社内勉強会レポート|Standford CS230 |深層強化学習(パート1)

こんにちは。DX2 AI機械学習グループのティンジャン(Ei Thingyan Moe)です。
本記事では、Airitech社内勉強会で学んだ Stanford CS230 深層学習の第5講、Kian Katanforoosh先生による「深層強化学習」をご紹介したいと思います。
本記事は、深層強化学習の導入編になります。本編の続きは、深層強化学習(パート2)をご確認ください。
出典:Stanford CS230:Kian Katanforoosh先生による講義9の深層強化学習
https://cs230.stanford.edu/syllabus/fall_2021/lecture_9.pdf
深層強化学習(DRL)とは何か?
深層強化学習(Deep reinforcement learning)は、(強化学習(reinforcement learning) +深層学習(deep learning))の意味で、人工ニューラルネットワークと、ソフトウェアエージェントが目標を達成するのに役立つ、強化学習のフレームワークを組み合わせたものです。
なぜ強化学習が必要なのですか?
まず、Kian Katanforoosh先生が、強化学習が必要な理由を説明しました。
深層学習では、強化学習アプリケーションなど、解決できないメソッドがいくつかあります。強化学習では、適切な決定を下すことを自動的に学習します。
深層強化学習はごく最近の分野であり、関数を近似する方法として深層学習を使用することは、強化学習アルゴリズムで大きな役割を果たします。
強化学習の例
一つの例として、囲碁ゲームの世界チャンピオンを打ち負かすアルゴリズムを持つDeepmindのAlphaGoがあります。
もう一つの例は、深層強化学習による人間レベルの制御です。強化学習設定にプラグインされたディープラーニングは、さまざまなゲームで人間のレベルを打ち負かすようなエージェントをトレーニングできます。
この講義では、先生は主に、深層強化学習または深層Qネットワーク(deep Q network)によって制御される人間レベルについて話しました。詳しくは、深層強化学習(パート2)で説明します。
古典的な教師あり学習 VS 深層強化学習
古典的な教師あり学習で囲碁をどのように解決しますか?
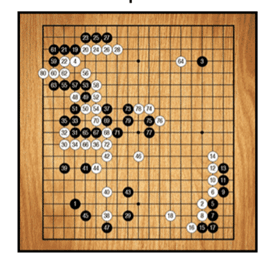
これは、19 x 19のグリッドの碁盤です。囲碁は、2人で対戦します。一人は白い碁石、もう一人は黒い碁石で、碁盤の上に石を並べていきます。
白と黒で、自分の領域を最大化したほうが勝ちです。
これは、次の理由で非常に複雑なゲームです。
・対戦者は長期的な戦略を立てる必要があります。
・碁盤はとても大きいです。
深層学習をうまく使って、このゲームに勝つ、相手を打ち負かすエージェントを構築するには、どのようにすればよいでしょうか?

次のような方法で、エージェントを作成します。
・碁盤が入力になります。
・碁盤から勝つ確率を表示するのは難しいです。
・出力は、碁石の動き、おそらくプロのプレーヤーが取る行動になります。
つまり、プロのプレーヤーが対戦しているのを見て、彼らの動きを記録します。
上記の方法の問題点は何でしょうか?
・このゲームでは、19 x 19のグリッドを表すのに、さまざまなな状態があります。格子には、「碁石なし」、「白い碁石」、「黒い碁石」、の3つの状態があります。これは、およそ「3 ^(19 * 19)」、「10 ^ 170」の状態になります。
・プレイヤーごとに戦略があります。
・これは長期的なプロセスであるため、一般化しない可能性があります。
ー古典的な教師あり学習では、パターンを探しています。猫と犬を検出するために、猫のパターンと犬のパターンが畳み込みフィルターで検索されます。
ーゲームの場合、戦略に関するものです。パターンについてではありません。したがって、次の動きを決定するためには、このゲームに勝つプロセスを理解する必要があります。
このため、強化学習が導入されます。必要なラベルは勝つ確率でした。これは長期的なラベルであり、現在このラベルを取得することはできませんが、時間の経過とともに、終わりに近づくほど、私たちは、勝利をよりよく見ることができ、一連の決定を下す必要があります。
RL(強化学習)は、一連の適切な決定を行うために自動的に学習します。そのため、長期的なものです。短期的なものではなく、このゲームのように、一般的に、ラベルを遅らせたときに使用します。
強化学習アプリケーションの例
・ロボット工学
報酬を使ってロボットを目的の場所まで歩かせるには、ロボットは最初に倒れて負の報酬を受け取ります。すると、ロボットが繰り返し、転倒してはいけないことや、目的の場所への行き方を知るようになります。したがって、ロボットは長期的に試行錯誤と報酬を通じて学習することになっています。
・ゲーム
ゲームは、強化学習アルゴリズムに対する一連の報酬として表すことができます。アルゴリズムを再生して、学習するまで、勝つことの意味と負けることの意味を理解させます。
・広告
広告に予算を投資するには、どの広告が視聴者にとってより魅力的であるかを知る必要があります。強化学習は、ユーザーがクリックする可能性が高い広告を見つけるのに役立ちます。たとえば、ユーザーが広告をクリックすると、報酬数が増加します。
まとめ
Kian Katanforoosh先生は、深層強化学習(DRL)について非常にわかりやすい説明をしました。本記事の強化学習アプリケーションについての説明が、強化学習が、一連の決定を自動的に行うための長期的なプロセスにおいて、どのように役立つかを理解するきっかけになることを願っています。 サンプルの深層強化学習(DRL)の実装については、続編(パート2)をご覧ください。
現在、Airitechではエンジニアを募集しています。
募集中のポジションはこちらです 👇
🔴プロジェクトマネージャー
🔴プロジェクトリーダー
🔴サブリーダー
🔴プログラマー
🔴システムエンジニア
たくさんのご応募をお待ちしています ❕
この記事が気に入ったらサポートをしてみませんか?