
Kindleの読書時間データを取得・解析!

はじめに
こちらの記事でAmazonの自分の利用データをエクスポートできることを紹介しました。
その中でもKindleの読書に関するデータについて紹介します。今回Pythonで集計・可視化しますが、使うのはcsvファイルなのでエクセルでも同じようなことができると思います。
利用するデータ
先述の記事の手順に従って次のデータカテゴリをエクスポートします。
注文
Kindle
その中でも、こちらの二つのcsvを使って読書時間を見ていきます。
Kindle/Kindle.Devices.ReadingSession/Kindle.Devices.ReadingSession.csv
セッション(おそらく書籍を開いてから閉じるまで)ごとの情報。
ASIN(Amazonの商品ID)や開始終了日時などが含まれる。
Your Orders/Digital-Ordering.3/Digital Items.csv
注文したデジタル商品に関する情報。今回はASINからタイトルを取得するために利用。
Kindle.Devices.ReadingSession.csvの列情報は次の通りです。特に公式な説明は見当たらなかったので、データを見て解釈した形になります。

csvの読み込み
import pandas as pd
# 読書情報
path_rs_ver1 = "Kindle/Kindle.Devices.ReadingSession/Kindle.Devices.ReadingSession.csv"
df_rs = pd.read_csv(path_rs_ver1)
# datetime型に変換
df_rs["start_timestamp"] = pd.to_datetime(df_rs["start_timestamp"].replace("Not Available",np.nan))
df_rs["end_timestamp"] = pd.to_datetime(df_rs["end_timestamp"].replace("Not Available",np.nan))
# 注文した書籍情報(今回はASINからタイトルがわかるようにするために利用)
path_d_ordert = "Your Orders/Digital-Ordering.3/Digital Items.csv"
df_d_item = pd.read_csv(path_d_ordert ) # 書籍情報など(音楽などもある)
# 読書情報に書籍
df_rs_info = pd.merge(
df_rs,
df_d_item[["ASIN","Title"]].drop_duplicates(),
on='ASIN',
how='left'
)読書情報と商品情報をASINをキーに結合して、各行に商品タイトルを付与します。

解析例1:めくったページ数と時間
時間とめくったページの関係を見てみます。いろいろな本が一緒くたになっていたり、精読したり流し見したりするのでかなりばらつきがでますが、ある程度自分の読むペースがわかりそうです。
おそらくKindleアプリで表示される本を読み終えるまでの想定時間はこのデータを使って算出しているのかなと思います。
px.scatter(df_rs_info,x='total_reading_millis',y='number_of_page_flips')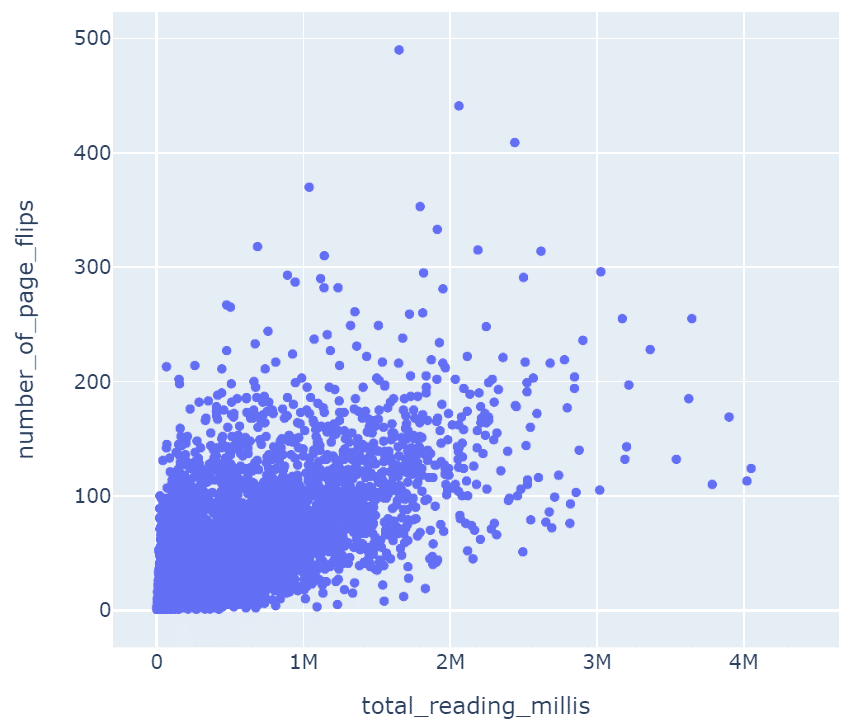
解析例2:読書時間の推移
月ごとに読書時間を集計してみました。
monthly_reading_time = (
df_rs_info
.groupby(pd.Grouper(key="start_timestamp",freq='MS'))["total_reading_millis"]
.sum()
.div(1000*60*60) # ミリ秒を時間に変換
.rename("total_reading_hours")
.reset_index()
)px.line(monthly_reading_time,x='start_timestamp',y='total_reading_hours')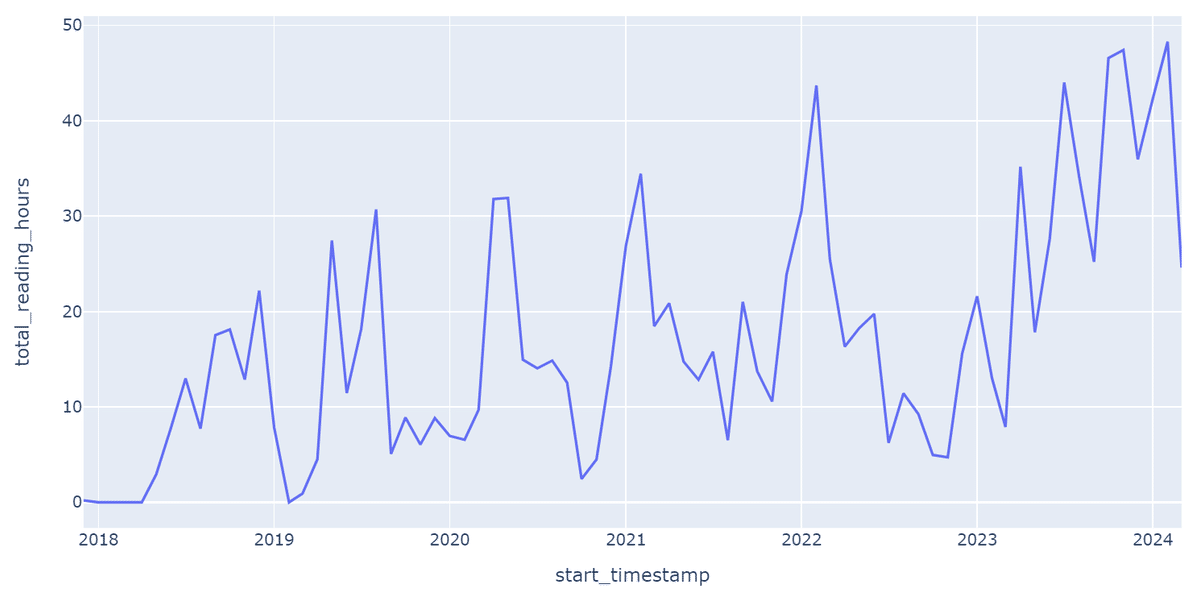
2023年までは年明け直後が読書時間長く、2023年以降は徐々に読書時間が年末にかけて多くなっています。2023年から電車通勤始めてその時間に読むことが多くなったからだと思います。
読書習慣をつけたい人にとって良いモチベーションになるのではないでしょうか。
解析例3:書籍ごとの読書時間
reading_time_per_book = (
df_rs_info
.groupby(["ASIN","Title"])["total_reading_millis"]
.sum()
.div(1000*60) # ミリ秒を分に変換
.rename("total_reading_minutes")
.reset_index()
)
ASINごとに集計すれば、各書籍の合計読書時間を知ることができます。
読書時間でソートして、最も長い時間読んだ本ランキングなど見てみると面白いと思います。
おわりに
次の情報を使えば、より詳細に分析できます。
Your Orders\Digital.Borrows.3/Digital.Borrows.3.csv
内容:Kindle Unlimitedで借りた書籍の情報
用途例:購入した書籍だけでなく借りた書籍のタイトルもわかるようになる。
Kindle/Kindle.SagaSeriesInfra/datasets/Kindle.SagaSeriesInfra.CollectionRightsDatastore/Kindle.SagaSeriesInfra.CollectionRightsDatastore.csv
内容:マンガシリーズのASINと各単行本のASINの対応関係がわかる
用途例:マンガシリーズごとに集計したり、マンガとマンガ以外を分けて集計したりできる。
このほかにもKindleの操作履歴に関する様々な情報がエクスポートできるので、今後紹介していければと思います。
この記事が気に入ったらサポートをしてみませんか?