
CogVideoXで遊ぶメモ

このメモを読むと
・CogVideoXを導入できる
・ローカルで動画生成AIを試せる
検証環境
・OS : Ubuntu 22.04(WSL on Windows11)
・Mem : 64GB
・GPU : GeForce RTX™ 4090
・ローカル(docker+venv)
・python 3.10.12
・2024/8/E時点
CogVideoX
ローカルでテキストから動画を生成することができるAIモデル。
自然言語を入力として、それっぽい動画を生成することが可能です。
試してみましょう!
事前準備
Linux環境が必要なので、WSLとDockerを活用してお手軽に構築します。
Gitを使うメモ | おれっち
DドライブにUbuntuを入れるメモ | おれっち
UbuntuにDockerを入れるメモ | おれっち
DockerでGPUを使うメモ
環境構築
とても簡単です!
作業環境はWSL上のUbuntuです。
1. Docerfileとdocker-compose.ymlを作成します。
Dockerfile
FROM nvidia/cuda:12.3.1-devel-ubuntu22.04
RUN ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtime
RUN apt -y update && apt -y upgrade
RUN apt -y install python3 python3-pip python3-venv python3-tk git libopencv-dev wget
RUN apt -y update && apt -y upgrade
RUN ln -s /usr/bin/python3.10 /usr/bin/python
RUN pip install --upgrade pip
WORKDIR /appdocker-compose.yml
services:
app:
build: .
tty: true
stdin_open: true
volumes:
- ./:/app
- /tmp/.X11-unix:/tmp/.X11-unix
shm_size: 8g
runtime: nvidia
environment:
- NVIDIA_VISIBLE_DEVICES=all
- NVIDIA_DRIVER_CAPABILITIES=all
- DISPLAY=${DISPLAY}
ports:
- "8888:8888" 
好きなディレクトリ ( 例: DevWS/cuda )
├── Dockerfile
└── docker-compose.yml
2. Dockerコンテナを立ち上げcuda環境を構築
cd ~/DevWS/cuda
docker compose up -d
docker compose exec app bash3. リポジトリをインストールし、ディレクトリ移動
git clone https://github.com/THUDM/CogVideo.git
cd CogVideo4. 仮想環境を作成し、環境を切り替え
python -m venv .venv
source .venv/bin/activate5. 依存パッケージのインストール
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu124
pip install -r requirements.txt完了です!
CogVideoを動かしてみる
テキストからビデオを生成してみましょう。
スクリプトを用意
下記スクリプトを、/CogVideo 直下へ保存します。
def parameters() のパラメータをお好みに変更します。
# run.py
import os
import torch
from diffusers import CogVideoXPipeline, CogVideoXDDIMScheduler, CogVideoXDPMScheduler
from diffusers.utils import export_to_video
def parameters(): ### ここをイジる
model_choice = "5b" ## "2b"か"5b"を選ぶ
output_path = "./result/output.mp4" ## 出力先パス
prompt = """A photorealistic portrait of a wolf, sporting sleek black sunglasses,
with its lengthy fur flowing in the breeze, sprints playfully across a rooftop terrace,
recently refreshed by a light rain.
The scene unfolds from a distance, the wolf energetic bounds growing larger as it approaches the camera,
its tail wagging with unrestrained joy, while droplets of water glisten on the concrete behind it.
The overcast sky provides a dramatic backdrop, emphasizing the vibrant white coat of the canine as it dashes towards the viewer."""
return prompt, model_choice, output_path
def generate_video(prompt, model_choice, output_path, num_inference_steps=50, guidance_scale=6.0, num_videos_per_prompt=1, dtype: torch.dtype = torch.bfloat16 ):
os.makedirs(os.path.dirname(output_path), exist_ok=True)
model_path = "THUDM/CogVideoX-2b" if model_choice == "2b" else "THUDM/CogVideoX-5b"
pipe = CogVideoXPipeline.from_pretrained(model_path, torch_dtype=dtype)
if model_choice == "2b":
pipe.scheduler = CogVideoXDDIMScheduler.from_config(pipe.scheduler.config, timestep_spacing="trailing")
else:
pipe.scheduler = CogVideoXDPMScheduler.from_config(pipe.scheduler.config, timestep_spacing="trailing")
pipe.enable_model_cpu_offload()
pipe.vae.enable_tiling()
seed = torch.Generator().seed()
video = pipe(
prompt=prompt,
num_videos_per_prompt=num_videos_per_prompt,
num_inference_steps=num_inference_steps,
num_frames=49, # Number of frames to generate.
use_dynamic_cfg=(model_choice == "5b"), # Dynamic CFG for DPM scheduler
guidance_scale=guidance_scale,
generator=torch.Generator().manual_seed(seed)
).frames[0]
export_to_video(video, output_path, fps=8)
print(f"seed: {seed}")
print(f"Video generated and saved to {output_path}.")
return
if __name__ == "__main__":
generate_video(*parameters())実行
用意したスクリプトを実行します。
python run.py結果
指定したパス へ結果が出力されます。
CogVideoX-5b pic.twitter.com/I4xOxD2g61
— おれっち (@__olender) August 29, 2024
おまけ
CogVideoX-2b
かかった時間 1分28秒
消費VRAM 13GBくらい
CogVideoX-5b
かかった時間 4分21秒
消費VRAM 19GBくらい
おまけ2
こんなエラーが出たら
OSError: [WinError 126] 指定されたモジュールが見つかりません。 Error loading "C:\Users\owner\AppData\Local\Temp\pip-build-env-4mypfhm_\overlay\Lib\site-packages\torch\lib\fbgemm.dll" or one of its dependencies.
1. こちらから libomp140.x86_64_x86-64.zip をDLし解凍
2. C:\Windows\System32 へ libomp140.x86_64.dll を格納
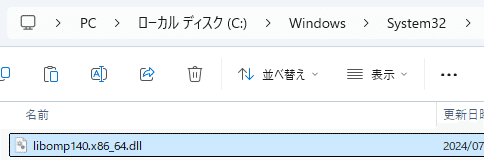
これでエラーがなくなります。
おわり
テキストから動画を生成できた。
2bモデルはApache2.0ライセンス、5bは独自のライセンスです。
Soraの衝撃から はや半年、ついにローカルで動画生成ができるようになってしまいました。
ControlNetやi2vの適用も時間の問題でしょうか。今後の進展が楽しみです。
おしょうしな
参考にさせていただきました。ありがとうございました。