
社内勉強会レポート|Standford CS230|深層強化学習(パート2)

こんにちは。DX2 AI機械学習グループのティンジャン(Ei Thingyan Moe)です。
本記事では、Airitech社内勉強会で学んだ Stanford CS230 深層学習の第5講、Kian Katanforoosh先生による「深層強化学習」について、パート1の続きをご紹介したいと思います。
出典:Stanford CS230:Kian Katanforoosh先生による講義9の深層強化学習
https://cs230.stanford.edu/syllabus/fall_2021/lecture_9.pdf
リサイクルは良い:強化学習の紹介

Kian Katanforoosh先生が、「リサイクルは良い」ゲームの環境における、強化学習の例を説明しました。
ゲームには、5つの状態があります。報酬(人間によって定義された数)が決まっており、長期的には、報酬を最も多く獲得することがゴールとなります。
ゲームのフロー
・状態1はゴミ箱で、+2の報酬が得られます。
・状態2はスタートの状態で、ペットボトルを手にした状態で、ゲームを開始することを想定しています。
・目標は、このペットボトルを缶に入れることです。
・ゴミ箱にぶつかると、+2の報酬が得られます。
・状態5にになったらリサイクルのゴミ箱に行き、+10の報酬が得られます。
・状態4にはチョコレートが入っています。 状態4に進むと、チョコレートを食べることができるため、+1の報酬が得られます。また、リサイクルのゴミ箱にチョコレートを入れることもできます。
3つの状態
・ブラウン:スタート状態
・グレー:開始でも終了でもない通常の状態
・青:終了の状態。この状態になるとゲームは終了します。
2通りのアクション
・左に移動
・右に移動
追加のルール
ゴミ箱には、3分後に収集人が来ます。また、それぞれのステップには1分かかります。つまり、このゲームには3分以上費やすことができません。言い換えれば、一つの状態に長くとどまることができません。したがって、このゲームでは3分以上費やすことはできず、終了状態に移動する必要があります。
長期的なリターンをどのように定義しますか?
このゲームの長期的な収益を定義するには、2つの方法(収益と割引累積報酬)があります。先生は、どのリターンを使用するかを決める方法についても教えてくれました。
タイプ1-報酬(Return):終了状態に達したときのポイント数の合計
リターンのサンプルフロー:
・最初:報酬ゼロ・左に移動すると+2の報酬を獲得し、ゲームを終了します。
・右に行くと+11(合計報酬)を獲得します。
タイプ2-割引累積報酬(discounted return):時間は、常に意思決定の重要な要素です。時間が経過するにつれて、報酬も減ります。
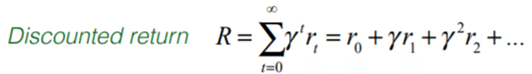
割引累積報酬のサンプルフロー:
・割引値=1の場合、割引がないことを意味します。最善の戦略は、右に進んで+11を取得することです。 (比較:左=> 2、右=> 1+ 1 * 10)
・割引値=0.1の場合、最良の戦略は左に移動して直接+2を取得することです。 (比較:左=> 2、右=> 1+ 0.1 * 10)
・強化学習で非常に一般的な割引である割引値= 0.9の場合、最善の戦略は右に進んで+10を取得することです。 (比較:左=> 2、右=> 1+ 0.9 * 10)
ここでは割引累積報酬を使用しますが、これにはいくつかの利点があります。
時間は、私たちの意思決定において常に重要な要素だからです。
例えば、ロボットにはバッテリーが内蔵されており、動くたびにバッテリーを消耗して、平均寿命は限られています。
先生によれば、迅速に最善の決定をするには、次のことを理解する必要があります。
・何を学びたいですか?
ーそれぞれの状態での最適なアクション。それがまさに私たちが学びたいことです。
・私たちが持つべき数字は何ですか?
ー特定の状態に対するアクション(例:左に移動したり右に移動したりすること)
ーそれぞれの状態のすべてのアクションのスコア/報酬
ースコアを蓄積するには、Qテーブルと呼ばれるマトリックスが必要です。
そこで、Q学習を使用します。

Q学習
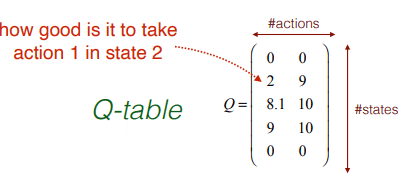
Q学習は、特定の状態でのアクションの値を学習するためのモデルフリーの強化学習アルゴリズムです。 Qテーブルは「状態数*アクション数」の形をしています。状態は行に対応し、アクションは列に対応します。
スコア/報酬のマトリックスがあり、スコアが正しい場合は、Qテーブル(現在の状態の行と最大値の列を選択)を見て、現在の状態から、右または左に移動するかどうかを決定できます。

まず、状態S2にある場合に、アクションを実行するための最良の方法を確認しましょう。状況を理解しやすいようにツリーを構築できます。
・現在S2にいるので、S2から開始します。 S2には、2つのオプションがあります。 (S1に移動して+2を取得するか、S3に移動して0を取得します。)
・S1からはどこにも移動できず、最終状態になります。
・しかし、S3からはS2に行き、戻って0を取得するか、S4に移動して1を取得することができます。
・S4からも同じです。 S3に戻って0を取得するか、S5に移動して+10を取得できます。

上の図で検討した報酬は、すべての状態に対する即時報酬にすぎません。しかし、実際に計算したいのは、すべての状態に対する割引累積報酬です。割引累積報酬は、その状態に行くことで得られる即時報酬であるだけでなく、その状態から得られる最大の報酬でもあります。

状態を選択することによって、将来そこから得ることができる最大の報酬は何ですか?
S3からアクションの値を計算する方法を確認しましょう。
・S3から、S4またはS2に移動できます。
S4に行くと、当面の報酬は1になりますが、S4を選択すると、長期的に最大の報酬として+10を得ることができます。
S4では、割引収益は1 + 0.9 * 10 => + 10になります。つまり、10は、状態S3からすぐに実行されるアクションに与えるスコアです。
・さて、S2の1ステップ前からそれを実行するとどうなるでしょうか。
S2からS3に右に進み、報酬をゼロにすることができます。したがって、即時の報酬はゼロです。しかし、S3からは、最終的に長期的に+10の報酬(割引リターン)を得ることができます。
S3では、割引収益は0 + 0.9 * 10 => 9になります。したがって、状態2では、状態S2から右に移動すると、長期的な報酬が9になります。
・S2では、左に移動して+2を取得できます。 、または右に進み、+ 9を取得できます。 S2では、割引収益は0 + 0.9 * 9 => 8.1になります。

長期割引報酬は9であるのに対し、S1に行くことに対する長期割引報酬は2であるため、最良のアクションはS2からS3に進むことのようです。これがQ学習です。
最適なQ関数は、次の2つの項を持つベルマン方程式に従います。
・1つはRです。
・もう1つはすべてのアクションのQスコアの最大値の割引倍です。
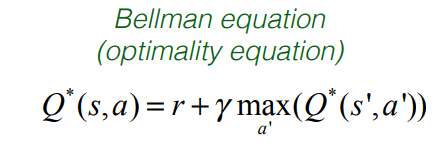
これは、最適なQテーブルまたはQ関数によって満たされる方程式です。
強化学習における語彙のもう1つのポイントは、ポリシーです。 ポリシーは、Piまたはmuとして示されることがあります。これは、最適なQのアクションに対するargmaxに等しくなります。
それが意味するのは、まさに私たちの決定プロセスです。 Qテーブルの状態Sのすべての列を見て、最大値を取ります。 つまり、pi、私たちのポリシーは、最善の戦略を伝える意思決定になります。
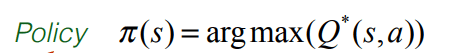
なぜ深層学習が必要なのですか?
実際の囲碁ゲームの場合、マトリックスフローは反復アルゴリズムであり、Qテーブルの使用は、すべての状態とアクションに対する割引累積報酬を表すために複雑になります。
状態とアクションの数が少ない場合は、Qテーブルを簡単に使用できます。 Qテーブルでは、すべての状態を追加できます。Qテーブルを調べるのは非常に迅速で、何を選択すべきかがわかります。 ただし、囲碁の状態の数は約10 ^ 170です。 そのため、Qテーブルの代わりに深層学習のQ関数を使用しています。
深層Q学習
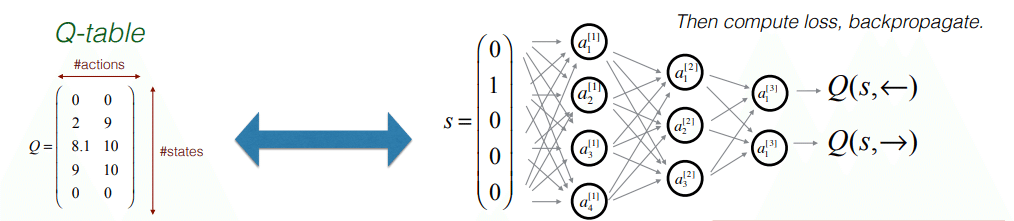
Q関数は、以下のようなニューラルネットワークになります。
・状態を入力としてディープネットワークに転送する。
・アクションスコアの出力を取得する。
このネットワークのトレーニングは、ラベルがないため、従来の教師あり学習設定とは異なります。
ネットワークをトレーニングするにはラベルが必要です。 ここのラベルは何ですか?
ラベルの場合、状態から左Q(s、←)および右Q(s、→)に移動するためのアクションを表すQスコアを使用する必要があります。
長期割引報酬を満たすために使用できる損失関数は、L2損失関数です。 (yからQスコアの2乗を引いたもの)

DQNの実装

まとめ
この勉強会では、DQNを使用したサンプルの深層強化学習ネットワークの段階的な検討と実装フローを学びました。Kian Katanforoosh先生が各ステップの詳細な説明を案内してくれたので、本気記事から貴重な知識を得ることができたと思います。
最後までお読みいただきありがとうございました。
現在、Airitechではエンジニアを募集しています。
募集中のポジションはこちらです 👇
🔴プロジェクトマネージャー
🔴プロジェクトリーダー
🔴サブリーダー
🔴プログラマー
🔴システムエンジニア
たくさんのご応募をお待ちしています ❕
この記事が気に入ったらサポートをしてみませんか?