
新型コロナのデータサイエンス記事の紹介

新型コロナをデータサイエンスの視点からとらえたブログ記事をいくつかっ紹介したいと思います。
各国の新型コロナウイルス感染状況を公開データを使って分析・予測する
【シミュレーション入門】コロナ感染をシミュレートして遊んでみた♬
新型コロナは本当に脅威か? Stan で検証した (かった)
どれも素晴らしい記事だと思いますので、お時間のある方は読んでいただければと思います。
「各国の新型コロナウイルス感染状況を公開データを使って分析・予測する」 について
一番最初に紹介させていただいた「各国の新型コロナウイルス感染状況を公開データを使って分析・予測する」のなかではロジスティック曲線のコードなどの記述がありましたので、Google Colaboratryでのコードも紹介させていただきます。
ロジスティック曲線(関数)とは以下のウィキペディアにも出ていますが、環境収容力に関する数理モデルです。
プログラム界隈では発生するバグの出現曲線であるとか、
都市における人口の増加というようなものに対して、
予測として使われます。
バグや人口というものは最初の段階では指数関数的に増加しますが、ある時点からブレーキがかかり、どこかで一定のところに飽和するという考え方です。
同じ考え方で病気の感染者数もこの関数を利用して、予測ができるのではないかという考え方がベースにあります。
実際の考え方は複雑なのですが、ここでは、まずはPythonを使ってどのようなことができるか確認してみたいと思います。
記事内では以下のようなコードが紹介されています。
import numpy as np
import matplotlib.pyplot as plt
k = 1; L = 1; x0 = 7.5
x = np.arange(0,15,0.01)
y = [L / (1 + np.exp(-k*(x-x0))) for x in x]
slope, intercept, r_value, p_value, std_err = scipy.stats.linregress(x[0:500],np.log(y[0:500]))
fit_y = [np.exp(slope*d+intercept) for d in x[0:800]]
fit_x = x[0:800]
fig,axes=plt.subplots(1,2,figsize=(12,4))
axes[0].plot(x, y)
axes[0].set_title('Logistic function (linear plot)')
axes[0].set_xlabel('X')
axes[0].set_ylabel('Y')
axes[1].plot(x, np.log(y))
axes[1].plot(fit_x, np.log(fit_y))
axes[1].set_title('Logistic function (lin-log plot)')
axes[1].set_xlabel('X')
axes[1].set_ylabel('log(Y)')
plt.legend(['Logistic', 'Logistic fit'])
plt.savefig('logistic.png', dpi=400, bbox_inches='tight')ただ、このコードを単純にGoogle Colarboratyに入れただけだど以下のようなエラーメッセージでます。
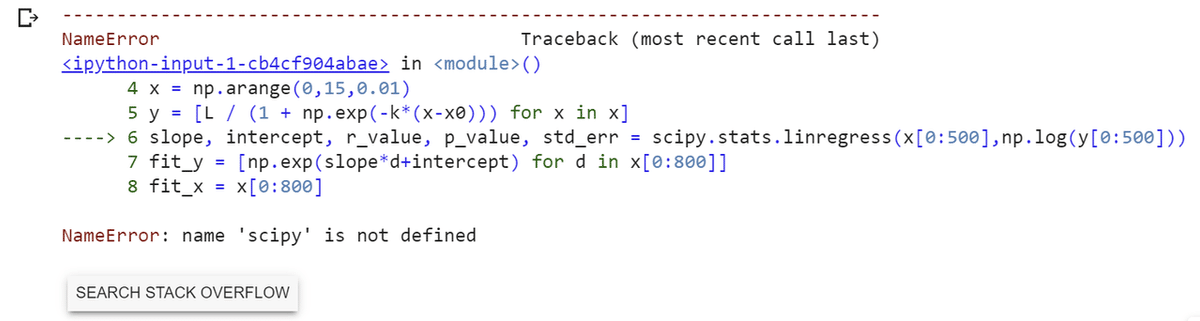
ですので、一番手っ取り早く動かすには以下の
import scipy
import seaborn as snsを入れてあげてから実行してあげると実は動きます。

感染者数などは指数関数的に増えるが、あるところで増加率は下がり、ある一定の値に収束するであろうという考えです。
この記事でも書かれていますが、今の我々の関心事は
「いつ、終息(収束)するのか」
だと思います。病理学的な視点や、集団心理学なども本来であれば必要だと思いますが、手元にあるデータで出来る限りのことをする、、というのがデータサイエンティストの宿命です。
海外の事例も紹介されていますが、今回は日本に特化して、確認してみましょう。記事でも紹介されていますが、
都道府県別新型コロナウイルス感染者数マップ(ジャッグジャパン株式会社提供)https://gis.jag-japan.com/covid19jp/
のデータを使わせていただきます。このサイトは以下のようになっており、左上に利用できるCSVファイルをダウンロードできるようになっています。

上記CSVファイルをクリックするとデータがダウンロードされますので、それをGoogle Colaboratoryで読み込むことにします。
ウィンドウの左側になるフォルダーアイコンをクリックして、その中にあるアップロードの部分をクリックします。

今回ダウンロードしたファイルを指定したのち、読み込みを確認するものにokボタンを押すとファイルが中にクラウドサイドにアップロードされPythonから利用できるようになります。

この段階で、記事のコードを実行します。
country = 'Japan'
period = 7
# Data obtained from
# https://gis.jag-japan.com/covid19jp/?fbclid=IwAR30DDBBnQRcXnIOoqJmjbs-Z4kYIS0LvHMBqwBbORWRV3TpjYstvrrBrE4
japan_df = pd.read_csv('COVID-19.csv')
tmp = japan_df[['確定日','死者合計']].dropna()
y = japan_df['死者合計'].dropna().values[14:]# count from Feb 13
ylog = np.log(y)
days = len(y)
x = np.arange(0,days) #plt .plot(x,y) #plt .plot(x,ylog,'o-')
slope, intercept, r_value, p_value, std_err = scipy.stats.linregress(x,ylog)
doubling = np.log(2)/slope
print(f'{country}: doubling {doubling:.2} days / R^2: {r_value**2:.2}')
fit_y = [np.exp(slope*d+intercept) for d in range(0,days+period)]
fit_x = np.arange(len(fit_y)) #corona_df [f'{country}_fit'] = fit_y + [np.nan]*(len(corona_df)-len(corona_df[country].dropna()))
fig,axes=plt.subplots(1,2, figsize=(12,4))
axes[0].plot(x,np.log(y),'.-')
axes[0].plot(fit_x,np.log(fit_y),'.-')
axes[0].set_title(country)
axes[0].set_xlabel('Days since the first confirmed death')
axes[0].set_ylabel('log(death toll)')
axes[1].plot(x,y,'.-')
axes[1].plot(fit_x,fit_y,'.-')
axes[1].set_title(country)
axes[1].set_xlabel('Days since the first confirmed death')
axes[1].set_ylabel('Death toll (linear)')
plt.legend(['Actual', 'Fit'])
plt.savefig('Japan_fitting_withprediction.png', dpi=400)残念ながらこの状態でも少し問題が生じる可能性があります。

ですので、今回もとりあえず動かすには以下のコードが必要です。
import pandas as pd

データをもとに自分なりの考えをモデルとして表現できると思います。
記事の筆者も書かれていらっしゃいますが、「ツールとして利用していただき」、「いたずらに不安を煽らず」、「備えるために必要な情報」としていただければと思います。
【シミュレーション入門】コロナ感染をシミュレートして遊んでみた♬
記事中にシミュレーションのアニメもありますので、そちらを参考にしていただければと思いますが、
人が集まらず、手洗いやマスクなどをうまく使って感染率を一定以下(今回のシミュレーションだと3%以下)に下げられればそれだけで感染伝播を発生させないことも可能
という可能性も示唆されています。これに関しては以下の記事も参考になると思います。
日本のメディアもこう言う記事を書いて欲しい
— analysetf (@AnalyseTf) March 15, 2020
感染者と回復者をシミュレーションしてピーク値をいかに下げるかを考える
Why outbreaks like coronavirus spread exponentially, and how to “flatten the curve” - Washington Post https://t.co/qzblTFh1dP
コロナウイルスなどのアウトブレイクは、なぜ急速に拡大し、どのように「曲線を平らにする」ことができるのか
https://www.washingtonpost.com/graphics/2020/health/corona-simulation-japanese/
新型コロナは本当に脅威か? Stan で検証した (かった)
ダイヤモンド・プリンセス号のデータを利用しながら pystan を利用しての分析です。
私はpystanに関しては詳しくないので、ここでは紹介にとどめさせていただきますが、pystanについて、いろいろ細かいことは以下のようなサイトに情報があるようです。
Pythonで「StanとRでベイズ統計モデリング」の4節をやってみた(PyStan)
統計モデリングで遊ぶ: StanとPythonでJリーグのチームの強さを数値化する
なかなか面白い内容です。興味ある方は読んでみてください。
また、なにか新しいことが出てきたら随時、追加してみたいと思っています。
--------------------------------------------------------------------------------------
2020/04/05
「日本は3週間前のアメリカ」という動画は本当なのか? という記事を書きました。
サポートしていただき大変ありがとうございます。 励みになります。