GPT-3におけるtokensとは?

はじめに
@yutakikuchi_ です。
話題のChatGPT, GPT-3 APIなど多くの方が利用し始めているかと思います。
GPT-3に関してはOpenAIからWebAPIも一般公開されているのですが、従量課金対象となるtokensというのがちょっと分かりづらかったので、内容をここで整理します。
GPT-3における日本語のtokensとは
日本語でのtokensの数量は何か?というと結論としては、単語数でも無い、文字数でも無い、形態素数でも無い、何か独自のカウント指標となっています。現在OpenAIのGPT-3の価格表を見ると、4種類のモデルがあり、それぞれに対して、入力と出力の1000tokensごとに価格が決まっています。
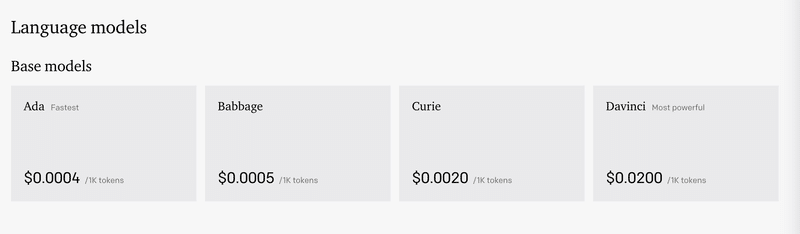
OpenAIの説明として、英語の場合は1000tokens = 約750単語(1 tokenが約0.75単語)のように定義されているのですが、日本語はこれが当てはまりません。おそらく日本語がマルチバイト文字列であるため。
Prices are per 1,000 tokens. You can think of tokens as pieces of words, where 1,000 tokens is about 750 words. This paragraph is 35 tokens.
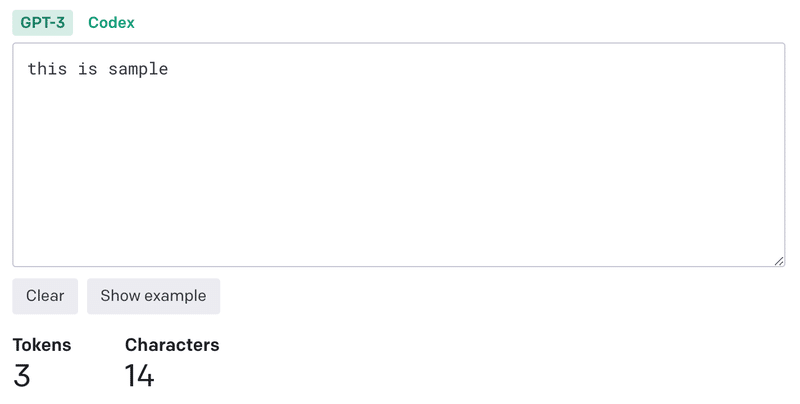
実際にOpenAIのtokenizerを使ってtokens量を測ってみます。
英語の 「This is sample」 は14文字、3tokens。対して、日本語で「これはテストをするための投稿内容になります。」は22文字、27tokens。なるほど、tokenの方が文字数より大きい数字としてカウントがされています。

GPT-2のTokenizerであればpythonのtransformer packageから使えるようですのでお手元で試したい方は是非。
結論として
日本語でのtokensの数量は何か?というと結論としては、単語数でも無い、文字数でも無い、形態素数でも無い、何か独自のカウント指標となっております。おそらく形態素とマルチバイトの関係で成り立っているかと。
日本語の場合は文字数よりtokensの方が数字的に大きくなるので、GPT-3を使う場合のtokens見積もりは余分に見ておくと無難です。
この記事が気に入ったらサポートをしてみませんか?