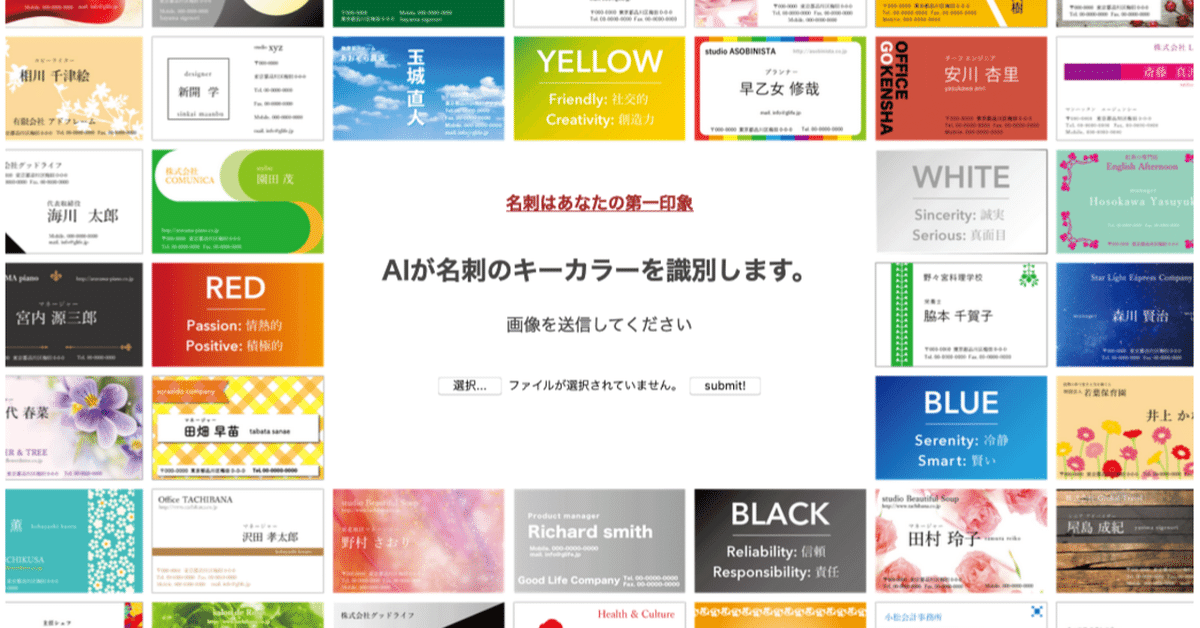
CNNで名刺のキーカラーを識別し、第一印象を答えるアプリの作成

はじめに
「AIはデザインを理解することが出来るのか?」
デザインの仕事をする傍らAIを学んでいた私は、そんなことを疑問に思い、
デザインの勉強としてよく作られる名刺を元に検証し、そのモデルを使ったWEBアプリを作成することにしました。デザインと言っても、色、形、バランス、書体など多くの要素が組み合わせっているので、今回はキーとなる色を認識するモデルを作成することにしました。

自己紹介:文系大学を卒業 → SEとして2年勤務 → デザイナーとして10年以上勤務 → JDLA E資格取得→アイデミー(AIプログラミングスクール)を受講
データ収集
まずは学習の元となる名刺画像の収集です。最近では世界中にAI学習のためのオープンデータセットが公開されていますが、あいにく名刺画像のデータセットはなかったため、WEB上の名刺作成サイトなどから集めました。
シンプルな会社員の方の名刺だけでなく、クリエイティブ職や飲食店の方の名刺のような、カラフルなものや特徴的な名刺も集めました。また縦型、横型両方のデータを集めました。分類モデルの精度を高めるためには、かなりの量の学習データが必要と言われているので、集めた画像をphotoshopで色を変えたりして、データ量を増やしました。

それから集めた名刺データをそれぞれ1グループ500枚の白、黒、青、赤、黄色&緑の5分類に分けました。
黄色と緑を一緒のグループにした理由は、黄色をキーカラーにした名刺の数が少ない事と、黄色と緑を使った名刺から感じる印象がどちらも「社交的で協調性がある」と思ったからです。こうした単なるCMYKといった色の数値ではなく、人間の感覚に近い分類機能も持たせることが出来るのかも、今回検証しようと思いました。
実行環境
今回検証するにあたって、無料でGPUが一定時間使用できる、google Colaboratory上で開発することにしました。分類した画像はgoogle driveに保存し、同じディレクトリ内でプログラムを作成しました。

シンプルなCNNでの検証
まずは基本的なCNNモデルを構築しました。CNNとは、画像認識タスクで一般的に使われるディープニューラルネットワークを用いた深層学習手法です。このCNNモデルに5つに分類した名刺画像を学習させ、的確にキーカラーを識別させるのが目標です。
ライブラリの読み込み
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPooling2D, Activation, BatchNormalization
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers学習データの読み込み
5つの分類データの保存パスをリスト形式にし、そこから画像データを読み込み、それぞれのデータリストを作成する関数を用意しました。あとは学習データ、検証データに分離しました。
five_path_list = ['/content/drive/MyDrive/Colab Notebooks/app_02/02_BLACK/',
'/content/drive/MyDrive/Colab Notebooks/app_02/02_BLUE/',
'/content/drive/MyDrive/Colab Notebooks/app_02/02_RED/',
'/content/drive/MyDrive/Colab Notebooks/app_02/02_WHITE/',
'/content/drive/MyDrive/Colab Notebooks/app_02/02_YELLOW/']
five_list = []
#データフォルダパスからデータリストを作成する関数
def data_input(data_path):
data_list = os.listdir(data_path)
img_list = []
for i in range(len(data_list)):
img = cv2.imread(data_path+ data_list[i])
img = cv2.resize(img, (50,50))
img_list.append(img)
return img_list
for i, path in enumerate(five_path_list):
five_list.append(data_input(path))
X = np.array(five_list[0] + five_list[1] + five_list[2] + five_list[3] + five_list[4])
y = np.array([0]*len(five_list[0]) + [1]*len(five_list[1]) + [2]*len(five_list[2]) + [3]*len(five_list[3]) + [4]*len(five_list[4]))
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# データの分割
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)モデルの構築:畳み込み層を2セットと全結合層を3セットに通すシンプルなモデルを作成しました。
#モデルの構築
model = Sequential()
model.add(Conv2D(input_shape=(50, 50, 3), filters=32, kernel_size=(2, 2), strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(BatchNormalization())
model.add(Conv2D(filters=32, kernel_size=(2, 2), strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(BatchNormalization())
model.add(Flatten())
model.add(Dense(256))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(25))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(5, activation='softmax'))モデルのコンパイル、学習
#モデルのコンパイル
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
#モデルの学習
history = model.fit(X_train, y_train, batch_size=20, epochs=20, verbose=1, validation_data=(X_test, y_test))精度の評価
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
plt.plot(history.history['accuracy'], label="acc", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_acc", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()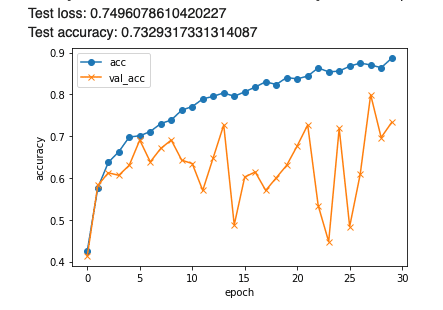
結果は検証正解率が70%を超えてはいるものの、その過程のグラフが不安定で、学習が進んでいるとは思えませんでした。この後、畳み込み層を増やしたり、epoch回数を増やしてみましたが、結果はそれほど変わりませんでした。ただし単純な色スペースの広さからいえば、ほとんど白に識別されるのではと心配していたのですが、今回のモデルは白地の中のキーカラーを識別し、分類しているようでした。

転移学習の導入
そこで今度は転移学習を行うことにしました。転移学習とは、すでに大量のデータを使ってある程度学習しているモデルをベースに、自分で層を追加して学習を行う方法です。今回はVGG16モデルを通した後、3つの全結合層を追加するモデルを構築しました。

新たにライブラリの読み込みを追加し、
先ほどのモデルの構築部分をVGGを使用するように差し替えます。
#ライブラリインポート箇所に追加
from tensorflow.keras.applications.vgg16 import VGG16# vgg16のインスタンスの生成
input_tensor = Input(shape=(50, 50, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
#モデルの構築
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256))
top_model.add(BatchNormalization())
top_model.add(Activation('relu'))
top_model.add(Dense(128))
top_model.add(BatchNormalization())
top_model.add(Activation('relu'))
top_model.add(Dense(25))
top_model.add(BatchNormalization())
top_model.add(Activation('relu'))
top_model.add(Dense(5, activation='softmax'))
# モデルの連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vgg16の重みの固定
for layer in model.layers[:16]:
layer.trainable = False
#モデルのコンパイル
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])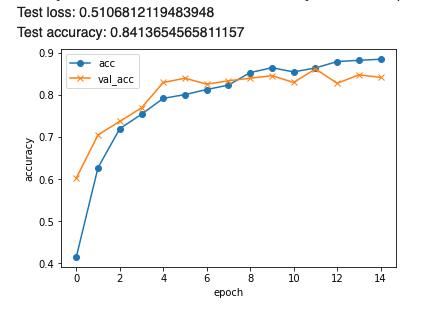
結果は検証正解率が80%を超え、グラフの上限も80%前後に推移するようになってきました。
今度は正しく識別できない画像がどういったものなのかを確認するため、名刺画像と予測結果を同時に表示するプログラムを用意し、精度を測りました。その結果、白と青の分類が著しく悪いことに気づきました。調べた結果、画像をモデルに読み込む際の画像サイズがが小さいため、色の情報が抜け落ち、白ベースに青をキーカラーとした名刺が白と誤認してしまっているためでした。

モデル作成時は大量のデータを使用するため、ある程度データを軽量化しますが、一方で大事な情報が抜け落ちる危険性もあるため、適切なデータサイズを見極めることが必要だと思いました。この現象を回避するため読み込み画像のサイズを100にした結果、少し正解率が上がりました。
#~~~~~~~
def data_input(data_path):
data_list = os.listdir(data_path)
img_list = []
for i in range(len(data_list)):
img = cv2.imread(data_path+ data_list[i])
img = cv2.resize(img, (100,100)) ###読み込み画像サイズを50から100に変更
img_list.append(img)
return img_list
#~~~~~~~
# vgg16のインスタンスの生成
input_tensor = Input(shape=(100, 100, 3)) ###読み込み画像サイズを50から100に変更
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
#~~~~~~~CNN以外のモデルでの検証
読み込みサイズを大きくすることにより正解率はあがったのですが、一方で畳み込み層を増やしたり、dropoutといった正解率を上げる方法をいくつか試したのですが、あまり大きな変化は見られませんでした。そこで今回の分類タスクに対してCNNが適しているのかを検証すべく、別のモデルでも検証してみることにしました。

試したモデルはサポートベクターマシン(SVC)、LinearSVC、ロジスティック回帰(LogisticRegression)、決定木、ランダムフォレスト、K近傍法の6モデルです。これらのモデルをまとめて、各種ハイパーパラメータを用意し、グリッドサーチにて検証しました。
# グリッドサーチ
model_param_set_grid = {
SVC(): {"kernel": ["linear", "poly", "rbf", "sigmoid"], "C": [10 ** i for i in range(-4, 4)], "decision_function_shape": ["ovr", "ovo"]},
LinearSVC():{"C": [10 ** i for i in range(-4, 4)], "multi_class":["ovr", "crammer_singer"]},
LogisticRegression():{"C": [10 ** i for i in range(-4, 4)], "multi_class":["ovr", "multinomial"]},
DecisionTreeClassifier():{'max_depth':[2, 3, 4, 5], 'min_samples_leaf':[2, 3, 4, 5], 'min_samples_split':[2, 3, 4, 5]},
RandomForestClassifier():{'max_depth':[2, 3, 4, 5], 'min_samples_leaf':[2, 3, 4, 5], 'min_samples_split':[2, 3, 4, 5]},
KNeighborsClassifier():{'n_neighbors':[2, 3, 4, 5], 'weights':["uniform", "distance"], 'algorithm':["ball_tree", "kd_tree", "brute", "auto"]}
}
max_score = 0
best_param = None
# グリッドサーチでパラメーターサーチ
for model, param in model_param_set_grid.items():
clf = GridSearchCV(model, param)
clf.fit(train_X, train_y)
pred_y = clf.predict(test_X)
score = f1_score(test_y, pred_y, average="micro")
if max_score < score:
max_score = score
best_model = model.__class__.__name__
best_param = clf.best_params_
print("学習モデル:{},\nパラメーター:{}".format(best_model, best_param))
# 最も成績のいいスコアを出力してください。
print("ベストスコア:",max_score)
その結果、決定木とランダムフォレストが正解率85%を超えてはいましたが、CNNモデルと大きく差はなかったので、引き続きCNNで進めることにしました。
学習データの再分類
CNNモデル自体にこれ以上精度を上げる方法を思いつかなかったので、次は学習データが正しく分類されているかを疑ってみることにしました。そうすると、大量のデータをその時の感覚で分類していたたため、似たようなオレンジ色の名刺画像でも、赤グループに分類していたり黄色グループに分類していたりまちまちになっていました。これではCNNモデルといえども、正しく分類することは出来ないと気づきました。

AIモデルの構築にとって、学習データの作成に一番時間がかかると聞いたことがありますが、まさに一番大事な工程を疎かにした結果が、CNNモデルの正解率にも反映されていると感じました。その後、時間をかけて名刺画像を再度分類したところ、正解率は90%を超えるようになりました。

おそらくこれ以上精度を上げるには、さらに多くの名刺画像を用意する必要があるだろうと思いました。
当初の「AIはデザインを理解することが出来るのか?」という疑問は、人間が分類した学習データを使えば、デザインの1要素であるキーカラーの識別はおおよそできるという結論になりました。
Flask形式に置き換え、Herokuへアプリをデプロイ
無事、名刺からキーカラーを識別するモデルが出来たので、Flask形式に置き換え、WEBアプリとして公開することにしました。Flaskとはpython用のWebアプリケーションフレームワークで、アプリを開発する際に必要な機能をまとめたパッケージです。またHerokuとは、WEBアプリを手軽に公開できる環境を提供しているサービスです。

事前準備として先ほど作成したプログラムに、以下の工程を追加して識別モデルをmodel.h5として書き出しておきます。
#モデルの保存
from google.colab import files
#resultsディレクトリを作成
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
#重みを保存
model.save(os.path.join(result_dir, 'model.h5'))
files.download( '/content/results/model.h5' ) 他にはpythonのバージョンを記したruntime.txt、読み込みライブラリを記したrequirements.txt、アプリ表面上のレイアウトとなるindex.html、デザイン要素をまとめたstylesheet.cssと画像を全て1つのフォルダ内に用意しました。
そしてアプリとしてメインで動くmain.pyを以下のように作成しました。
#ライブラリの読み込み
import os
from flask import Flask, request, redirect, url_for, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
import cv2
#表示テキスト
classes = ["black","blue","red","white","yellow"]
massage = ["信頼感を持たれ実行力のある", "冷静で計画性のある", "情熱的で積極的な", "真面目で献身的な", "好奇心旺盛でセンスのある"]
num_classes = len(classes)
image_size = 100
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./model.h5')#学習済みモデルをロードする
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み
img = cv2.imread(filepath)
img = cv2.resize(img, (100,100))
predicted = np.argmax(model.predict(img.reshape(1,100,100,3)))
pred_answer = "名刺のキーカラーは " + classes[predicted] + " です"
pred_massage = "この名刺には" + massage[predicted] + "印象を持たれます"
return render_template("index.html",answer=pred_answer, answer2=pred_massage)
return render_template("index.html",answer="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)このアプリでは、名刺のキーカラーを表示するだけでなく、キーカラーに基づいた印象を答える機能も持たせました。また30〜40個ほど自分で名刺をデザインし、グリッドレイアウトにして配置しました。
最後にHerokuにコマンドプロンプトからデプロイし、無事公開することができました。

https://card-key-color.herokuapp.com/
おわりに
VGGやランダムフォレストなどの分類モデルを適切に使用することによって、私のような初心者でもある程度の画像認識の精度を出せることができました。しかしその一方で、特定のタスクに適した学習データを用意するのは自分で集めるしかないので、今回の検証では学習データの大切さを実感しました。
引き続き「AIはデザインを理解できるのか」を検証したいので、次回はレイアウトや要素の大小に基づく印象の違いを検証したいと思います。そしていつかAIとデザインの機能を活かしたサービスを作りたいと考えています。
この記事が気に入ったらサポートをしてみませんか?