
[ラズパイ / 電子工作]AIの「顔パス」システムを自作してみた

どうも~、IoT探検家のシンクンです。
皆さん、「顔パス」システムってご存知ですか?
古くは「顔パス」という言葉は、有名人が会員制のお店やテレビ局などのセキュリティの厳しい施設に、身分証の提示なしでスタッフに顔を見せることだけで入れることを指していましたが、最近ではスポーツイベントやライブ会場などでAIの顔認証モデルを利用して一般の人向けに「顔パス」システムが導入されており、今年開催された東京オリンピックでも関係者向けの入場で使われました。
僕も個人的に東京オリンピックにボランティアとして参加しまして、この顔認証を利用した「顔パス」システムを体験することができました😊。

そして今回は、その「顔パス」システムをラズパイを使って自作してみることにしました~。
用意したもの
・ラズパイ本体(Raspberry Pi 4)
・4インチのLCDモニター
・外付けのカメラ
・モバイルバッテリー
・キーボード
・microSDカード
・Movidius Neural Compute Stick 2 (NCS2)
自作の流れ
1)ラズパイの初期設定
2)ラズパイのタブレット化
3)顔認証モデルを準備
4) 「顔パス」システム完成
1)ラズパイの初期設定
まずは、Raspberry Pi(ラズベリー パイ)、略してラズパイという小型コンピュータを用意して、初期設定をします。
詳細は「[普通科高校卒の週末プログラマー]ラズパイの初期設定をしてみた」を御覧ください。
2)ラズパイのタブレット化
次にLCDモニターを別途用意して、組み立ててラズパイのタブレット化します。
詳細は「[普通科高校卒の週末プログラマー]手のひらサイズのタブレットを自作してみた」を御覧ください。
3)顔認証モデルを準備
ここからは「顔パス」システムに使う顔認証モデルを準備していきます。
今回は2つのモデルを比較してみました。
a. 「顔パス」システムの概要
b. 顔認証とは?
c. dlibのface recognitionモデル
d. OpenCVのface recognitionモデル + Movidius NCS
a. 「顔パス」システムの概要

顔パスシステムでは前もってユーザーが顔画像を撮影してデータベースに登録しておき、後ほどに再度カメラで撮影して、登録済みの写真と比較して認証をおこないます。
b. 顔認証とは?
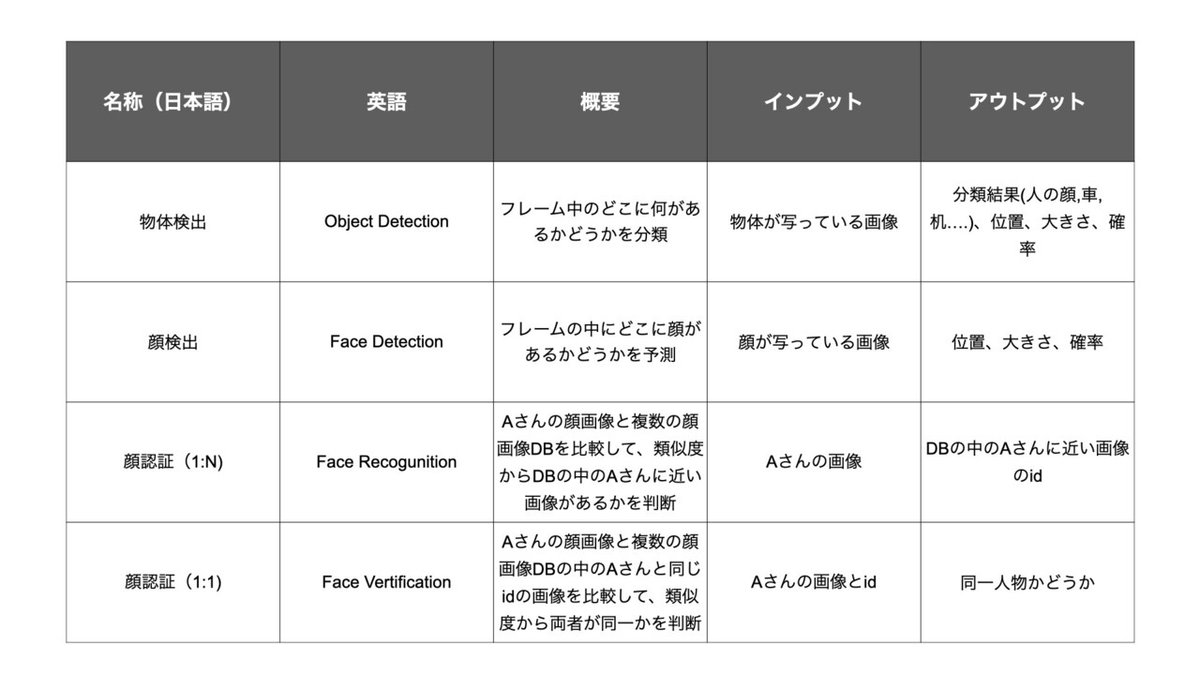
画像認識の分野のAIやディープラーニングについて勉強していると◯◯detectionや◯◯recognitionという名前のモデルが沢山出てきて混乱します。ですので最初にそれらを整理してみました。



人の顔に限らず車や家具などの複数の種類の物体を検出できるのが物体検出(Object Detection)で、人の顔に限定して検出するのが顔検出(Face Detection)。顔認証(Face Recognition)は顔検出で検出された顔から特徴量を抽出して、顔ごとの特徴量を比較し、類似度を元に「誰であるか?」の分類や「本人かどうか?」を予測。
そして、これらのモデルのうち、顔検出と顔認証の2つを使って「顔パス」システムは作られます。
(顔検出と顔認証の仕組みについては、Machine Learning is Fun! Part 4: Modern Face Recognition with Deep Learningというサイトの説明が詳しく、以下の「顔検出の仕組み」と「顔認証の仕組み」の説明で参照しました。)
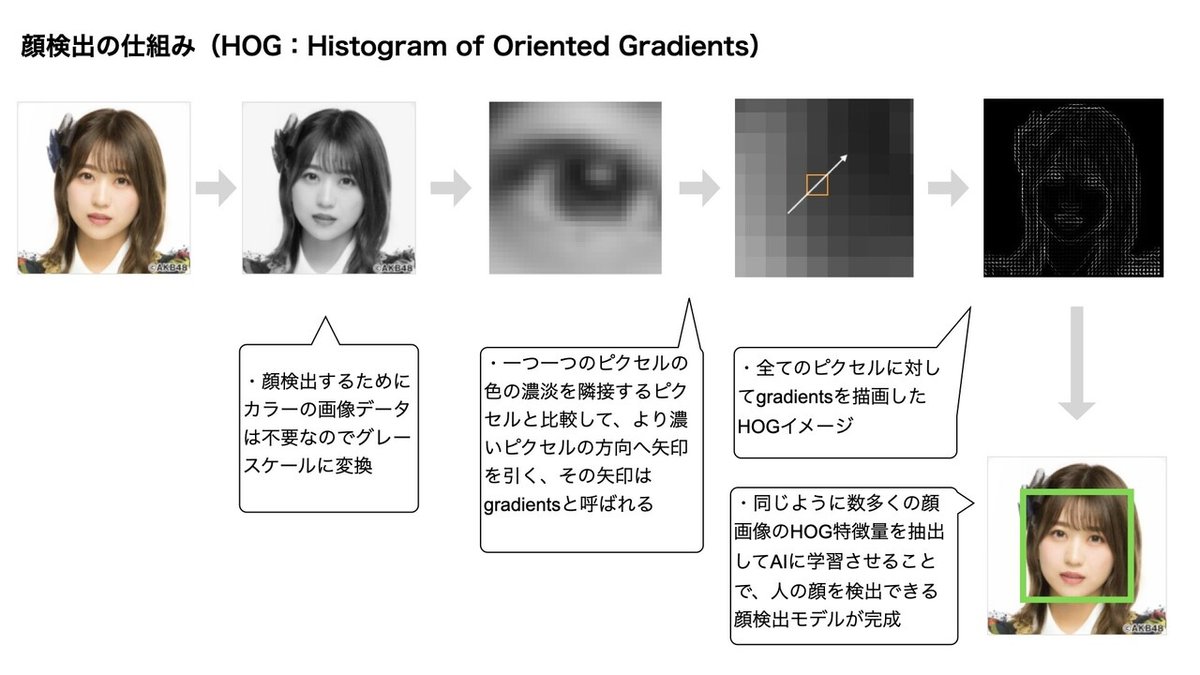
顔検出はAIの世界でも歴史がある分野なので沢山の検出方法が発表されていますが、その中でも2005年に発表されたHOG(Histogram of Oriented Gradients)という方法が有名です。
HOGではまず画像の色をフルカラーからグレースケールに変換します。次に、一つ一つのピクセルの色の濃淡を隣接するピクセルと比較して、より濃いピクセルの方向へ矢印を引きます(その矢印は勾配(gradients)と呼ばれる)。
その矢印を全てのピクセルで計算してHOG特徴量を抽出。これを数多くの顔画像に対しておこない、そのHOG特徴量をAIに学習させることで、人の顔を検出できる顔検出モデルが完成します。
補足
精度という面ではHOG以外にもディープラーニングを利用したモデルのようなより高い精度の顔検出モデルも存在するようですが、それらと比べてHOGはモデルが軽く、ラズパイのような処理能力が低い端末でも早く顔検出できるというメリットがあります。
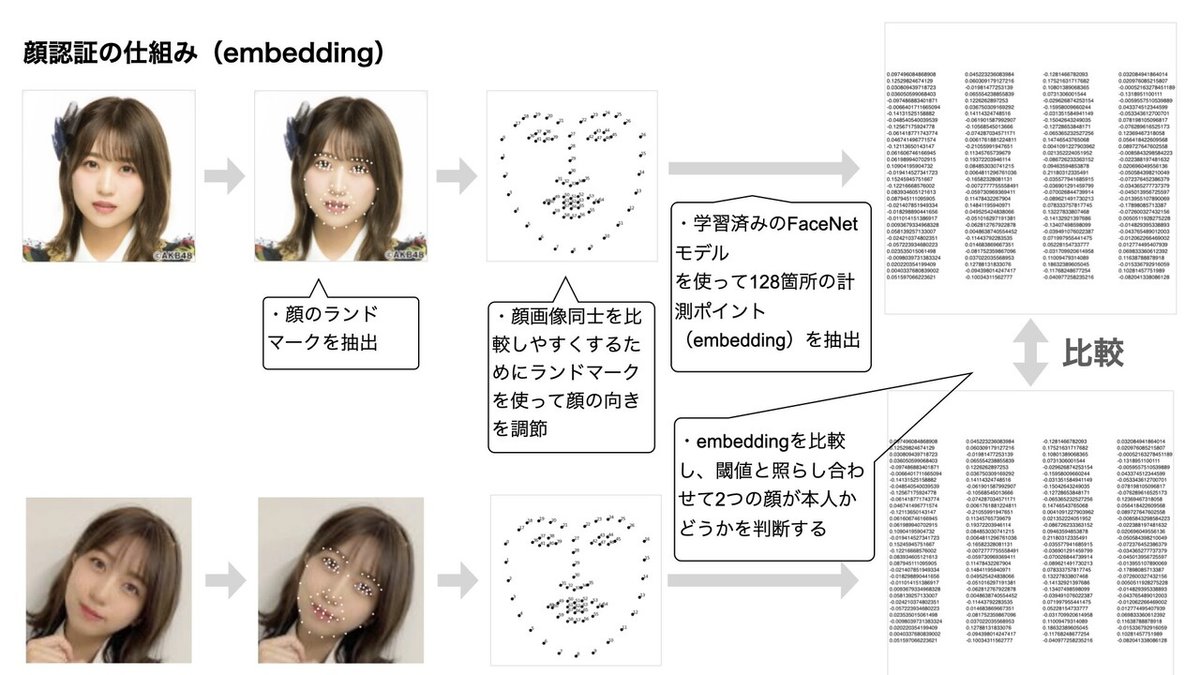
顔認証するためには複数の顔画像を比較する必要がありますが、顔が横や上を向いていたりすると比較しにくくなります。
その問題を解決するために、顔のランドマークを抽出して、真っ直ぐになるように回転して調節し比較しやすい画像を作成。
次に顔画像を比較するための計測ポイントを探します。その時に大切になるのが「どのポイントを使って比較すればスピーディーに精度の高い照合ができるのか?」という視点です。単純に画像そのものを比較すると時間がかかり過ぎます。
その計測ポイント自体もAI(ニューラルネットワーク)を使って見つけようとしたアプローチの1つが2015年にGoogleが発表したFaceNet。
FaceNetでは2枚の同じ人の顔画像と1枚の別人の顔画像を1組としてニューラルネットワークに入力して、同じ人の顔画像同士でより一致しやすい128箇所の計測ポイントを学習して探し出します。(この128箇所の計測ポイントはembeddingと呼ばれる。)
また、この学習済みのFaceNetモデルはPythonとTorchのface recognitionの実行モジュールOpenFaceとして利用できるようになっています。
そして、各顔画像からembeddingを抽出できたら顔認証をおこないますが、やり方が以下の2つあります。
・各顔画像から抽出したembeddingを距離を比較して、閾値と照らし合わせて本人かどうかを予測する
・各顔画像から抽出したembeddingと名前をニューラルネットワークに学習させて顔を予測するモデルを作る
今回は距離を比較して本人かどうかを予測する方法でやろうと思います。
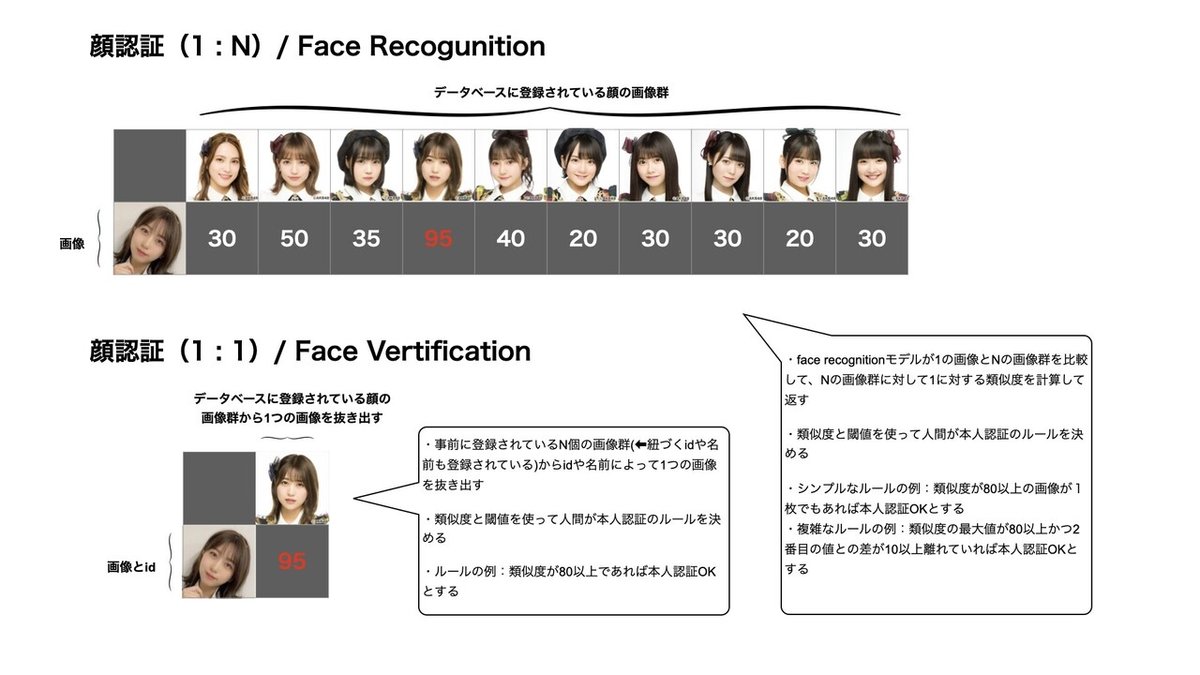
更に、顔認証モデルにはFace Recogunitionと呼ばれる「1枚の入力画像」と「複数の画像」を照合する1:Nのものと、Face Vertificationと呼ばれる「1枚の入力画像 + 画像に紐づくID」と「複数の画像から抽出した1枚画像」を照合する1:1のものの2種類があります。
この2つを比べた場合、Face Vertificationの方は精度が高い認証ができるというメリットがある一方、ユーザーに顔以外にIDなどを別途登録してもらう手間をかけさせてしまうデメリットがあります。Face Recogunitionの方は逆にFace Vertificationよりは精度は落ちるけど、余計な手間が掛かりません。
実際にビジネスで「顔パス」システムを実運用するときにはこれらのメリットとデメリットを見比べたり、ネットにつないで有料のapiの使うか、スタンドアローンでオープンソースのモデルを使うかなどを考えたりして、オペレーションにあったモデルを選ぶ必要があります。


今回は実験なので、顔画像登録のフローは省略して(➡前もって画像を用意)、1:Nの認証のフローを作りました。
顔認証(Face Recogunition)の仕組みのまとめ
・顔画像登録:事前にAさん含む複数の人の顔を、カメラで顔写真を撮影して登録する
・認証:再度カメラでAさんの顔を捉えて、それと登録済みの顔画像を比較して、類似度から登録済みの顔画像の中のAさんに近い画像があるかを判断して認証する
c. dlibのface recognitionモデル
まず、試した顔認証モデルはオープンソースのdlibのモデルです。(海外のサイト[What is the Best Facial Recognition Software to Use in 2021?]では、現在最も人気の高いオープンソースの顔認証モデルと紹介されています。)
dlibとは
機械学習,数値計算,グラフィカルモデル推論,画像処理などの機能をを持つ C++のライブラリ。コンパイルしてPythonで利用できる。
dlibの顔認証モデルの利用はPythonの仮想環境とOpenCVのインストールを前提しています。これらの詳細は「[39歳 / 普通科高校卒]ラズパイにOpenCVをインストールしてみた」を御覧ください。
pip install dlib
pip install face_recognition上のコマンドでpipを使って、dlibとface_recognitionをインストール。そしてgithubのサイトからコードをダウンロードして、ラズパイにフォルダを置きます。
dlibの顔認証モデルには様々なサンプルコードが用意されていますが、facerec_from_webcam.pyを選択。
#カメラ動画から顔を検出
face_locations = face_recognition.face_locations(rgb_frame)
#顔部分をエンコード
face_encodings = face_recognition.face_encodings(rgb_frame, face_locations)
#入力画像とDBの画像のdistanceを比較した上で同一人物かどうかを判定して、trueの場合はmatchesリストに配置
matches = face_recognition.compare_faces(known_face_encodings, face_encoding)
# 入力画像とDBの画像のdistanceを計算して返す
face_distances = face_recognition.face_distance(known_face_encodings, face_encoding)
# distanceが最小値の入力画像を本人として扱う
best_match_index = np.argmin(face_distances)このコードでは、カメラからの動画をインプットにして、インプットとDBの画像群のベクトル距離(distance)を計算し、距離が最小の画像の人の名称やその距離をアウトプットとして返してくれます。
#imutilsからFPSをインポート
from imutils.video import FPS
# 推定器を通してfpsをスタートさせる
fps = FPS().start()
# fpsをターミナルに表示
fps.stop()
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))また、顔認証の処理スピードを検証するために上のようなfpsを計算するコードをfacerec_from_webcam.pyに追記。
fpsとは
1秒間の動画が何枚の画像で構成されているかを示すの単位のこと。数値が高いと滑らかな動画、低いとカクカクした動画になる。
cd /home/pi/Desktop/face_recognition-master_dlib/examples
python facerec_from_webcam.py上のコマンドのように、face_recognition-master_dlib/examplesに移動して、facerec_from_webcam.pyを実行しました。
すると、このような結果が返ってきます。
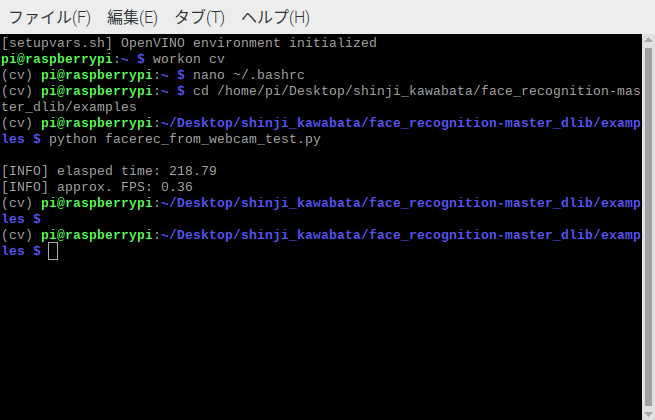
fpsが0.36...
dlibの顔認証モデルは精度はかなり高い一方、ラズパイでは計算処理能力の低さが原因で、処理スピードが遅くなることが分かりました。
処理スピードが遅いとスムーズに認証するのが難しくなります。そのため、次は別の方法を試すことにしました~。
d. OpenCVのface recognitionモデル + Movidius NCS
次に試したのはOpenCVを使ったface recognitionモデルで、フォルダは以下のようになっています。(こちらのサイトを参考にしました。)
先程のdlibのface recognitionモデルと同じ流れで、まずはface detectionで顔検出してからface recognitionで入力画像とDBの画像のdistanceを計算し比較して類似度を返します。
使ったface detectionモデルはOpenCVで利用できるCaffeの学習済みのもので、face recognitionのほうは、PyTorchの学習済みOpenFaceを使って抽出した各画像の128次元のベクトルを基にして類似度を返しています。
Caffeとは
オープンソースのディープラーニングライブラリです。 画像認識に特化しており、「高速動作」「GPU対応」「洗練されたアーキテクチャ/ソースコード」「開発コミュニティが活発」などの特徴があり、 C++/Python/MATLABなどで使用できる。
OpenFaceとは
2015年にGoogleが発表した、顔の画像から顔の特徴量を抽出し、顔の画像の埋め込み(Embedding)と呼ばれる、画像の特徴の128要素のベクトル表現を予測する顔認証用のニューラルネットワークFaceNetの論文( FaceNet: A Unified Embedding for Face Recognition and Clustering)を基にした、PythonとTorchのface recognitionの実行モジュール
Embedding(画像の埋め込み)とは
ベクトル空間に、画像の特徴量を表すベクトルを埋め込むことで画像を表現する。その埋め込まれた低次元の特徴ベクトルを抽出することで、画像の内容のある程度の指標が示され、有意な比較を行うことができる。
そして顔認証を実行します。(下のコードはrecognize_video.pyからの抜粋)
#Caffeの顔検出モデルを利用
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
#PyTorchの学習済みOpenFaceを使ってEmbedding(画像の埋め込み)
embedder = cv2.dnn.readNetFromTorch(args["embedding_model"])
#2枚の画像のEmbedding(画像の埋め込み)を比較するメソッドを定義
def who_is_it(vector,dataset_encode):
encoding = vector
min_dist = 100
for i in range(len(data["embeddings"])):
#Embedding(画像の埋め込み)済みのデータセットの各画像を読み込み
db_enc = data["embeddings"][i]
name = data["names"][i]
#インプット画像とデータセットのEmbedding(画像の埋め込み)のユークリッド距離(L2ノルム)を計測
dist = np.linalg.norm(encoding - db_enc)
if dist < min_dist:
min_dist = dist
identity = name
print(min_dist)
return min_dist, identity
#カメラからのビデオストリーミングに対して繰り返す
while True:
frame = vs.read()
frame = imutils.resize(frame, width=600)
(h, w) = frame.shape[:2]
imageBlob = cv2.dnn.blobFromImage(
cv2.resize(frame, (300, 300)), 1.0, (300, 300),
(104.0, 177.0, 123.0), swapRB=False, crop=False)
#顔検出モデルをセット
detector.setInput(imageBlob)
detections = detector.forward()
#顔が検出されたら繰り返す
for i in range(0, detections.shape[2]):
#顔である確率を受け取る
confidence = detections[0, 0, i, 2]
if confidence > args["confidence"]:
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
face = frame[startY:endY, startX:endX]
(fH, fW) = face.shape[:2]
if fW < 20 or fH < 20:
continue
faceBlob = cv2.dnn.blobFromImage(cv2.resize(face,
(96, 96)), 1.0 / 255, (96, 96), (0, 0, 0),
swapRB=True, crop=False)
#OpenFaceをセットしてEmbedding(画像の埋め込み)を抽出
embedder.setInput(faceBlob)
vec = embedder.forward()
#2枚の画像のEmbedding(画像の埋め込み)を比較するメソッドをセット
similarity, name = who_is_it(vec, data)
text = "{}: {:.2f}%".format(name, similarity)
y = startY - 10 if startY - 10 > 10 else startY + 10
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(frame, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(frame, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)まずはextract_embeddings.pyでデータベースの画像に対して前もってエンコードして特徴ベクトルを取得しておき、recognize_video.pyでデータベースの各画像の特徴ベクトルとの距離(distance)をL2ノルムを使って計算し、距離が最小の画像の人の名称やその距離をアウトプット。
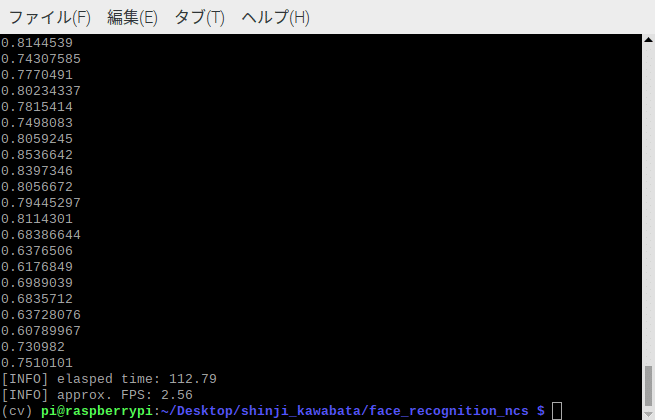
するとfpsの値は2.56となり、dlibの顔認証モデルと比較すると処理スピードが随分早い結果がでましたが、更に処理スピードを高速化するために、Movidius Neural Compute Stick 2 (NCS2)という外付けUSBアクセラレータを利用できるようにカスタマイズしてみました。(ちなみにdlibの顔認証モデルはNCS2に対応していません....)
Movidius NCS2とは
Intelの傘下であるMovidius社が開発している、深層学習の推論処理を高速化する,外付けUSBアクセラレータ。
VPU(Vision Processing Unit) という、半精度浮動小数点数と8bit固定小数点数の行列演算ユニット「Myriad」を搭載しており、深層学習の推論処理をこのMyriadに委任させることで、低スペックの組み込み機器でも推論を高速に行うことが出来る。(参照サイト:「Neural Compute Stick 2 の速さを知る」)
cd ~
#OpenVINOツールキット(4.1.1)をダウンロード、新しいバージョンだと後ほど利用することになるOpenCVのfacerecognitionモデルでエラーになる
wget https://download.01.org/opencv/2019/openvinotoolkit/R2/l_openvino_toolkit_runtime_raspbian_p_2019.2.242.tgz
#ダウンロードしたOpenVINOツールキットを解凍して、openvinoファルダに配置
tar -xf l_openvino_toolkit_runtime_raspbian_p_2019.2.242.tgz
mv l_openvino_toolkit_runtime_raspbian_p_2019.2.242 openvino
#設定ファイル.bashrcの末尾に「source ~/openvino/bin/setupvars.sh」と追記して、.bashrcファイルを読み込み
nano ~/.bashrc
source ~/openvino/bin/setupvars.sh
source ~/.bashrc
#カレントユーザーをRaspbian(ラズパイのOS)のユーザーグループに追加
sudo usermod -a -G users "$(whoami)"
#USBルールを設定
sh openvino/install_dependencies/install_NCS_udev_rules.shMovidius NCS2を利用するために、まずOpenVINOというIntelの推論用のフレームワークを上のようなコマンドでラズパイにインストールして設定します。(ラズパイへの公式のインストール方法はこちらのページに書かれています。)

設定後に上のコマンドにより、仮想環境に入ってsetupvars.shファイルを読み込み、openvinoの4.1.1バージョンがインストールされていることをテスト。
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
#顔検出モデルに(Movidius NCS2に内蔵されている)Myriadプロセッサをセット
detector.setPreferableTarget(cv2.dnn.DNN_TARGET_MYRIAD)
embedder = cv2.dnn.readNetFromTorch(args["embedding_model"])
#PyTorchの学習済みOpenFaceに(Movidius NCS2に内蔵されている)Myriadプロセッサをセット
embedder.setPreferableTarget(cv2.dnn.DNN_TARGET_MYRIAD)そしてrecognize_video.pyのコード内のCaffeの顔検出モデルdetectorとOpenFaceモデルembedderに対してsetPreferableTarget(cv2.dnn.DNN_TARGET_MYRIAD)として、(Movidius NCS2に内蔵されている)Myriadプロセッサをセットします。
これでMovidius NCS2を使って顔検出と画像の埋め込みができるようになったので顔認証を実行。するとこのようにフレーム内に動画で顔認証の結果が返ってきます。

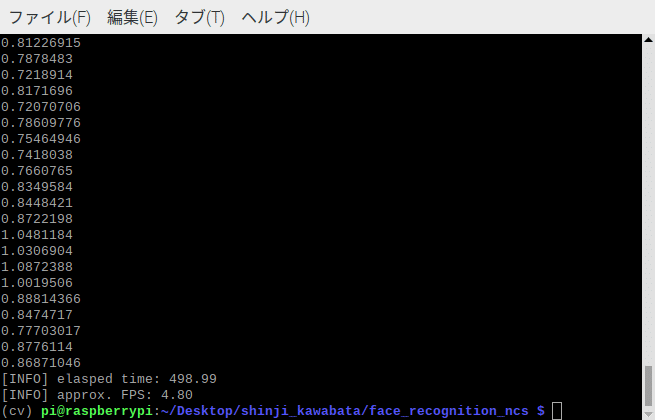
fpsの値は4.80となりました😊。
これぐらいの値が出ていれば処理スピードも問題なく、スムーズに認証することができますね。
4) 「顔パス」システム完成
ここまで出来たら、いよいよカメラとスピーカーをラズパイに取り付けて組み立てをおこないます。


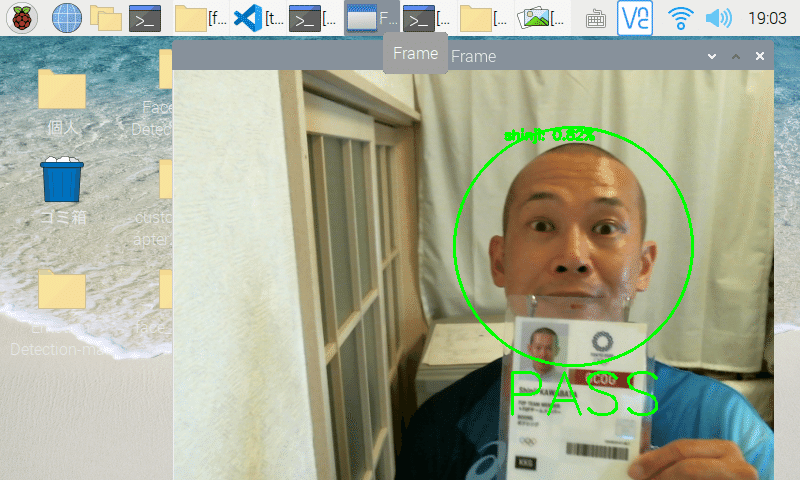
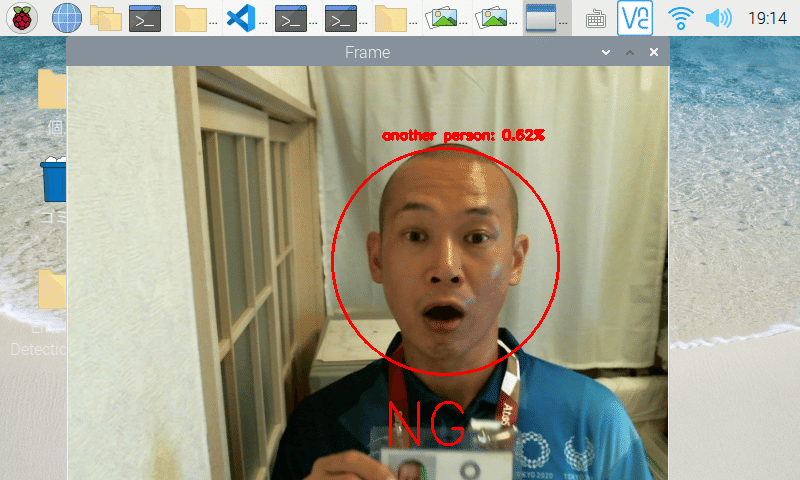
組立後のデバイスの前に立ち、カメラに顔を見せます。
そして類似度が閾値以上の場合は本人と認定され、モニターに「PASS」と表示し、「類似度が一番高い画像に紐づく名称」と「類似度」を描写します。
一方、類似度が閾値以下の場合は認証NGとなり、モニターに「NG」と表示します。
振り返り
・「顔パス」システムは顔検出と顔認証の2つのモデルが使われている。
・顔認識モデル:エッジでラズパイのような処理能力が低い端末でも早く顔検出するにはディープラーニングのモデルは不向き
・顔認証モデル:Embedding(画像の埋め込み)を利用することで、顔画像同士を簡潔に比較できるようになる。
・今回の「顔パス」システムの自作にかかった時間は720分でした。ラズパイで認証の精度とスピードを両立できるモデルを見つけるのに思ったより時間がかかりました。
・次は有料APIのAmazon Rekognitionを使った顔認証にチャレンジしてみたいです。
Youtubeで見る
この記事が気に入ったらサポートをしてみませんか?