
Pythonで機械学習『Iowa 家の販売価格予測 with PyCaret』002/100

先日勉強したPyCaretでIowa HousePriceチャレンジ。
欠損処理したcsvがあるのでやってみる。
PyCaretは簡単だけど、待ち時間が長いなー。
前処理

モデルの比較

RMSLEって、IOWAの評価指標と同じだよね?
だとすると、Pycaretデフォルトだと、前やったLightGBMのチューニング前(ベースラインのパラメーター)の方がスコアいい。
原因は、
PyCaretだと、fold数は10になってることと、パラメータが、
LGBMRegressor(boosting_type='gbdt', class_weight=None, colsample_bytree=1.0,
importance_type='split', learning_rate=0.1, max_depth=-1,
min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0,
n_estimators=100, n_jobs=-1, num_leaves=31, objective=None,
random_state=777, reg_alpha=0.0, reg_lambda=0.0, silent='warn',
subsample=1.0, subsample_for_bin=200000, subsample_freq=0)であることかな。
Pycaretで自動チューニングをしてみると、パラメータはこんな感じに。

Lightgbmのベースラインのパラメータは
lgbm_params = {
'learning_rate' : 0.1,
'num_leaves' : 31,
'max_depth' : 5,
'min_data_in_leaf' : 20,
'min_sum_hessian_in_leaf' : 1.0,
'bagging_fraction' : 0.8,
'bagging_freq' : 5,
'feature_fraction' : 0.8,
'lambda_l1' : 0,
'lambda_l2' : 1.0,
'max_bin' : 255
}にしてる。
念の為Kaggleに投稿してみても、スコアは、0.143

fold数が原因かと思い、fold数4にしてやってみたけど、決定係数もRSMLEも少し下がった。うー、変な特徴量を生成しているのかな。
納得感はないが、次に進もう。
なぜならSHAPというものが気になっているので。
SHAPとは、XAI(説明可能なAI)ライブラリの一つで、機械学習モデルを説明するためのもの。元々のアルゴリズムは前からあるらしいんだけど、Pythonライブラリになったのはここ数年みたい。この動画で知った。
!pip install shap
した後に、
interpret_model()
すると、

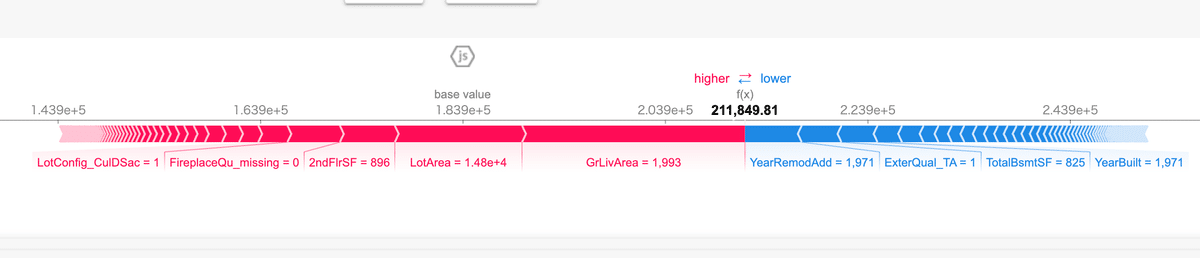
こんな図が出力できる。
Iowaの例で言うと、
GrLivArea(地上の居住面積)が広ければ価格が高い、狭ければ安い。と言うことがわかる。しかも数値付きで。すごーいね。
ちなみに、pycaretでは決定木ベースのアルゴリズムの場合のみ、これができるみたい。
と言うわけで、Pycaret触ってみた。
初手としてガンガン使えそう。
この記事が気に入ったらサポートをしてみませんか?