリング関数自体で処理される可能性が高いです。とはいえ、リンク グラフを深く理解するために、特徴を抽出して設計することに細心の注意が払われてきました。
インデックス階層はリンクの価値に影響を与える
ページがインデックスされている場所とその価値の間の緩やかな関係を示す、sourceType と呼ばれる指標。簡単に説明すると、Google のインデックスは階層化されており、最も重要で、定期的に更新され、アクセスされるコンテンツはフラッシュ メモリに保存されます。重要度の低いコンテンツはソリッド ステート ドライブに保存され、不定期に更新されるコンテンツは標準のハード ドライブに保存されます。
「新鮮」なページは高品質とみなされる
つまり、階層が高ければ高いほど、リンクの価値が高くなります。「新鮮」とみなされるページは、高品質ともみなされます。つまり、リンクは新鮮なページか、上位階層で取り上げられているページから取得する必要があります。これは、ランキングの高いページやニュース ページからランキングを取得すると、ランキング パフォーマンスが向上する理由を部分的に説明しています。ご覧ください。デジタル PR が再びクールになりました!
リンクスパム速度シグナル
スパム アンカー テキストの急増の識別に関する一連の指標があります。 phraseAnchorSpamDays 機能に注目すると、Google はスパムのリンク速度を効果的に測定できることがわかります。
これを使えば、サイトがスパム行為を行っているかどうかを簡単に特定し、ネガティブ SEO 攻撃を無効にすることができます。後者について懐疑的な人のために説明すると、Google はこのデータを使用してリンク検出のベースラインを現在の傾向と比較し、どちらの方向のリンクもカウントしないようにすることができます。
Googleはリンクを分析する際に、特定のURLの最後の20件の変更のみを使用します。
以前、Google のファイル システムが Wayback Machine と同様にページのバージョンを時間の経過とともに保存できることについて説明しました。私の理解では、Google はインデックスしたものを永久に保持します。これは、ページを無関係なターゲットにリダイレクトするだけではリンク エクイティが流れると期待できない理由の 1 つです。

これにより、Google で「クリーンな状態」を得るためにはページを何回変更してインデックスに登録する必要があるかがわかります。
ホームページのPageRankはすべてのページに適用
すべてのドキュメントには、ホームページの PageRank (Nearest Seed バージョン) が関連付けられています。これは、新しいページが独自の PageRank を取得するまで、新しいページのプロキシとして使用される可能性があります。
新しいページで独自の PageRank が計算されるまで、これと siteAuthority が新しいページのプロキシとして使用される可能性があります。
ホームページの信頼
Google は、ホームページをどれだけ信頼しているかに基づいてリンクを評価する方法を決定します。リンクの量ではなく、リンクの品質と関連性に重点を置く必要があります。
用語とリンクのフォントサイズは重要
2006 年に SEO を始めたとき、私たちが行っていたことの 1 つは、テキストを太字にしたり下線を引いたり、特定の文章を大きくして、より重要に見えるようにすることでした。過去 5 年間で、それは今でも行う価値があると言う人を目にしてきました。私は懐疑的でしたが、今では Google がドキュメント内の用語の平均重み付けフォント サイズを追跡していることがわかりました。
ペンギンアップデートが内部リンクを削除
アンカー関連のモジュールの多くでは、「ローカル」という概念は同じサイトを意味します。この droppedLocalAnchorCount は、一部の内部リンクがカウントされていないことを示しています。
否認について言及した箇所は一つもなかった
否認データは他の場所に保存することもできますが、この API には特に保存されていません。品質評価者のデータがここから直接アクセスできるため、特にそう感じます。これは、否認データがコアランキング システムから切り離されていることを示しています。

私の長年の仮説は、否認は Google のスパム分類器を訓練するためのクラウド ソース機能エンジニアリングの取り組みであるというものでした。データが「オンライン」ではないことから、これが真実である可能性が示唆されます。
リンクについてさらに話を続け、IndyRank、PageRankNS などの機能について話すこともできますが、Google はリンク分析を非常にうまく行っており、Google が行っていることの多くは、当社のリンク インデックスでは近似できないと言えば十分でしょう。今読んだ内容に基づいて、リンク構築プログラムを再検討する絶好の機会です。
文書が切り捨てられる
Google はトークンの数と、本文の合計語数と固有トークン数の比率をカウントします。ドキュメントには、Mustang システムでは特にドキュメントに考慮できるトークンの最大数があることが示されており、作成者は引き続き最も重要なコンテンツを先頭に配置する必要があることが強調されています。
短いコンテンツは独創性で評価される
OriginalContentScore は、短いコンテンツは独創性に基づいてスコア付けされることを示しています。おそらくこれが、薄いコンテンツが必ずしも長さの関数ではない理由です。
ページタイトルは依然としてクエリに基づいて評価される
ドキュメントには、titlematchScore があることが示されています。説明によると、ページ タイトルがクエリとどの程度一致するかは、Google が積極的に評価している点です。ターゲットキーワードを最初に配置することは、依然として有効な手段です。
文字数を数える手段はない
ゲイリー・イリーズ氏は、 SEO がメタデータの最適な文字数をすべて決めていると述べています。このデータセットには、ページ タイトルやスニペットの長さをカウントするメトリックはありません。ドキュメントで見つけた唯一の文字数カウントの指標は、スニペットの一部として何が使用できるかを決定するために設定されていると思われる snippetPrefixCharCount です。
これは、私たちが何度もテストしてきたことを裏付けるもので、長いページタイトルはクリックを促進するには最適ではありませんが、ランキングを促進するには適しています。
日付は非常に重要
Google は最新の結果に非常に重点を置いており、文書には日付とページを関連付ける多数の試みが示されています。
bylineDate –これはページ上で明示的に設定された日付です。

syntacticDate –これは URL またはタイトルから抽出された日付です。

semanticDate –これはページのコンテンツから派生した日付です。

ここで最も良いのは、日付を指定して、構造化データ、ページ タイトル、XML サイトマップ全体で一貫性を保つことです。ページの他の場所の日付と競合する日付を URL に入れると、コンテンツのパフォーマンスが低下する可能性があります。
ドメイン登録情報はページに保存
Google がレジストラとしてその地位にあることがアルゴリズムに情報を与えているという陰謀説は、長年続いてきました。これは陰謀の事実にまで昇華できます。Google は最新の登録情報を複合ドキュメント レベルで保存しています。
前述のように、これは新しいコンテンツのサンドボックス化を通知するために使用される可能性があります。また、所有権が変更された以前に登録されたドメインをサンドボックス化するために使用される場合もあります。期限切れのドメインの不正使用スパム ポリシーの導入により、最近、これの重要性が高まったのではないかと思います。
動画に特化したサイトは異なる扱いを受ける
サイト上のページの 50% 以上に動画が含まれている場合、そのサイトは動画中心であるとみなされ、異なる扱いを受けます。
あなたのお金、あなたの人生は特にスコア化されます
ドキュメントによると、Google には YMYL Health と YMYL News のスコアを生成する分類器があるようです。

また、これまでに見たことのない「周辺クエリ」についても予測を行い、それが YMYL かどうかを判断します。

最後に、YMYL はチャンク レベルでコア化されており、これはシステム全体が埋め込みに基づいていることを示唆しています。

ゴールドスタンダード文書がある
これが何を意味するのかは示されていませんが、説明には「人間がラベル付けしたドキュメント」と「自動的にラベル付けされた注釈」について書かれています。これは品質評価の機能なのだろうかと思いますが、Google によると品質評価はランキングに影響しないそうです。ですから、私たちには永遠に分からないかもしれません。🤔

サイトの埋め込みはページトピックに沿っているか測定
埋め込みについては後続の投稿で詳しく説明しますが、Google はページとサイトを具体的にベクトル化し、ページの埋め込みとサイトの埋め込みを比較して、ページがどの程度トピックから外れているかを確認していることは注目に値します。
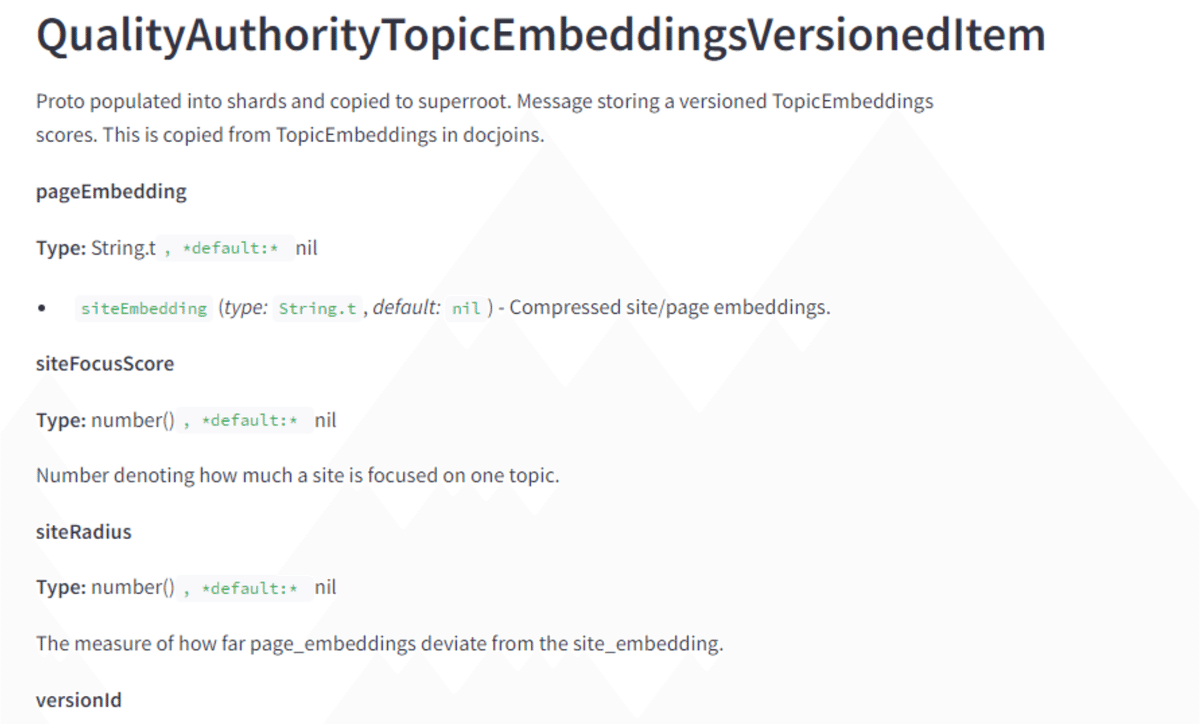
siteFocusScore は、サイトが 1 つのトピックにどれだけ忠実であるかを示します。サイト半径は、サイト用に生成された site2vec ベクトルに基づいて、ページがコア トピックからどれだけ離れているかを示します。
意図的に小規模サイトを攻撃している可能性
Google には、サイトが「小規模な個人サイト」であることを示す特定のフラグがあります。このようなサイトの定義はありませんが、私たちが知っていることすべてに基づくと、Google がそのようなサイトを昇格させたり降格させたりした Twiddler を追加することは難しくないでしょう。

役立つコンテンツの更新によって打撃を受けた中小企業や反発を考えると、彼らがこの機能を使って何か対策を講じているのは不思議です。
ベビーパンダアップデートの存在
圧縮品質シグナルには、「ベイビーパンダ」と呼ばれるものへの言及が 2 つあります。ベイビーパンダは、最初のランキング後に調整される Twiddler です。

Panda 上で動作することについては言及されていますが、ドキュメントにはその他の情報はありません。

役に立つコンテンツ アップデートには、パンダと同じ動作が数多くあるという点については、私たちは概ね同意していると思います。これが参照クエリ、リンク、クリックを使用するシステム上に構築されている場合、コンテンツを改善した後は、それらに重点を置く必要があります。
NSR は Neural Semantic Retrieval を意味する?
命名規則の一部として NSR を含むモジュールと属性への参照が多数あります。これらの多くは、サイト チャンクと埋め込みに関連しています。Google は以前、「ニューラルマッチング」を大きな改善点として取り上げました。私の推測では、NSR はニューラル セマンティック リトリーバルの略で、これらはすべてセマンティック検索に関連する機能です。ただし、いくつかの例では、「サイト ランク」の横に言及しています。
反抗的な Google 社員がgo/NSRに行って、匿名のメール アドレスか何かから「君の言う通りだ」と私に送ってくれたら いいのに。
実行可能なもの
先ほど言ったように、私はあなたに処方箋を持っていません。ただし、戦略的なアドバイスはいくつかあります。
Rand Fishkin に謝罪を送る – PubCon での「Google が私たちに嘘をついたことすべて」という基調講演以来、私は NavBoost に関連して Rand の名誉を回復するためのキャンペーンを行ってきました。Rand は、私たちの業界の向上に何年にもわたって尽力するという、報われない仕事をしてきました。彼は、Google 側と SEO 側から多くの非難を浴びました。時には物事を正しく行えなかったこともありますが、彼の心は常に正しい場所にあり、私たちの仕事が尊重され、より良いものになるよう懸命に努力しました。具体的には、クリック実験の結論、Google Sandbox の存在を示すための繰り返しの試み、Google がサブドメインを異なる方法でランク付けしていることを示すケース スタディ、そして Google がサイト全体の権威スタイルのシグナルを採用しているという長い間軽視されてきた信念について、彼は間違っていませんでした。この分析についても、ドキュメントを私と共有してくれたのは彼なので、彼に感謝しなければなりません。今こそ、皆さんがThreads で彼に愛を示す良い機会です。
素晴らしいコンテンツを作り、それをうまく宣伝する –冗談ですが、本気でもあります。Google はそのようなアドバイスをし続けていますが、私たちはそれを実行不可能として躊躇しています。一部の SEO 担当者にとっては、それは制御不能なことです。Google に利点をもたらすこれらの機能を確認すると、より良いコンテンツを作り、それを共感するオーディエンスに宣伝することが、これらの指標に最も大きな影響を与えることは明らかです。リンクとコンテンツ機能の指標は確かにかなり役立ちますが、Google で長期的に勝ちたいのであれば、ランク付けに値するものを作り続ける必要があります。
相関関係の調査を復活させる – Google がランキング構築に使用している多くの機能について、私たちは今やはるかによく理解しています。クリックストリーム データと機能抽出を組み合わせることで、以前よりも多くのことを再現できます。業種別の相関関係の調査を復活させる時期が来ていると思います。
テストと学習 –すでに Y 軸のビジビリティとトラフィック チャートを十分にご覧になっているはずです。SEO で読んだり聞いたりしたことはどれも信用できないことがおわかりでしょう。このリークは、入力内容を取り入れて実験し、自分の Web サイトに何が効果的かを見極める必要があることのもう 1 つの兆候です。事例レビューを見て、それが Google のやり方だと決めつけるだけでは十分ではありません。組織に SEO の実験計画がない場合は、今が始めるのに良いタイミングです。
この記事が気に入ったらサポートをしてみませんか?