
シアトルで実践する「プログラミング的思考」[12] 抽象化(1)分解による抽象化

「抽象化 (abstraction) 」は「プログラミング的思考」の派生元と言われている「コンピューテーショナルシンキング」の4つの主要概念のうちのひとつです(その他は分解、パターン認識、アルゴリズム設計)。
「抽象化」がその4つのうちのひとつであることから、他の3つとは独立した概念のように感じるかもしれませんが、実際はお互い密接に関係しています。その関係を表すのは少し難しいのですが、三角形を使って例えてみることにします。
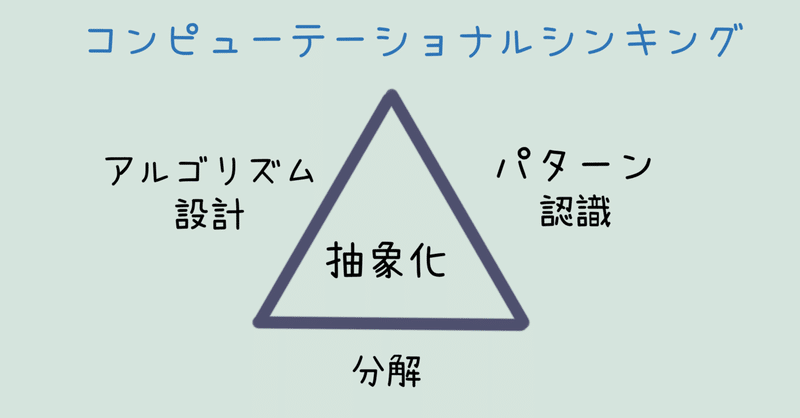
上図の三角形全体がコンピューテーショナルシンキングだとすると、3つの辺が分解、パターン認識、アルゴリズム設計に相当します。すると「抽象化」は三角形の真ん中の面に相当する、というイメージです。つまり分解、パターン認識、アルゴリズム設計はどれも抽象化の仲間であり、抽象化の考え方は3つの概念の分脈でも現れることを意味します。これは私独自の解釈なので、一般的ではありませんが、理解のヒントになればと思います。
分解した部品にディテールを隠して抽象化する
まず「分解」の文脈で「抽象化」を考えてみましょう。分解のおおまかな流れとしては、まず問題を分解していくつかの部分に分け、次にそれぞれの部分に対して解決策を実装し、最終的に全部の解決を統合して本来の複雑な問題を解決する、というふうになります。
その際、ある部分の解決を抽象化することで、システムの他の部分からは、その部分の「内部の複雑さ」が見えないようにすることが出来ます。この抽象化を全ての部分に施すことで、複雑さと詳細を「お互いから切り離す」ことが可能になります。
例えば自動車は運転手がハンドルで方向を決め、アクセルを踏めばその方向に進みます。ハンドル、タイヤ、アクセル、エンジン、その他様々な部品が連携して「人を運ぶという問題」を解決しています。
エンジンに注目して言えば、燃料とオイルを入れ、外部から操作すれば力強い回転エネルギーを生み出すことが出来ます。運転手はエンジン内部の細かい仕組みなどの「ディテール」は一切知らなくてもエンジンなどの部品を組み合わせて作られた車を利用して「移動問題」を解決出来ます。
ソフトウェアも同様に、ソフトウェア部品を抽象化することで、その部品内部のディテールを知らなくてもより大きな問題解決に利用できるようになります。
アルゴリズムを分解して抽象化する
まず「アルゴリズム」がどのように分解され抽象化されるかを見てみましょう。ここでは「アルゴリズム」という言葉を使いましたが「処理」や「プロセス」や「プログラム」という言葉に置き換えても構いません。どれも何らかの複雑な処理を表します。その複雑な全体を分解していくつかの小さな部分に分けます。この時「親処理」と「子供処理」に分けたとします。
子供処理という言葉は私がここで勝手に思いついた言葉で、一般的には使われていません。よくある表現では「サブプログラム」という言葉があります。親がメインで、子供がサブです。メインプログラムはサブプログラムに「特定の仕事」を任せます。対して、サブプログラムはその仕事に責任を持ちます。サブプログラムに特定の仕事を一任することで「処理の抽象化」を実現します。
仮に、生徒のテスト結果の平均値を計算するプログラムがあるとしましょう。平均値を求めるには合計を生徒の数で割るわけですが、メインプログラムが「合計計算に特化したサブプログラム」を利用したとします。この場合、このサブプログラムは合計を計算するディテールを内包しています。そしてメインプログラムは、サブプログラムがいったいどうやって合計を計算したのか知らなくても、その結果を使って平均値の計算をすることが出来ます(サブプログラムが返す合計値を生徒の数で割るだけですね)。ソフトウェア開発者がこのサブプログラムを作ることで「処理の抽象化」を実践したことになります。
さて、合計を計算するサブプログラムのアルゴリズムはとても簡単です。入力された全ての数値を足せばいいだけです。高度な処理をしているわけではありません。それでも抽象化することで様々な利点が生まれます。
合計計算は他の合計値を利用する計算、例えば標準偏差の算出などでも「再利用」できます。再利用されると作業効率と生産性が向上します。また多くのプログラムで利用されることで、そのサブプログラムの性能を向上しようとする動機が生まれます。サブプログラムの性能が上がった分、それを利用しているプログラムの質も向上するからです。
サブプログラムを関数として実装する
サブプログラムは多くの場合「関数」として実装されます。そして通常、関数には名前を付けます(あえて名前を付けないテクニックもあります)。関数につける名前は、合計値を出すものなら Sum() など、その機能を表すものを選びます。「名前を付けること」は抽象化の第一歩です。
またこの関数への「入力」を定義します。おそらく数値の配列になるでしょう。さらに関数からの「出力(戻り値)」も定義します。当然、入力の数値を全て足した数値です。「入力と出力を定義する」ことで抽象化をさらに進めます。
この段階で処理の抽象化は完了です。「関数の名前が何(What)であるか 」と「何(What) を入力するか」と「何(What) が出力されるか」を外から見える状態にするのです。そして同時に「(How) どうやって計算したか」は関数の内部ディテールとして見えない状態にします。内部ディテールに関しての作業は別に必要ですが、内部の更新が外部の更新を引き起こすことはありません。
ところで「外部から見えない」というのはその関数を呼び出して利用するプログラムから見えないということであって、プログラミングをする人間はその関数の手順は読める状態かもしれません。大切なのは、メインプログラムなど、サブプログラムを利用する実行するプログラムが、関数のディテールを知らなくても計算結果を得られるということです。
クイックソートの例
ところで少しだけ専門的になりますが「クイックソート」という有名なアルゴリズムを聞いたことがあるでしょうか?「ソート」という作業は並び替えのことで、例えば背丈の順に並べたり、商品を売上の順に並べたりすることです。
このアルゴリズムは「パーティション」と呼ばれる作業を何度もする必要があります。パーティションとは、例えばクラスの生徒たちを、ある適当に選んだひとりの生徒を基準にして「その生徒より背が高いグループ」を教室の後の方へ、「その生徒と背が同じか低いグループ」を教室の前の方へ分けるような作業を言います。
クイックソートのメインプログラムはこのパーティション作業を別のサブプログラムに完全に任せることで、パーティション作業の細かい手順を知らずに済みます。クラスの生徒を背を基準分ける方法がいく通りもあるように、パーティション作業もいくつかのバリエーションがあります。この時、パーティションを担当する関数が抽象化を実現して、どのやり方でパーティションされるかは知らなくても済むようになっています。クイックソートに興味がある人は検索してみてください。
サブプログラムのディテールを隠すことの利点
サブプログラムを関数として定義することで処理・計算の具体的な手順 (How) を関数の内部ディテールとして隠すという作戦があることは分かりましたが、なぜ隠している状態の方が良いのかを見ていきましょう。
まずひとつめに、関数内のアルゴリズム(手順 How) を比較的簡単に「変更」出来るということが挙げられます。例えば、平均値を求める計算方法はいくつかの方法があるかもしれません。別の方法が適していると後で分かったとしたら、その方法を採用したいと考えますよね?仮に変更を加えるとしたら、その際に気を付けなくてはならないのが、変更によってプログラムが機能しなくなってしまう事態です。幸いサブプログラムの内部は外部から見えない状態なので、見えない部分を変更しても外部への影響は限定されます。車のエンジンを改造しても車全体は機能し続けるのに似ています。
関数内のアルゴリズムなどのディテールを変更する理由は様々ですが最も多いのが「最適化」です。特に複雑な処理をする関数の場合、処理にかかる時間が長すぎたり、使用するメモリ量が多過ぎたりするかもしれません。そういう問題が発見された際も、利用しているプログラムの機能そのものは保ちつつ、処理の手順などを改善することで処理速度を向上させたり、使用するコンピュータ資源を節約したり出来るのです。
このように処理の抽象化は、構造的に整理されているという利点に加えて「変化をマネージしやすい」という利点もあるのです。
この記事が気に入ったらサポートをしてみませんか?