
【SD】ようやくLoRA学習に手を付け始めました☆

こんばんは。あるいは、こんにちは?
ようやく、LoRA学習の学習をし始めました(笑)
Stable Diffusion以外でも、プログラムが動作しないことがあり、実行権限の設定をいじってみることにしました。
管理者権限での実行
わたしはVisual Studio Code(VSCode, Code)というソフトを使用していますが、今回はPowerShellでvenvを使えるようにするためにセキュリティ設定を変更します。VSCodeでも管理者で開く設定ができるのですが、うまくいかないことがあったため、マニュアル通り設定してみます。
PowerShellで管理者権限
PowerShellを右クリックして管理者として実行します。
Get-ExecutionPolicy -List # セキュリティ設定確認
Set-ExecutionPolicy Unrestricted # sd-scripts:このコードを実行
y
#------------------------------------------------------------
# Set-ExecutionPolicy Restricted # defaultに戻す
# Set-Executionpolicy Remotesigned # (これでもよいらしい)
#------------------------------------------------------------設定を変更したら閉じてよいようです。
おまけ:Visual Studio Codeで管理者権限(やらなくてよいと思います)
・ショートカット「C:\Users\user\Desktop\Visual Studio Code.lnk」を右クリック > プロパティ > 詳細設定 > 「管理者権限として実行」にチェック
・「互換性」タブ > 「管理者としてこのプログラムを実行する」にチェック
・「適用」 > 「OK」


sd-scriptをダウンロード
kohya-ss様のsd-scriptsをダウンロードします。日本語版の説明文書がありますので確認してみてください。
Windows環境でのインストール という項目が中ほどにあります。
通常の(管理者ではない)PowerShellで実行と記載があります。
コマンドプロンプトのコードの記載もあります。
どこにセットアップ(ダウンロード)するか個人で判断します。
どこでもよいと思いますが、経験上、外付けドライブで失敗しています。
今回は「cd /Users/user/Dropbox/GitHub/clone」のように、Dropbox内に入れてみたいと思います。
cd /Users/user/Dropbox/GitHub/clone
git clone https://github.com/kohya-ss/sd-scripts.gitダウンロードできたことを確認して、ディレクトリを「sd-scripts」にします。
Python環境構築を進めます。
「venv」をアクティブにして必要なものをセットアップしていきます。
cd /Users/user/Dropbox/GitHub/clone/sd-scripts
python -m venv venv
./venv/Scripts/activate以下の3行は時間がかかりますので、気長に実行していきます。
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
pip install --upgrade -r requirements.txt
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl以下の3行はすぐに終わりますが、コマンドプロンプトだとコードの内容が異なるため、readmeを確認して、1行ずつ実行するとよいと思います。
cp ./bitsandbytes_windows/*.dll ./venv/Lib/site-packages/bitsandbytes/
cp ./bitsandbytes_windows/cextension.py ./venv/Lib/site-packages/bitsandbytes/cextension.py
cp ./bitsandbytes_windows/main.py ./venv/Lib/site-packages/bitsandbytes/cuda_setup/main.py最後の1行は、質問に答える必要があります。
選択肢がある場合には、数字で回答(数字キーの0、1、2……で選択)することになりますので注意してください(カーソルキーはキャンセルされます。その場合は落ち着いて同じコードを入力しましょう)。
accelerate config回答方法は以下の通りです。
最後の項目は注意して「1」と入力すると選択できます。
- This machine
- No distributed training
- NO
- NO
- NO
- all
- fp16 # <- "1"を入力してenterもし、PowerShellを閉じてしまった場合には、ワーキングディレクトリを「sd-scripts」に移動、「venv」を起動、「accelerate config」を実行します。
cd /Users/user/Dropbox/GitHub/clone/sd-scripts
./venv/Scripts/activate
accelerate configできましたか?
アップデート
新しいバージョンがリリースされた場合には、以下を実行しましょう。
cd /Users/user/Dropbox/GitHub/clone/sd-scripts
git pull
.\venv\Scripts\activate
pip install --use-pep517 --upgrade -r requirements.txt学習方法
学習方法には以下の手法があります。
DreamBooth、class+identifier方式
キャプション不要
特徴(性別、表情、髪型、服装など)を同時に学習するため、プロンプトで特徴を区別させることが困難になる
DreamBooth、キャプション方式
キャプションにより特徴の分離を可能にするため、プロンプトにより生成される画像をコントロールできる
Fine tuning方式
キャプションからメタデータを作成する必要があり上級者向けです。わたしには今のところ無理そう。。。
必要な素材
今回は2つ目を行います。必要な素材は以下の通りです。
学習用画像(教師データ)
正則化画像(必要であれば)
特徴を細かく厳密に区別して画像を描写させたい場合は使用します。
キャラクター生成用であればLoRAを入れる・入れないでコントロールできます。
キャプションファイル(テキストデータ)
準備
学習させるディレクトリを準備していきます。
まずは「LoRA」というフォルダを作成して、その中に必要なものをそろえたいと思います。
「sd-scripts」と同じ場所に並列で作成してみます。
普通に新規作成で「LoRA」フォルダを作成してください。
その中に以下のものを用意しておきます。
「train」フォルダ:学習用画像
「reg」フォルダ:正則化画像
「out」フォルダ:アウトプットデータ
「config.txt」
「command.txt」
# 新しいPowerShellで実行
cd C:/Users/user/Dropbox/GitHub/clone
mkdir LoRA
cd C:/Users/user/Dropbox/GitHub/clone/LoRA
mkdir train, reg, out
Out-File config.txt -encoding UTF8
Out-File command.txt -encoding UTF8学習用画像を準備
学習用の画像はファイル名が連番となるようにしておきましょう。
今回は、学習用素材として汎用されております「東北ずん子」さん関連の画像をお借りしたいと思います。
以下のリンクの中ほどを確認しますと、画像学習用をデータ配布しています。
ダウンロードして展開しましょう。複数のデータが入っていますので、好きなものを選びましょう。
まずはお試しで「itako」さんのデータ(01_LoRA学習用データ_A氏提供版_背景白)を使用したいと思います。
すでにキャプションファイルが作成されていますので、このまま学習できます。
もし、キャプションファイルがない状態で、オリジナルのものを学習させるなどの場合には、タグ付けしてくれる拡張機能を利用するとよいと思います。
キャプションファイルの作成
利用しているのはtoriato様の「stable-diffusion-webui-wd14-tagger」です。
導入方法ですが、GitHubからフォルダをダウンロードするか、「git clone」します。保存先は「/Users/user/Dropbox/GitHub/clone/stable-diffusion-webui/extensions」にしています。
cd /Users/user/Dropbox/GitHub/clone/stable-diffusion-webui/extensions
git clone https://github.com/toriato/stable-diffusion-webui-wd14-tagger.git再起動すると「Tagger」タブが増えていると思います。
今回は、「itako」さんをコピーして「t_itako」とし、キャプションファイルをすべて削除して、「Tagger」に作成してもらいます。
Stable Diffusion Web UIを起動
バッチファイルから起動します。わたしは以前の記事で紹介しているデスクトップに配置している「SD.bat」をダブルクリックしています。
chcp 65001
cd C:/Users/user/Dropbox/GitHub/clone/stable-diffusion-webui
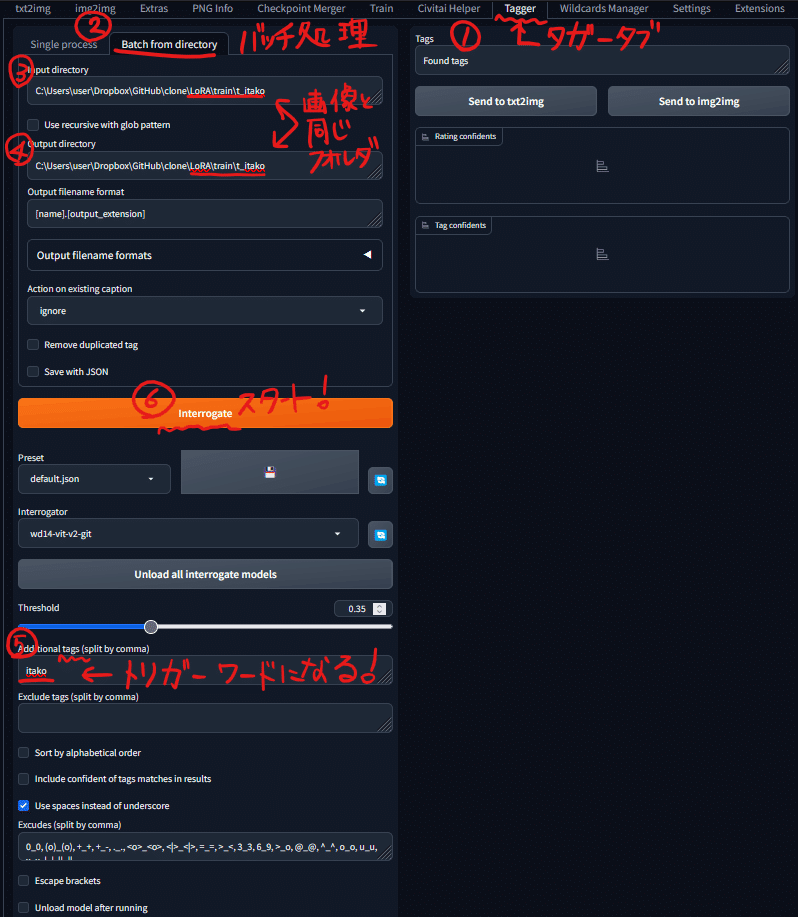
C:/Users/user/AppData/Local/Programs/Python/Python310/python.exe launch.py --administrator --xformers --skip-python-version-check --skip-version-check --autolaunch「Tagger」タグをクリックして、「Batch from directory」を開きます。
タグ付けしたい画像のあるディレクトリと出力先のディレクトリを入力しておきます。今回は、パスをコピペします。
「C:\Users\user\Dropbox\GitHub\clone\LoRA\train\t_itako」
タグ付けを開始する前に、トリガーワードとなる単語「itako」を設定しておきます。
「Interrogate」でキャプションファイル作成開始です。
キャプションファイルの準備
出力したテキストファイルを確認して修正していきます。
キャプション方式では、
学習させたい特徴を表す単語を削除
しますので、注意してください。
itako, 1girl,
animal ears, japanese clothes, solo, kimono,long hair, tabi,purple eyes,fox ears, sash, shawl, white background, full body, wide sleeves,parted bangs, obi, simple background, long sleeves,bangs, hagoromo,very long hair,grey hair, smile,sidelocks, looking at viewer, white kimono,ponytail, hitodama,closed mouth, white socks, socks, standing, sandals,animal ear fluff, :3, spirit, zouri
上述は一例です。
顔や髪の毛にかかわる内容を削除するとキャラクターLoRA
服装にかかわる内容を削除するとコスプレ用LoRA
になると考えられます。
トリガーワードを先頭にして、改行を含まない1文にしましょう。
コンフィグファイルの作成
「config.txt」の編集をします。
[general]
[[datasets]]
[[datasets.subsets]]
image_dir = 'C:\Users\user\Dropbox\GitHub\clone\LoRA\train\t_itako'
caption_extension = '.txt'
num_repeats = 1image_dir = 'C:\Users\user\Dropbox\GitHub\clone\LoRA\train\t_itako'
は学習用画像が格納されているパスを指定します。
num_repeats = 1
は学習の繰り返し回数です。
拡張子を「.toml」にします。
【重要】「.toml」が「UTF-8N形式」になっていることを確認
この時に「.toml」が「UTF-8N形式」になっておらず、「BOM付きUTF-8形式」になっていることがあります。
実行してからTOMLファイルの読み込みエラーを吐き、学習ができません!!(これの解決のために何時間も調べました)
形式の変更の仕方はいくつかあると思いますが、VS Codeで簡単にできました。
コマンドファイルの作成
「command.txt」の編集をします。
PowerShellにコピーペーストして動かすためのものです。
accelerate launch --num_cpu_threads_per_process 1 train_network.py
--pretrained_model_name_or_path=C:\Users\user\Dropbox\GitHub\clone\stable-diffusion-webui\models\Stable-diffusion\2\AnythingV5_v5PrtRE.safetensors
--output_dir=C:\Users\user\Dropbox\GitHub\clone\LoRA\out
--dataset_config=C:\Users\user\Dropbox\GitHub\clone\LoRA\config.toml
--train_batch_size=1
--max_train_epochs=10
--resolution=512,512
--optimizer_type=AdamW8bit
--learning_rate=1e-4
--network_dim=128
--network_alpha=64
--enable_bucket
--bucket_no_upscale
--lr_scheduler=cosine_with_restarts
--lr_scheduler_num_cycles=4
--lr_warmup_steps=500
--keep_tokens=1
--shuffle_caption
--caption_dropout_rate=0.05
--save_model_as=safetensors
--clip_skip=2
--seed=42
--color_aug
--xformers
--mixed_precision=fp16
--network_module=networks.lora
--persistent_data_loader_workersパス(path)の指定
--pretrained_model_name_or_path=
には使用するモデルのパスを指定します。
--output_dir=
には使用する「out」フォルダのパスを指定します。--output_name=
には出力するファイル名を指定します。削除すると「last.safetensors
」が出来上がります。今回は削除しておきましょう。
--dataset_config=
には「config.toml」のパスを指定します。
今回使用するモデルは万象熔炉様の「AnythingV5」です。
学習の条件設定
--train_batch_size=1
2~4にすると学習が早くなりますが、PCパワーに依存します。
--max_train_epochs=10
--resolution=512,512
--optimizer_type=AdamW8bit
--learning_rate=1e-4
--network_dim=128
--network_alpha=64
改行を削除して保存します。
コピーペーストしてコードを実行できるようになります。
オプションの間は半角スペースを入れます。
accelerate launch --num_cpu_threads_per_process 1 train_network.py --pretrained_model_name_or_path=C:\Users\user\Dropbox\GitHub\clone\stable-diffusion-webui\models\Stable-diffusion\2\AnythingV5_v5PrtRE.safetensors --output_dir=C:\Users\user\Dropbox\GitHub\clone\LoRA\out --dataset_config=C:\Users\user\Dropbox\GitHub\clone\LoRA\config.toml --train_batch_size=1 --max_train_epochs=10 --resolution=512,512 --optimizer_type=AdamW8bit --learning_rate=1e-4 --network_dim=128 --network_alpha=64 --enable_bucket --bucket_no_upscale --lr_scheduler=cosine_with_restarts --lr_scheduler_num_cycles=4 --lr_warmup_steps=500 --keep_tokens=1 --shuffle_caption --caption_dropout_rate=0.05 --save_model_as=safetensors --clip_skip=2 --seed=42 --color_aug --xformers --mixed_precision=fp16 --network_module=networks.lora --persistent_data_loader_workersLoRA学習の実行
いよいよ実行します!
通常の(管理者ではない)PowerShellで以下のコードを実行します。
cd /Users/user/Dropbox/GitHub/clone/sd-scripts
./venv/Scripts/activate
accelerate launch --num_cpu_threads_per_process 1 train_network.py --pretrained_model_name_or_path=C:\Users\user\Dropbox\GitHub\clone\stable-diffusion-webui\models\Stable-diffusion\2\AnythingV5_v5PrtRE.safetensors --output_dir=C:\Users\user\Dropbox\GitHub\clone\LoRA\out --dataset_config=C:\Users\user\Dropbox\GitHub\clone\LoRA\config.toml --train_batch_size=1 --max_train_epochs=10 --resolution=512,512 --optimizer_type=AdamW8bit --learning_rate=1e-4 --network_dim=128 --network_alpha=64 --enable_bucket --bucket_no_upscale --lr_scheduler=cosine_with_restarts --lr_scheduler_num_cycles=4 --lr_warmup_steps=500 --keep_tokens=1 --shuffle_caption --caption_dropout_rate=0.05 --save_model_as=safetensors --clip_skip=2 --seed=42 --color_aug --xformers --mixed_precision=fp16 --network_module=networks.lora --persistent_data_loader_workersしばらくすると学習が終わり、「C:\Users\user\Dropbox\GitHub\clone\LoRA\out」の中に「last.safetensors」というファイルが出来上がっていると思います。
Windows PowerShell
Copyright (C) Microsoft Corporation. All rights reserved.
新機能と改善のために最新の PowerShell をインストールしてください!https://aka.ms/PSWindows
PS C:\Users\user> cd /Users/user/Dropbox/GitHub/clone/sd-scripts
PS C:\Users\user\Dropbox\GitHub\clone\sd-scripts> ./venv/Scripts/activate
(venv) PS C:\Users\user\Dropbox\GitHub\clone\sd-scripts> accelerate launch --num_cpu_threads_per_process 1 train_network.py --pretrained_model_name_or_path=C:\Users\user\Dropbox\GitHub\clone\stable-diffusion-webui\models\Stable-diffusion\2\AnythingV5_v5PrtRE.safetensors --output_dir=C:\Users\user\Dropbox\GitHub\clone\LoRA\out --dataset_config=C:\Users\user\Dropbox\GitHub\clone\LoRA\config.toml --train_batch_size=1 --max_train_epochs=10 --resolution=512,512 --optimizer_type=AdamW8bit --learning_rate=1e-4 --network_dim=128 --network_alpha=64 --enable_bucket --bucket_no_upscale --lr_scheduler=cosine_with_restarts --lr_scheduler_num_cycles=4 --lr_warmup_steps=500 --keep_tokens=1 --shuffle_caption --caption_dropout_rate=0.05 --save_model_as=safetensors --clip_skip=2 --seed=42 --color_aug --xformers --mixed_precision=fp16 --network_module=networks.lora --persistent_data_loader_workers
prepare tokenizer
Load dataset config from C:\Users\user\Dropbox\GitHub\clone\LoRA\config.toml
prepare images.
found directory C:\Users\user\Dropbox\GitHub\clone\LoRA\train\t_itako contains 38 image files
38 train images with repeating.
0 reg images.
no regularization images / 正則化画像が見つかりませんでした
[Dataset 0]
batch_size: 1
resolution: (512, 512)
enable_bucket: True
min_bucket_reso: 256
max_bucket_reso: 1024
bucket_reso_steps: 64
bucket_no_upscale: True
[Subset 0 of Dataset 0]
image_dir: "C:\Users\user\Dropbox\GitHub\clone\LoRA\train\t_itako"
image_count: 38
num_repeats: 1
shuffle_caption: True
keep_tokens: 1
caption_dropout_rate: 0.05
caption_dropout_every_n_epoches: 0
caption_tag_dropout_rate: 0.0
color_aug: True
flip_aug: False
face_crop_aug_range: None
random_crop: False
token_warmup_min: 1,
token_warmup_step: 0,
is_reg: False
class_tokens: None
caption_extension: .txt
[Dataset 0]
loading image sizes.
100%|████████████████████████████████████████████████████████████████████████████████████████| 38/38 [00:00<00:00, 247.22it/s]
make buckets
min_bucket_reso and max_bucket_reso are ignored if bucket_no_upscale is set, because bucket reso is defined by image size automatically / bucket_no_upscaleが指定された場合は、bucketの解像度は画像サイズから自動計算されるため、min_bucket_resoとmax_bucket_resoは無 視されます
number of images (including repeats) / 各bucketの画像枚数(繰り返し回数を含む)
bucket 0: resolution (384, 512), count: 7
bucket 1: resolution (384, 576), count: 6
bucket 2: resolution (384, 640), count: 5
bucket 3: resolution (448, 448), count: 3
bucket 4: resolution (448, 512), count: 11
bucket 5: resolution (448, 576), count: 3
bucket 6: resolution (512, 448), count: 2
bucket 7: resolution (768, 320), count: 1
mean ar error (without repeats): 0.031248754778144757
prepare accelerator
Using accelerator 0.15.0 or above.
loading model for process 0/1
load StableDiffusion checkpoint
loading u-net: <All keys matched successfully>
loading vae: <All keys matched successfully>
loading text encoder: <All keys matched successfully>
Replace CrossAttention.forward to use xformers
import network module: networks.lora
create LoRA network. base dim (rank): 128, alpha: 64.0
create LoRA for Text Encoder: 72 modules.
create LoRA for U-Net: 192 modules.
enable LoRA for text encoder
enable LoRA for U-Net
prepare optimizer, data loader etc.
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issuesFor effortless bug reporting copy-paste your error into this form: https://docs.google.com/forms/d/e/1FAIpQLScPB8emS3Thkp66nvqwmjTEgxp8Y9ufuWTzFyr9kJ5AoI47dQ/viewform?usp=sf_link
================================================================================
CUDA SETUP: Loading binary C:\Users\user\Dropbox\GitHub\clone\sd-scripts\venv\lib\site-packages\bitsandbytes\libbitsandbytes_cuda116.dll...
use 8-bit AdamW optimizer | {}
override steps. steps for 10 epochs is / 指定エポックまでのステップ数: 380
running training / 学習開始
num train images * repeats / 学習画像の数×繰り返し回数: 38
num reg images / 正則化画像の数: 0
num batches per epoch / 1epochのバッチ数: 38
num epochs / epoch数: 10
batch size per device / バッチサイズ: 1
gradient accumulation steps / 勾配を合計するステップ数 = 1
total optimization steps / 学習ステップ数: 380
steps: 0%| | 0/380 [00:00<?, ?it/s]
epoch 1/10
steps: 10%|██████▉ | 38/380 [00:55<08:22, 1.47s/it, loss=0.113]
epoch 2/10
steps: 20%|█████████████▌ | 76/380 [01:18<05:12, 1.03s/it, loss=0.0961]
epoch 3/10
steps: 30%|████████████████████▍ | 114/380 [01:40<03:55, 1.13it/s, loss=0.125]
epoch 4/10
steps: 40%|██████████████████████████▊ | 152/380 [02:03<03:04, 1.23it/s, loss=0.0951]
epoch 5/10
steps: 50%|██████████████████████████████████ | 190/380 [02:26<02:26, 1.30it/s, loss=0.111]
epoch 6/10
steps: 60%|████████████████████████████████████████▏ | 228/380 [02:50<01:53, 1.34it/s, loss=0.0969]
epoch 7/10
steps: 70%|██████████████████████████████████████████████▉ | 266/380 [03:13<01:22, 1.38it/s, loss=0.0924]
epoch 8/10
steps: 80%|█████████████████████████████████████████████████████▌ | 304/380 [03:36<00:54, 1.41it/s, loss=0.0823]
epoch 9/10
steps: 90%|████████████████████████████████████████████████████████████▎ | 342/380 [03:59<00:26, 1.43it/s, loss=0.0909]
epoch 10/10
steps: 100%|████████████████████████████████████████████████████████████████████| 380/380 [04:22<00:00, 1.45it/s, loss=0.094]
saving checkpoint: C:\Users\user\Dropbox\GitHub\clone\LoRA\out\last.safetensors
model saved.
steps: 100%|████████████████████████████████████████████████████████████████████| 380/380 [04:24<00:00, 1.43it/s, loss=0.094]
(venv) PS C:\Users\user\Dropbox\GitHub\clone\sd-scripts>自作 itako LoRA つかったみたよ
ここまででとても疲れました。出力結果が楽しみですね。
早速、LoRAを適用したいと思います。
LoRAの使い方は過去の記事に記載しておりますので、ご確認いただけるとうれしいです。
比較のために学習用画像(itako_2.png)を並べ、ポジティブプロンプトに
<lora:achiral_itako_v20230514:1.2>がある→「LoRA(+)」
<lora:achiral_itako_v20230514:1.2>がない→「LoRA(-)」
として、生成画像を配置しています。

髪型や表情(?)が学習成果を反映しているような気がします。ケモミミは追加でプロンプトに入れると反映されやすいです。
「ケモミミワード」を入れない状態では、たまに描画が成功して、ほとんどのケースでは中途半端に耳が溶けて髪型がそれっぽく変化して融合している感じです。
X/Y/Z plotを使用して、シード値は固定し、
X軸:style
Y軸:Prompt S/R
を設定して並べました。

X/Y/Z plotは過去の記事で少しだけ紹介していますので、参考にしていただければ嬉しいです。
小休止(メモ)
本記事に含めるか迷っているのですが、Windows(Macでも)でスペースや全角文字、カッコ、記号などがファイルやフォルダの名称に使用されていると、パス(path)の指定でエラーを起こすことがたびたびあると思います。
特にWindowsではバックスラッシュ「\(¥)」がパスを表す際に使用されます。エスケープ文字としてバックスラッシュ「\(¥)」が認識されることで、エラーが多発します。
なるべくスラッシュに置き換えてコードを紹介してきましたが、今回はとにかくエラーの原因が分からないことも多かったので、Windowsで動かしきることを目的としました。
もしかすると、バックスラッシュをスラッシュにしても動作するかもしれません(記事の修正はせずにこのままにする予定です)。
もう一点、まだ記事の中で紹介できておりませんが、ファイル名の一括変換です。連番で作成する方法は検索ですぐに見つかると思います。Windowsでは標準で機能が搭載されているようです。しかし、「NAME (#)」のような形式となり、半角スペースとカッコが付属します。パス指定時のエラーの要因となりそうです。個人的に気になっているのは、数値の桁数を合わせるかどうかです(1を001にするなど)。プログラムで修正できると思いますが、まだ対応できておりません(過去に処理したこともあると思います)。
今回は、念のために「NAME (#)」→「NAME_#」となるような処理をしてから学習させました。もし、ファイル名でエラーが発生したり、画像の名前がばらばらで連番作成に苦労されている方がおられるようでしたら、どこかで紹介したいと思っています。
追記する予定ですが、学習できたっぽいのでフライング公開しておきます。
(実は、失敗しているかもしれないです)
わたしはプログラマーではなくエンドユーザーですので、トラブルシューティング能力はしょぼしょぼです。あきらめも早いです。皆様の環境で無事にLoRA学習が進むことを願っております!!

コスプレとして許してください♡
この記事が気に入ったらサポートをしてみませんか?