最適なLLMを見つけるためのガイド

背景
近年、人間の指示に従う能力や会話能力を高めるために、教師ありファインチューニング(SFT: Supervised Fine-Tuning)や人間のフィードバックを用いた強化学習(RLHF : Reinforcement Learning from Human Feedback)を活用したLLMのチャットアシスタントが増えている。これらのモデルが人間の指示や好みに沿って調整(アラインメント)された場合、それらが構築された元のモデル(SFTやRLHFを受けていないモデル)よりもユーザーによって好まれる傾向があることわかっている。しかし、ユーザーの好みが高まったとしても、従来のLLMベンチマークでのスコアが必ずしも向上するわけではない。この現象は、チャットボットの有用性に対するユーザーの認識と、従来のベンチマークが採用する基準との間に基本的な食い違いがあることを示唆している。
現在の評価方法では、LLMが実際に人間とどれだけ自然にやり取りできるか、つまり人間が実際に望むような対話能力を持っているかを完全には捉えられていないのである。これは、質問に対する直接的な答えを見つける能力だけでなく、より複雑で自然な会話の流れの中で指示に応えられるかどうかも大切だということを意味している。
MT-benchとChatbot Arena
この問題に対処するため、LMSYS Orgは2つの新しいベンチマーク、MT-benchとChatbot Arenaを導入した。MT-benchは、80個の質問に対してLLMに回答させ、その回答をGPT-4のような強力なLLMによって採点させることで、スケーラブルなベンチマークを実現している。Chatbot Arenaは、匿名で選ばれた2つのLLMが、同じ質問に対して回答し、どちらが優れているのかをユーザーに投票してもらうことで、リーダーボードを作成している。
人間による評価は人間の好みを評価するための"ゴールドスタンダード"ですが、非常に遅く、費用がかかる。MT-benchでは、この評価を自動化するために、GPT-4のような最先端のLLMを人間の代わりとして使用している。これらのモデルはしばしばRLHFで訓練されており、既に強い人間との一致を示しており、この論文によればGPT-4による評価が人間の評価と80%以上の一致率を達成し、人間同士の合意レベルと同じレベルに達していると言われている。また、Chatbot Arenaではクラウドソーシングを利用して大量に回答を収集することに成功している。
最適なLLMを見つけるためのガイド
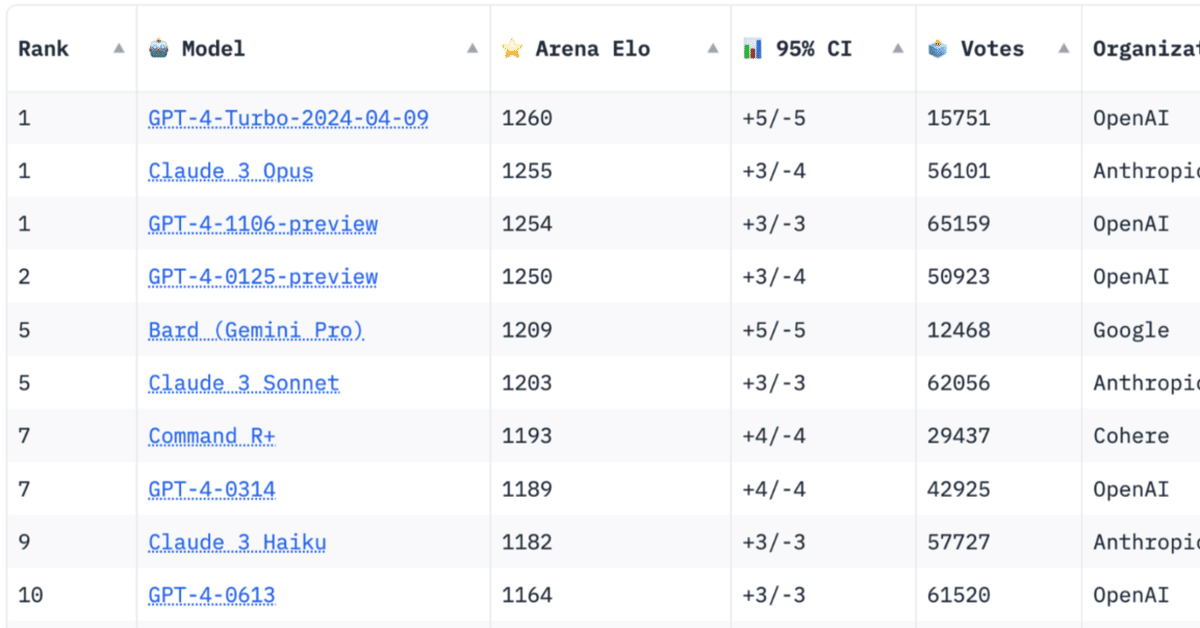
ユーザーにとって最適なLLMを見つけることは、多様な選択肢がある中で一筋縄ではいかない場合がある。そんな時、LMSYS Chatbot Arena Leaderboardをチェックするのが、素早く全体の性能を把握する手段となり得る。

リーダーボードによると、GPT-4-Turbo-2024-04-09が最もユーザーに好まれているLLMだということが分かる。
しかし、目当てのLLMがChatbot Arenaに掲載されていない場合や、より詳細な分析を求める場合には、MT-Benchを使用してスコアを計算することも一つの解決策である。
また、Chatbot Arenaでは英語の回答が多く、そのため英語での性能が主に評価される傾向にある。英語でのパフォーマンスを重視する場合にChatbot Arenaは有用であるが、日本語などの性能が知りたい場合には注意しなければならない。
一方、MT-Benchは、日本語バージョンを含む複数の言語でテストが行われるため、英語以外の言語に対する性能を確認することも可能である。
しかし、MT-Benchにもいくつかの限界がある。まず、質問セットが80問と比較的少ないため、LLMの能力を全面的に評価するには不十分かもしれない。また、質問の内容が難しいものが多く含まれているため、特定のユーザーの用途に合致しているかどうかは、内容を詳細に検討する必要がある。
LLMの日本語の性能比較
まず、日本独自のChatbot Arenaとして、日本語チャットボットアリーナがある。こちらは筆者が作成したもので、本家のChatbot Arena同様、匿名で選ばれた2つのLLMが、同じ質問に対して回答し、どちらが優れているのかをユーザーに投票してもらうことで、リーダーボードを作成している。ただし、ユーザーからの質問ではなく、用意された質問に対しての回答を利用している点に注意が必要だ。
次に、Stability AIが提供するJapanese MT-Benchがある。これはMT-Benchを日本語化したもので、本家のMT-Bench同様、80個の質問に対してLLMに回答させ、その回答をGPT-4のような強力なLLMによって採点させる。具体例を以下に示す。
問題: 1
カテゴリ: coding
問1: ディレクトリ内の全てのテキストファイルを読み込み、出現回数が最も多い上位5単語を返すPythonプログラムを開発してください。
問2: それを並列化(parallelize)することは可能ですか?
公平な判断者として行動し、以下に表示されるユーザーの質問に対するAIアシスタントの応答の品質を評価してください。あなたの評価は、応答の有用性、関連性、正確性、深さ、創造性、詳細度などの要素を考慮すべきです。AIアシスタントの返答の言語は、ユーザーが使用している言語と一致しているべきで、そうでない場合は減点されるべきです。評価は短い説明から始めてください。できるだけ客観的であること。説明を提供した後、このフォーマットに厳密に従って1から10までのスケールで応答を評価する必要があります:"[[評価]]"、例えば:"評価:[[5]]"。
[質問]
{question}
[アシスタントの回答の開始]
{answer}
[アシスタントの回答の終了]
最後にWeights & Biases Japanが運営するNejumi LLMリーダーボード Neoがある。これは従来の一問一答形式でのベンチマークと、Japanese MT-Benchによる総合評価を行っている。

ここでは、gpt-4-0125-previewのようなモデルが自然な会話の流れの中で指示に応えられる能力だけでなく、従来の一問一答形式でのベンチマークでも高性能だという結果を分かりやすく確認することができる。
この記事が気に入ったらサポートをしてみませんか?