
AIを使って「似たようなプロダクト要望」の検索機能を実装してみる

背景
顧客要望が多すぎて、サマって分析するのが結構大変。「あれ、こういった要望って前にも聞いたけど、どこだっけ?」ということ、PMならよくありませんか?キーワードで検索してみるけど、お客様やその要望を共有した社内メンバーによって言葉遣いが違うケースもあり、なかなか見当たらないというのも結構あるあるです。
そこで、今回は「AIを使って文章の類似検索やってみようぜ」という話になります。

機械学習でいうと、どういった問題か?
これは自然言語処理で頻出するテーマで、「類似文章検索」(Sentence Similarity、Semantic Textual Similarity)と呼ばれています。
メチャクチャ簡単に言うと、文章(sentence)を何次元かのベクトル空間に埋め込む(embeddingする)タスクで、その際に意味が似た2つの文章はこの空間内で近い位置に、そうじゃない場合は遠い位置に埋め込まれるようにすることが肝です。
Embeddingさえしてしまえば、あとは2つのベクトルの類似度を計算するのみなので、コサイン類似度(Cosine similarity)やドット積(dot product)などで、ある文章に類似した文章を検索することができます。
モデルを探す
今回使うのはChatGPTでもOpenAIのAPIでもありません。オープンソースAIモデルのプラットフォームであるHugging Faceから、適切なモデルを探してみます。
ご存知ない方も多いので簡単に説明すると、Hugging Faceとは「AI・機械学習に特化したGitHub」です。ここでは最先端のオープンソースAIモデルが公開されており、ダウンロードしてローカルで使うもよし、マネージドされたAPIとして使うもよしという、非常に便利なサービスです。
https://huggingface.co/models にいくと、アップロードされているすべてのモデルが一覧で検索できます。今回は「sentence similarity」なので、そのタグで検索してみると、たくさんのモデルがヒットしました。
"all-MiniLM-L6-v2"なるモデルが、スター数も多く良さげです。

Googleで検索してみると、どうやら"Sentence-Transformers"ライブラリの中にあるモデルの一つみたいですね。

(ちなみに、sbertというのは、Googleが開発したあのBERTをベースしたモデル、Sentence BERTの略です。GPT同様、Transformerをベースに作られてますね)
このライブラリで使えるモデルを比較してみると、今回Hugging Faceで一番上にヒットしたall-MiniLM-L6-v2は、名前の通り高性能かつモデルサイズが小さいのが特徴のようです。ただ、今回はモデルサイズに特に制約がなかったため、一番性能が高そうな"all-mpnet-base-v2"を選ぶことにしました。
実装する
今回はAPI等ではなく、自前のPython環境で使ってみることにしました。
また、下記の観点から、環境はGoogle Colab*を選びました。
*Google Colabとは、Googleが無料で提供するjupyter notebook環境です
Python環境であること
データ管理しているGoogle Spreadsheetからの読み込みが簡単であること
無料であり、かつフルマネージドな環境であること(楽なので)
Google spreadsheetをColabと連携する
この部分は簡単で、以下で終わりです。やっていることはシンプルで、
1. Google Spreadsheetと認証する
2. URLで指定したスプレッドシート及びシートを開く
3. シートを2次元配列として読み込む
4. 最初の列(index: 0)の全てのセルを配列として読み込む
これで終わりです。

なお、シートの中身はこんな感じ。もともと英語用のモデルなので、入力は英文にすべく、翻訳したA列を使っています。

SentenceTransformersを使う
手順としては、下記2点です
1. sentence-transformersライブラリをインストール・読み込む
2. Spreadsheetから読み取った文章を全てembeddingする

はい。これで、前処理が完了しました。あとは、「これと似た要望ってある?」を調べたい文章を渡して、コサイン類似度が高い文章を検索してあげるだけです。つまり、
1. 調べたい文章Xをembeddingする
2. embeddingした各文章と、文章Xのコサイン類似度を計算する
3. コサイン類似度が一定値を超える文章を返す(この例では0.45にしています)

結果
とすると、結構いい感じに動いてくれました。今回は「メンバーページの項目をカスタマイズしたい」という内容で検索してみたところ、下記の要望一覧が類似要望として返ってきました。
I want to be able to add items to the User Profiles(メンバーページの項目を追加したい)
I want to be able to customize items in User Profiles(メンバーページの項目をカスタマイズしたい)
I want custom items in User Profiles(メンバーページでカスタム項目がほしい)
Add 'Intern' as a Member Type(メンバー種類に「インターン」を追加してほしい)
Sort Member List by Department(メンバー一覧を所属部署でソートしたい)
Custom Fields in 'Member Information(メンバー情報にカスタム属性がほしい)
It would be good if member items could be customized(メンバー項目がカスタマイズできたら嬉しい)
I want to register managing departments as column for apps(アプリ項目として管理部署を登録したい)
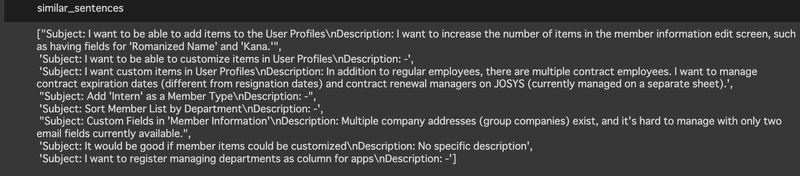
一部、似て非なるものも混じっていますが、とはいえ結構いい感じに出してくれてませんか??
めちゃくちゃ急ピッチで検証してみましたが、オープンソースモデルをそのまま使ってもわりといい感じになることが分かりました。このように、AIはどんどん使って、プロダクトマネージャーのOps業務を効率化していきたいですね。
この記事が気に入ったらサポートをしてみませんか?