SDのローカル動作版アプリ「Stable Diffusion GRisk GUI 0.1」が公開されました。

2022/08/31追記 別製作者によるtext2img、img2img可能なローカル動作アプリが公開されているようです。
こんにちは。みなさん、StableDiffusionやDreamStudioを触ってますでしょうか。今回は面倒なpytorch環境構築などの必要なく、自分のPC上で手軽にStableDiffusionを動作させられるアプリ「Stable Diffusion GRisk GUI 0.1」が公開されましたので、簡単にご紹介します。どんどん便利になりやがるぜ。
公開ページはこちら
Stable Diffusion GRisk GUI 0.1
まず動作にはVRAM5GB以上のNVIDIA製グラフィックボード(AMD製だとダメっス)が必要ですので、それなりの3Dゲームが動作可能なPCであることが前提となります。ただ最小要求スペックはそれほどでもないです。私は一昔前の2060S(VRAM8GB)で動作させていますが、ツイッターを見ますとVRAM6GBの1060で動かしている人も居ますし、解像度を256*512に落とせば4GBでも動作するようですね。
※追記 現在のバージョンはGTX1650,1660では動作できないようです。
公開ページ下部のDownloadからrarファイルをDLしてきたら、解凍して「Stable Diffusion GRisk GUI.exe」を実行します。
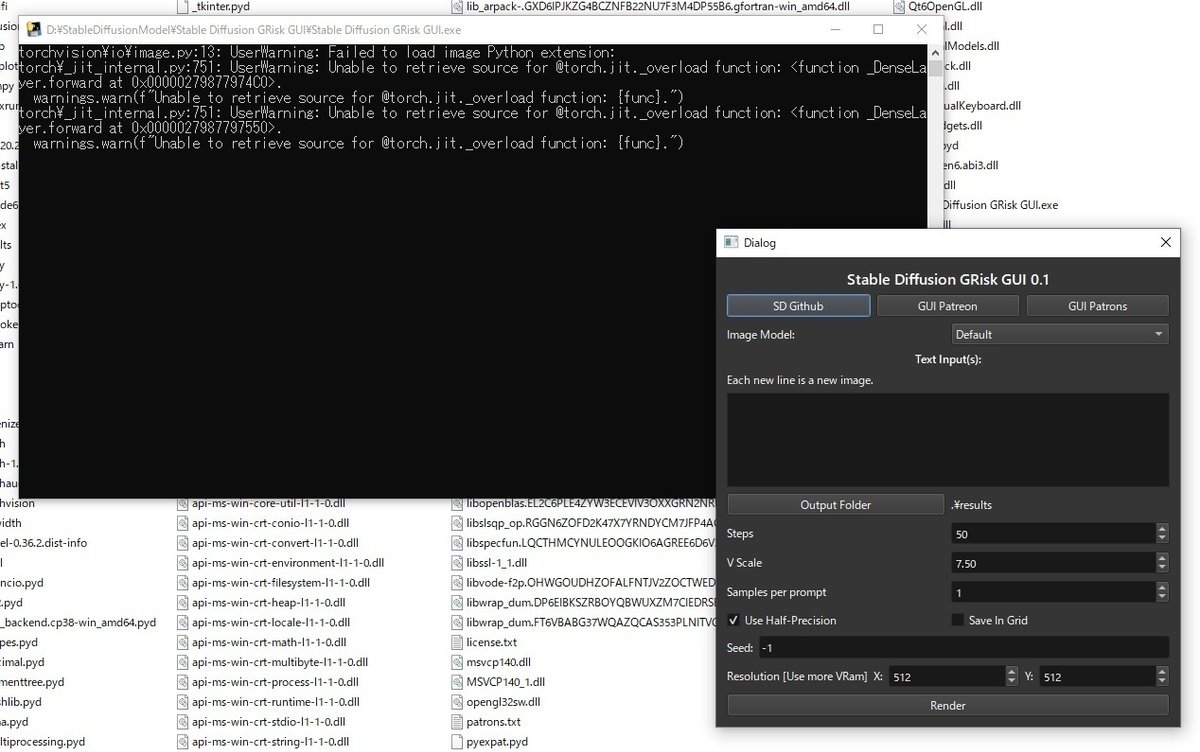
Stable Diffusion GRisk GUIが起動しました。私は初回に2回ほどなんか起動に失敗したのですが、以降は安定しています。
Text Input(プロンプトの入力、改行入力で複数画像同時生成)
Output Folder(保存フォルダ選択)
steps(画像の品質)
Vscale(どの程度AIに言う事を聞かせるか)
Smaples per prompt(わからん)
Seed(シード値)
Resolution(横縦の解像度。64の倍数が基準。"256、512、640"とかは64の倍数なのでOKですが"200、500、600"とかは無理です)
■とりあえず何か生成してみよう
まずは適当に「Video footage of A man walking on the street.」とでも入力して生成してみましょう。設定は解像度512*512のstep数50。入力できたらRenderをクリック。
起動後の初回生成時だけはモデルのロードが必要なのでちょっとかかります。以降はロード不要。

モデルのロード完了後に画像の生成開始。14秒で1枚の画像が出力されました。2060Sじゃどうなのかなと思ってたけど…、思ったより早いな?グラボも特にウォンウォン唸ったりはしてないです。生成した画像はデフォルトではresultsフォルダに入っています。

いいですね!ちゃんとローカルPCでSDの画像生成を行うことができました!
ちなみにテキスト欄に改行入力することで一度に複数枚の画像を生成してくれます。
a man walking street.
a man walking street.
a man walking street.
とかにすると歩いてる男の画像が3枚生成されますね。
■seed値の設定
Seed値を任意設定して"似たような画像"を生成する機能ですが、前回DreamStudioを解説した時にはできませんでしたが、このアプリケーションではできますので試してみましょう。
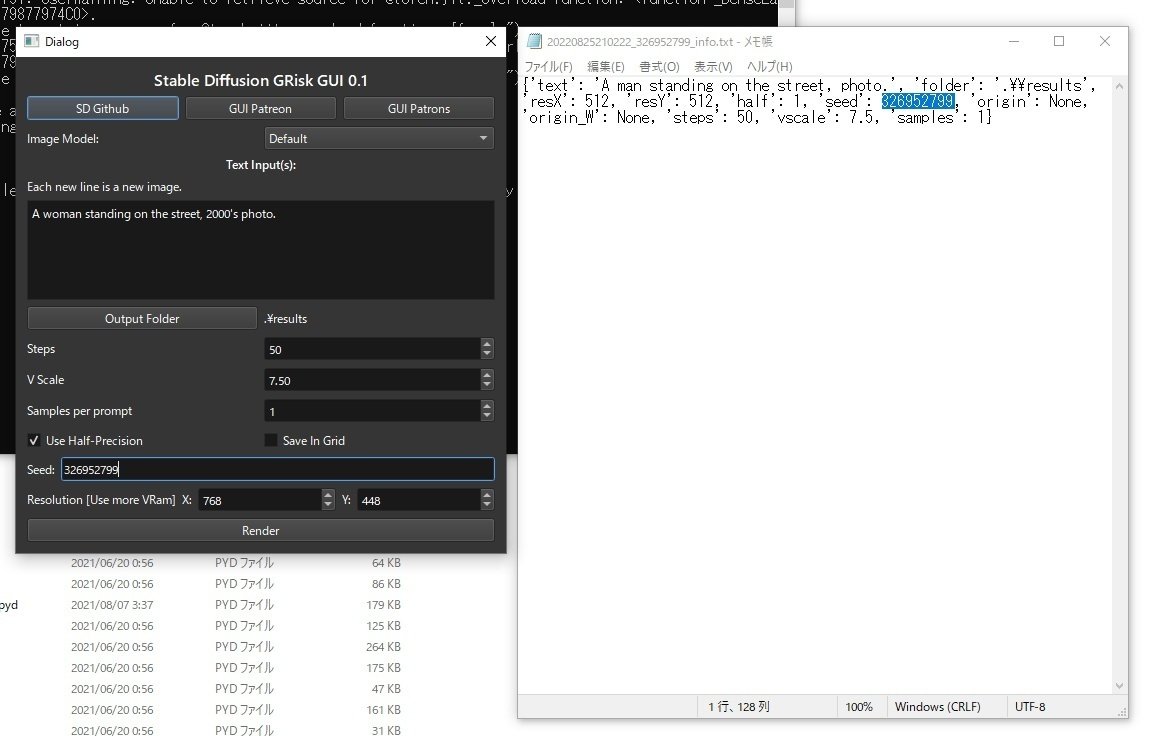
画像生成時にテキストファイルが同時生成され、そこにseed値が記載されていますので、シード値をコピペしつつプロンプトを「Video footage of A woman walking on the street.」に変更します。これで似たような絵面のまま、男性が女性になっている筈ですが…。

おー、上手くいきました。seed値の固定は気に入った構図を使いまわしたい時に役に立つと思います。
■解像度の変更

解像度は64の倍数で設定可能です。ただ高解像度の画像を生成する場合は大容量のVRAMが必要になります。私の2060S(VRAM8GB)では640*512の解像度が限界で、それ以上ではエラーが出ます。やはりネックはGPUの処理性能よりもVRAM容量なんですかね。どうしても横長画像を生成したい場合は、縦ピクセルを縮めて768*448とかにするしかないです。
■規制フィルターは無し
かつて行われていたDiscordβに始まり、DreamStudioやその他のデモ公開サイトで猛威を振るっているポンコツ規制フィルターですが。このアプリ版ではOFFにされています。web版では健全画像がフィルターの謎判定でぼかされてしまうことも少なくないのでありがたいですね!

■オンラインサービスに課金する必要無いんじゃね…?
このアプリ版はもちろん計算処理を自前のGPUで行っていますので、電気代以外にお金はかかりません。SD自体がオープンソースAIだからこそ、このような高度な画像AIアプリが無料で配布できる訳ですね。しかしそうなると現在あるDreamStudioや、後に続くと思われるNovelAIやNightcafeの画像サービスに月額課金する意味ってありますかね…?
確かに1024*1024のような高解像度画像の生成は、オンラインサービスを通じて強いサーバーで処理してもらわないと生成できませんし、一般向けGPUでは計算処理に時間もかかります。私の2060Sに生成可能な最大解像度640*512というのも、イラスト用途では心もとないものです。でも良い感じのグラボ持っててカジュアル用途でしか画像生成しない人は、別にオンラインサービスに課金する必要もないんじゃないでしょうか?
「AI画像生成でイラストレータ―死ぬんじゃね問題」よりも、「オープンソースAIだからマネタイズできなくてAI画像生成サービス死ぬんじゃね問題」の方が気になるぜ。
■img2imgについて
最後に、このStable Diffusion GRisk GUIはテキストから画像を生成するお馴染みの「text to image」方式ですが、SDは画像から画像を生成する「image to image」方式の生成が可能です。

このように画像をベースに生成させるので、構図やポーズや大まかな色味の
イメージが決まっている場合は、テキストから何度も画像生成ガチャするよりも遥かに優れたアプローチと言えます。
アプリ製作者の方がこのimg2imgの話に触れていましたので、Stable Diffusion GRisk GUIもその内img2img方式を実装するかも…。今後のアップデートから目が離せませんね!
あと私はAI画像生成関連の最新情報はredditのSDコミュニティで見てますので、最新情報を一早く知りたい人はどーぞ。
https://www.reddit.com/r/StableDiffusion/
あと関係ないけどAI生成画像をベースに漫画描いたんでお暇な人はどーぞ。
Princess of the dark demoniac evil swamp (1/8) #stablediffusion #dreamstudio pic.twitter.com/TlkjkF6dCx
— あぶぶ@健全 (@abubu_newnanka) August 23, 2022
この記事が気に入ったらサポートをしてみませんか?