
DMBOK第8章データ統合と相互運用性

要約
データ統合における基本的なETLプロセスやELTの概要、バッチ処理とリアルタイム処理の違い、データ統合ソリューションの開発手順が説明されています。
具体的には、データ抽出から取り込み、変換、データストアへの格納までのステップや、リアルタイムや同期処理の必要性、さらにデータ統合ソリューションの計画、分析、データ探索、ドキュメンテーション、プロファイリング、業務ルールの収集など、包括的なデータ統合の側面に触れています。
前章
前の章である第7章データセキュリティはこちらです。
データ統合に関する一般的な知識
抽出、変換、取込(ETL)
データ統合と相互運用性に関わる全領域の中心にあるのはETLという基本プロセスです。これらはアプリケーションや組織間でデータを移動するために不可欠なステップになります。
抽出プロセスは、データソースから必要なデータを選択して抽出します。このプロセスが業務システムされる場合、運用プロセスに悪影響を及ぼさないように可能な限り少ないリソースを利用するように設計するのが理想的です。
ただし、レプリカを作成したり、データソースに負荷をかけないようなサービスが登場しています。
変換は文字通り、データソースのデータを変換します。
変換の例として、フォーマットの変更やデータ構造の変更、意味的変換、重複排除、並び替えなどが行われます。
取り込みは一次変換したデータをターゲットデータストア物理的に格納されたり提供されたりすることです。データは様々な理由により、他のデータと統合するためにさらなる処理を必要とする場合もあります。
ELT
ELTとは、ETLに対してプロセスの順序を変更したものになります。ELTを利用すると、取り込みプロセスの一環としてターゲットシステムへの変換が実行されます。
このやり方はELTがデータレイクを取り込むビッグデータ環境では一般的になります。詳細は下記の記事をご覧下さい。
バッチ
多くのデータは、定期的に利用者や自動的な要求に応えて、アプリケーションや組織の間を一定量まとまって移動します。このタイプの連携をバッチまたはETLと呼びます。
バッチ処理は、大量のデータを短い猶予期間で処理する場合に非常に便利です。このため、低レイテンシーのソリューションが利用可能な場合でも、データウェアハウスのデータ統合ソリューションに利用される傾向があります。
また、一部のデータ統合ソリューションでは、高速処理と低レイテンシーを実現するためにマイクロバッチ処理を利用し、日時処理よりもはるかに高い頻度(5分毎など)でバッチ処理を実行するように予定を組んだりします。
リアルタイム、同期
データソースとターゲットのデータ間に起きる時間の遅れや相違が許容されない状況があります。完全に同期させ必要がある場合は、リアルタイム方式の同期ソリューションを利用する必要があります。
例えば、金融機関では2相コミットを利用して、金融取引テーブルが財務バランステーブルと確実に同期するようにします。可能性は低いですが、アプリケーションができず中断された場合、片方のデータセットだけが更新され、もう片方は更新されないということが起きます。
低レイテンシまたはストリーミング
低レイテンシーのソリューションにおける追加コストが正当化されるのは、組織が長距離間で非常に高速のデータ移動を必要とする場合です。
ストリーミングデータはイベントが発生したときに、コンピューターシステムからリアルタイムで連続して流れます。データストリームは、ECサイトの商品や金融商品の購入、SNSへのコメントなどのイベントを捉えます。
下記の記事で詳細な説明とユースケースを知ることができます。
計画と分析
データ統合とライフサイクル要件の定義
要件を決めるのは通常、業務アナリスト、データスチュワード、データアーキテクトによって定義されます。
要件を定義するプロセスにより、メタデータが作成されたり、突き止められたりするため、ライフサイクル全体を通して管理する必要があります。
こちらにも同じことが記載されています。
データ探索の実行
データ探索の目標はデータ統合のための潜在的なデータソースを特定することです。このプロセスはメタデータや組織のデータセット上にある実際のコンテンツをスキャンするツールを利用した技術的な検索と対象の専門知識を(対象のデータを扱う人へのインタビュー)によって行われます。
データリネージのドキュメント化
分析対象のデータが組織によってどのように取得、作成され、組織内のどこへ移動し、どこで変更されるのかをドキュメントにします。
ただし、データリネージを可視化できるようなサービスがあればドキュメント化を必ずしなければならないということはありません。
データのプロファイリング
データプロファイリングとは、データを調査および分析して有用なデータのサマリーを作成するプロセスのことです。実際にデータを見てみると、想定した内容とは異なったものであることが多いです。
プロファイリングの1つの目標はデータ品質を評価することです。特定用途のためにデータの適性を評価するには業務ルールを明確にし、データがその業務ルールをどの程度満たしているかを評価します。
業務ルールの収集
業務ルールは要件の重要な部分を占めます。業務ルールは業務処理のある側面を定義し、制約する記述です。
業務ルールは業務用語の定義、用語を相互に関係づける事実、制約や実行条件、導出の4つのカテゴリのいずれかに分類されます。
データ統合とソリューションの設計
データ統合アーキテクチャの設計
全社標準を確立することで組織は各ソリューションの導入に費やす時間を節約できます。既存のデータ統合と相互運用性のコンポーネントをなるべく再利用して、実現可能な要件を満たすソリューションを設計します。
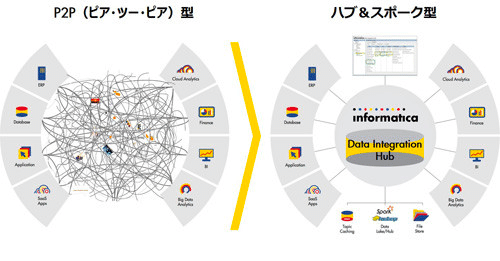
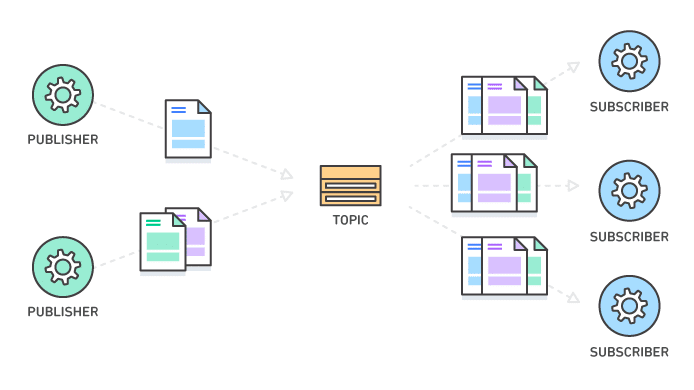
データ連携モデルの選択
ハブ&スポーク、ポイント・ツー・ポイント、パブリッシュ・サブスクライブの中から要件を満たすモデルやその組み合わせを決定します。
データソースのターゲットへのマッピング
データソースをターゲットにマッピングするには、ある場所のあるフォーマットから別の場所の別のフォーマットにデータを変換するルールを指定する必要があります。
変換はバッチで実行される場合もありますが、リアルタイム・イベントの発生がきっかけになる場合もあります。
データオーケストレーションの設計
データフローを設計しドキュメント化する必要があります。データ統合の開始から終了までのデータフローのパターンを記し、変換やトランザクションを完了するための中間ステップも含まれます。
データオーケストレーションツールの例としては、Airflow、Prefect、Dagster等があります。
データ統合ソリューションの開発
データサービスの開発
上記のデータ連携モデルに従って、データにアクセスし、変換し、配信するサービスを開発します。ただし、ツールやベンダー製品群を使用することで運用サポートを簡素化し、運用コストを削減できます。
データフローの開発
開発したデータサービスをスケジューラに設定してバッチ処理で連携します。
リアルタイムのデータ統合フローを開発するにはデータの取得、変換、パブリッシュのためにサービスの実行を起動するイベントを監視する必要があります。
データ移行方法の開発
新しいアプリケーションが導入されると既存のデータを移動させる必要があります。旧来のアプリケーションのデータを新たなアプリケーションに合わせてフォーマットを変換して移行します。
パブリケーション方法の開発
重要なデータを作成し維持するシステムでは、そのデータを組織内の他のシステムで利用できるようにします。組織内の様々なタイプのデータに対して共通のメッセージ定義(カノニカルモデル)を作成します。それを適切なアクセス権限を持つデータ利用者かサブスクライブし、関心のあるデータへの変更通知を受信できるようにします。これがベストプラクティスになります。
まとめ
以上、データ統合と相互運用性について解説しました。
この章はかなり広い範囲を体系化しているので、非常に分かりづらく、難解な単語や概念が登場しました。全てを理解する必要は無く、実際に開発や構築をする上で理解を深めていくという方法で良いと思います。
もし他の本で知識を得たいのであればこちらをおすすめします。
DMBOKのデータ統合と相互運用性について特に重要な点を解説しました。ただし、非常に量が多いため解説していない部分が多々あります。詳細は本書を手にとってみて下さい。
また、DMBOKの各章をまとめた一覧はこちらです。
この記事が気に入ったらサポートをしてみませんか?