Pythonで機械学習『家の販売価格予測』002/100

Iowa家価格予測 その2。
column03
LotFrontage:物件の、道路に面した「辺」の長さ(単位feet (1feetは大体0.3m))
欠損値が登場、259行のデータで欠損。

ヒストグラムは、

一部の外れ値を除けば、正規分布っぽい。
一般的に、道路に面した辺の長さが長ければ長いほど敷地は広くなりがちであろう、つまり価格もあがるであろう、ということで、相関みてみる。

0.35か。ゾーニングをRL(混み合っていないゾーン)にかぎってみるとどうか。
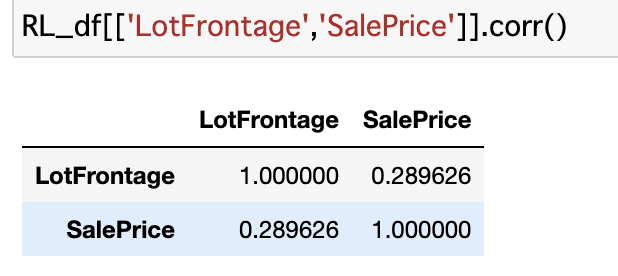
あれ、下がった。
今思ったけど一個づつ地味に見ていくより、まず全体把握したほうがいいのでは。とりあえず一回LightGBMでやってみて、再度詳しいデータ確認へと戻ってくるほうが効率よさそう。
流れを整理すると、
1、全体の欠損値を確認する。
2、全体のデータタイプを見てみる。(量的なのか質的なのか)
3、量的なデータは相関係数を見てみる。
4、質的なデータは、数値データに変換する。
5、データを分割してLightGBMでモデルを作って、予測する
6、予測スコアをみて、改善する。
なイメージかな・・・。
でも6の改善するためにどんなことをすればいいんだろ。
結局1〜3のEDAと、4、5のLightgbmの使い方は、6のためのステップですよね。
なるほど、じゃあLightGBMの精度を改善する方法を調べるのが先決だ!
LightGBM編 スタート
LightGBMの予測の精度を上げる方法は2つ。
1、パラメータ(機械学習手法の挙動を制御する)を良くする。
2、データを良くする(特徴選択、特徴量エンジニアリングと呼ばれる)か。
パラメータの調整による精度向上はあまり大きくないと言われる。が、パラメーターがおかしいと過学習になりやすい。
特徴選択がとても大事。上記の流れ、1〜4はこの「特徴選択」のことだった。なるほど。
パラメータは色々あるが、重要っぽいもの(よく聞く)を抜き出してみた。
objective
boosting
num_iteration
learning_rate
n_estimators
num_leaves
bagging_fraction
bagging_freq
feature_fraction
seed
min_data_in_leaf
min_sum_hessian_in_leaf
early_stopping_round
verbosity
max_bin
reg_alpha
reg_lambda
metric
パラメータをどういじればいいかを検証するために、グリッドサーチやランダムサーチ、ベイズ最適化(を利用したOptunaというライブラリ。自動でやってくれる。)といった方法があるようです。Optunaが簡単で良く使われるみたい。今度やってみよう。
データが有益か無益化を測る方法は、フィルタ法、ラッパー法、組み込み法などがある。LightGBMでは2種類の「重要度」を測ることができる。
・頻度(split): モデルでその特徴量が使用された回数。決定木の分岐を使用した数を計算する
・ゲイン(gain): その特徴量が使用する分岐からの目的関数の減少
で判断できる。
パラメータに関しては、一通りの意味を理解したいので、1記事分調べてまとめる。パラメータの意味とoptuna実装までやる。
その次に、特徴選択について、集中して調べることにする。
この記事が気に入ったらサポートをしてみませんか?