honyaclub クローラー | honyaclubから店舗情報をスクレイピング

honyaclubとは?
オンライン書店 Honya Club.comホンヤクラブドットコム、本、コミック、CD、DVD、ブルーレイ、洋書、雑誌定期購読、オンライン書店、ネット書店、通販、通信販売、オンラインショップ、買い物、ショッピング、ほんらぶのページです。
スクレイピングツールの概要
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすく人工知能Webスクレイピングツールです。違う基盤のユーザーに二つのスクレイピングモードを提供し、1-Clickで99%のWebスクレイピングを満たします。ScrapeStormにより、大量のWebデータを素早く正確的に取得できます。手動でデータ抽出が直面するさまざまな問題を完全に解決し、情報取得のコストを削減し、作業効率を向上させます。
抽出されたデータは下記のようにご覧ください

(1)URLをコピーする
スマートモードは自動的にリスト要素を識別できます。ですから、リスクページのURLを入力するのを推薦します。今回は、東京都の店舗一覧ページからスクレイピング方法を紹介します。

(2)スマートモードタスクを新規作成する
ScrapeStormのホムページ画面にスマートモードタスクを新規作成します。また、持っているタスクをインポートすることもできます。
詳細には下記のチュートリアルをご参照ください。
URLを正しく入力する方法


2.タスクを構成する
(1)ページボタン
ソフトウェアは自動的にWebサイトのページボタンを識別できます。今回は識別成功になりますが、実は第二ページのページボタンを認識されました。手動で「次へ」ページボタンを選択してください。

(2)詳細ページに行く
店舗の詳細情報、電話番号、定休日などの情報を取得するために、詳細ページに移動してください。「詳細ページに行く」機能を利用してください。

(3)フィールドの追加と編集
「フィールドを追加」ボタンをクリックして、画面に必要な要素を選択、データが自動的に抽出されます。また、必要に応じてフィールドの名前の変更または削除、結合できます。
フィールドの設定の詳細には下記のチュートリアルをご参照ください。
抽出されたフィールドを配置する方法

3.タスクの設定と起動
(1)起動の設定
必要に応じて、スケジュール、アンチブロック、自動エクスポート、写真のダウンロード、スピードブーストを設定できます。
スクレイピングタスクを配置する方法については、下記のチュートリアルをご参照ください。
スクレイピングタスクを配置する方法

(2)しばらくすると、データがスクレイピングされる。

4.抽出されたデータのエクスポートと表示
(1)エクスポートをクリックして、データをダウンロードする
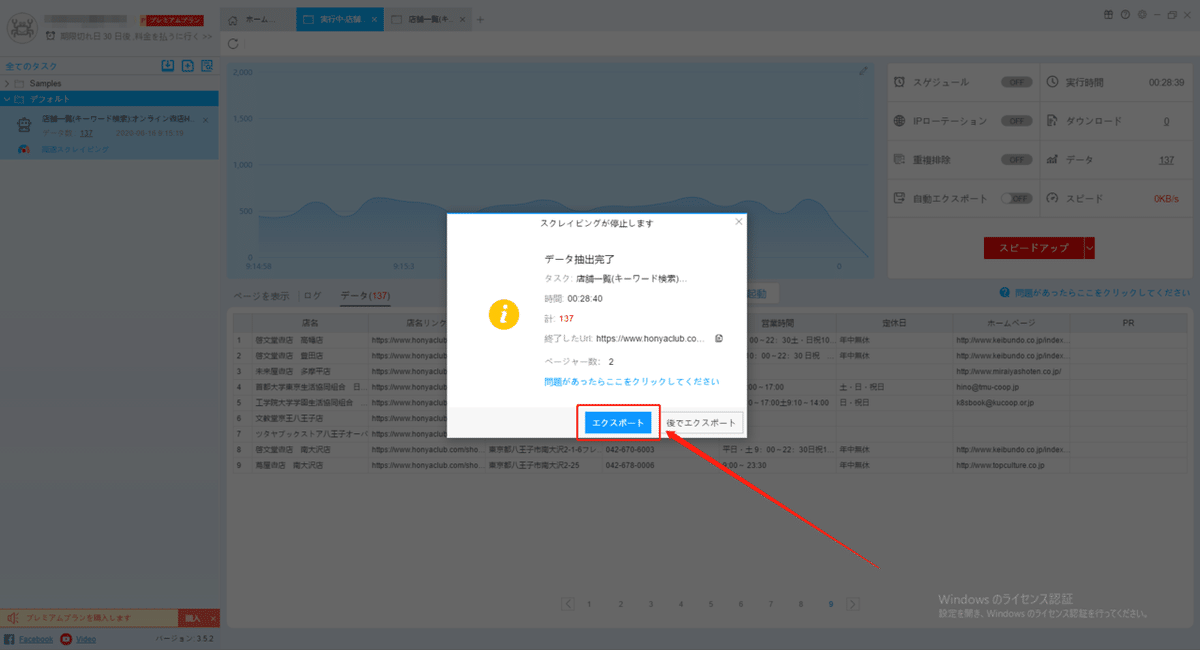
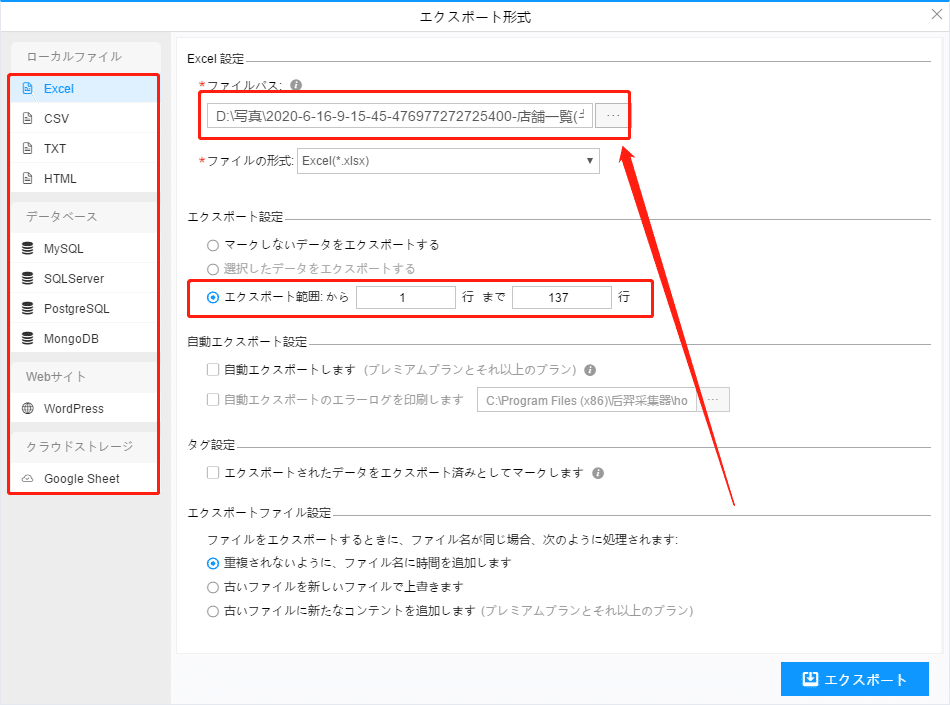
(2)必要に応じてエクスポートする形式を選択します。
ScrapeStormは、Excel、csv、html、txt、データベース、ローカルなどさまざまなエクスポート方法を提供します。ライトプラン以上のユーザーは、WordPressに直接投稿することもできます。
抽出結果のエクスポート方法の詳細には下記のチュートリアルをご参照ください。
抽出されたデータのエクスポート方法
この記事が気に入ったらサポートをしてみませんか?