
【Python×SEO】コアアプデ分析のために順位帯ごとの変動をグラフ化する(Google Colab)

SEOをしているとサイトの健康状態を計るために「1位のクエリは○個、2~3位のクエリは○個」といったように、順位帯ごとの獲得クエリ数を計測されていることがあるかと思います。
しかしこの調査では、「○位帯から増減しているクエリは、どの順位帯からランクインしたものなのか、どの順位帯に移動したのか」がわからないという弱点があります。
例えば以下のように順位帯ごとのキーワード数をカウントしている表があるとして、2~3位のクエリ数は20減少しています。しかし、この減少している20クエリの変動先がどの順位帯なのかは、表からは読み解けません。

本来であれば2~3位のクエリのうち、いくつのクエリが1位に上昇しているのか、またいくつのクエリが4位以下に下降しているのかも調べたいところですが、この計算をExcelやスプレッドシートでするのはかなり面倒です。
そこで今回はPython(Google Colab)を使って、変動前の順位帯ごとに、変動後の順位帯のキーワード数をグラフ化する方法を紹介します。
※ローカルのJupyter Notebook上でももちろんOKです
このnoteのコードでは、通常の横棒グラフ(イメージ①)と、積み上げ棒グラフ(イメージ②)の2種類のグラフを作成できます。


手順①:AhrefsからCSVファイルのダウンロード
今回はAhrefsのOrganicKeywordsのデータから、「期間比較あり」「UTF-8」のデータを使用します。
OrganicKeywordsの画面を開いたら、以下の赤枠で囲ったドロップダウンから変動前の日付を選択しておきます。今回は3ヶ月前に設定しました。
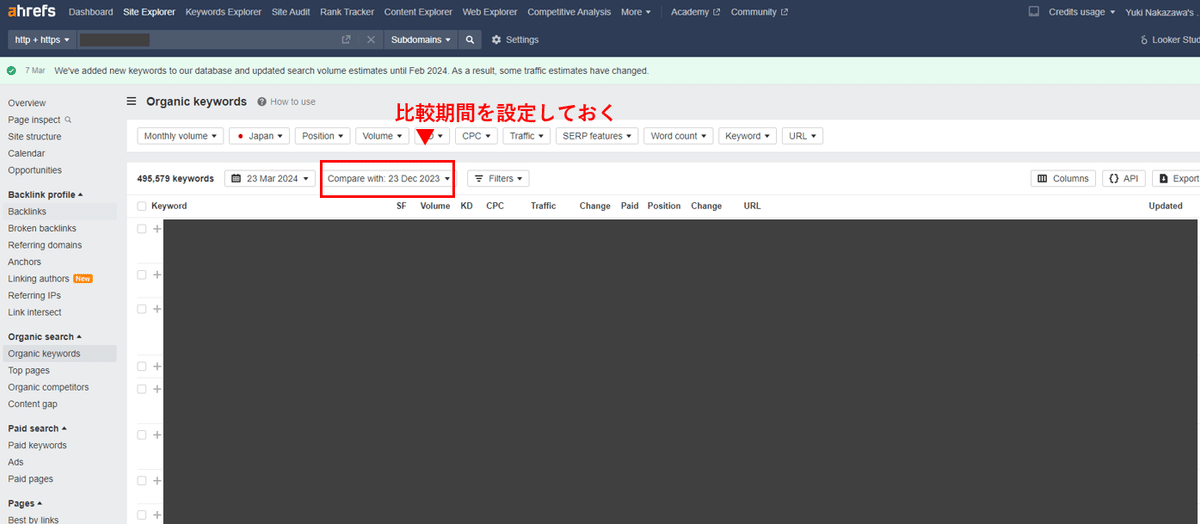
次に画面右端の「Export」ボタンをクリックして、以下のモーダルを表示させます。PolarsではUTF-16のCSVではエラーが出てしまうため、FormatをUTF-8に設定して、CSVをダウンロードします。

手順②:Google Colabにアクセスする
Google Colabにアクセスします。
アクセス時に表示されるポップアップから「ノートブックを新規作成」を選び、新しいノートブックを表示します。
=このnoteで実行するコードのまとめ=
次の章から各手順を説明するために、見出しを分けてコードを記載していますが、ひとつのセルにまとめて記載頂いても問題ありません。
手順③~⑩までをまとめたコードは以下になりますので、すぐに結果を表示したい方はこちらをお使いください。
#@title **1. hvPlotのインストール**
!pip install -q polars hvplot#@title **2. CSVファイルのアップロード**
from google.colab import files
uploaded = files.upload()#@title **3. データ処理からグラフ化まで**
import polars as pl
import hvplot.polars
import holoviews as hv
# 順位帯の処理のためのdict
position_labels = {
"1位": 1,
"2-3位": 3,
"4-6位": 6,
"7-10位": 10,
"11-20位": 20,
"21-100位":100,
"101位以下": 101
}
# positionを順位帯に変換する
def position_to_label(position, position_labels):
if position is None:
return "101位以下"
for label, order in position_labels.items():
if position <= order:
return label
return "101位以下"
# CSVファイルからDataFrameを作成する
file_name = next(iter(uploaded))
df = pl.read_csv(file_name, dtypes={"Position change": pl.Utf8})
df.columns = [column_name.replace(' ', '_').lower() for column_name in df.columns]
pivot_df = (
df.select(["keyword", "volume", "previous_position", "current_position", "previous_url", "current_url"])
# 順位を順位帯に変換
.with_columns(
previous_position = pl.col("previous_position").fill_null(101),
previous_position_label = pl.col("previous_position").map_elements(lambda x: position_to_label(x, position_labels), skip_nulls=False),
current_position = pl.col("current_position").fill_null(101),
current_position_label = pl.col("current_position").map_elements(lambda x: position_to_label(x, position_labels), skip_nulls=False)
)
# ピボット形式に変換
.pivot(values="keyword", index=["previous_position_label"], columns=["current_position_label"], aggregate_function="count")
.fill_null(0)
)
# 順位帯ごとのキーワード数がゼロの場合にエラーになるので、値がゼロの行・列を追加する
for label, order in position_labels.items():
new_column_name = label
default_value = 0
# すべてのカラムをUint32にcastしてからconcatする
# group_byのcountでは、dtypeがUint32のため
if new_column_name not in pivot_df.columns:
pivot_df = pivot_df.with_columns(pl.lit(default_value).cast(pl.UInt32).alias(new_column_name))
if label not in pivot_df.select("previous_position_label").to_series():
new_row = {col: 0 for col in pivot_df.columns}
new_df = pl.DataFrame([new_row]).cast(pl.UInt32).with_columns(
previous_position_label = pl.lit(label)
)
pivot_df =pl.concat([pivot_df, new_df])
melt_df = (
pivot_df.melt(id_vars=["previous_position_label"], variable_name="current_position_label", value_name="count")
.with_columns(
percent = pl.col("count") / pl.col("count").sum().over("previous_position_label"),
previous_position_order = pl.col("previous_position_label").replace(position_labels, default=None),
current_position_order = pl.col("current_position_label").replace(position_labels, default=None),
)
.sort(["previous_position_order", "current_position_order"], descending=[True, False])
)
hv.extension('bokeh')
plot = melt_df.hvplot.barh(
"previous_position_label",
by="current_position_label",
hover_cols=["keyword", "percent"],
xlabel="Previous_position",
ylabel="Current position count",
width=900,
height=500,
stacked=False,
alpha=0.7
)
plot上記のコードで実行された方は、手順③~⑩は読み飛ばしていただいて問題ありません。
手順③:PolarsとhvPlotのインストール
今回のコードではDataFrameの加工にはPolarsを、グラフの表示にはhvPlotというライブラリを使用します。
以下のコードをGoogle Colabのセルに貼り付けて、それぞれのライブラリをインストールしてください。
!pip install -q polars hvplotアイコンがぐるぐる回っているのが止まれば、インストールは完了です。
手順④:CSVファイルをColabにアップロード
Google Colabではファイルアップロードを簡単にするためのライブラリが用意されています。
以下のコードを実行すると「ファイル選択」というボタンが表示されるので、手順1でダウンロードしてきたCSVファイルをアップロードしてください。
from google.colab import files
uploaded = files.upload()手順⑤:必要なライブラリのインポート
はじめにデータ処理に使うPolarsや、グラフ表示に必要なhvplot・holoviewsをインポートします。
import polars as pl
import hvplot.polars
import holoviews as hv手順⑥:データ処理に必要な関数の定義
今回のコードではランクインしている順位を、以下のposition_labelsの順位帯に分類します。他の順位帯で分類したい場合は、position_labelsの分類を変更してください。
# 順位帯の処理のためのdict
position_labels = {
"1位": 1,
"2-3位": 3,
"4-6位": 6,
"7-10位": 10,
"11-20位": 20,
"21-100位":100,
"101位以下": 101
}
# positionを順位帯に変換する
def position_to_label(position, position_labels):
if position is None:
return "101位以下"
for label, order in position_labels.items():
if position <= order:
return label
return "101位以下"手順⑦:CSVファイルからDataFrameの作成
手順4でアップロードしたCSVファイルからPolrasのDataFrameを作成し、カラム名をスネークケース+小文字に統一します。
またAhrefsのOrganic Keywordsの比較データでは"Position change"列に"New"などの文字列が含まれている場合があるため、dtypesでpl.Utf8(文字列)を指定しています。
# CSVファイルからDataFrameを作成する
file_name = next(iter(uploaded))
df = pl.read_csv(file_name, dtypes={"Position change": pl.Utf8})
df.columns = [column_name.replace(' ', '_').lower() for column_name in df.columns手順⑧:変動前順位と変動後順位のピボットテーブルに変換
グラフ化する前に、一度ピボット形式のデータに変換します。
グラフ化自体はこの手順がなくても良いのですが、グラフの系列の並び順を統一するためにこの手順を挟んでいます。
# ピボット形式のデータを作成する
pivot_df = (
df.select(["keyword", "volume", "previous_position", "current_position", "previous_url", "current_url"])
# 順位を順位帯に変換
.with_columns(
previous_position = pl.col("previous_position").fill_null(101),
previous_position_label = pl.col("previous_position").map_elements(lambda x: position_to_label(x, position_labels), skip_nulls=False),
current_position = pl.col("current_position").fill_null(101),
current_position_label = pl.col("current_position").map_elements(lambda x: position_to_label(x, position_labels), skip_nulls=False)
)
# ピボット形式に変換
.pivot(values="keyword", index=["previous_position_label"], columns=["current_position_label"], aggregate_function="count")
.fill_null(0)
)
# 順位帯ごとのキーワード数がゼロの場合にエラーになるので、値がゼロの行・列を追加する
for label, order in position_labels.items():
new_column_name = label
default_value = 0
# すべてのカラムをUint32にcastしてからconcatする
# group_byのcountでは、dtypeがUint32のため
if new_column_name not in pivot_df.columns:
pivot_df = pivot_df.with_columns(pl.lit(default_value).cast(pl.UInt32).alias(new_column_name))
if label not in pivot_df.select("previous_position_label").to_series():
new_row = {col: 0 for col in pivot_df.columns}
new_df = pl.DataFrame([new_row]).cast(pl.UInt32).with_columns(
previous_position_label = pl.lit(label)
)
pivot_df = pl.concat([pivot_df, new_df])
このコードの実行後のpivot_dfの中身は、以下のようになっています。

手順⑨:ピボット形式のデータを溶かして、グラフ化のためのデータを追加する
ピボット形式にしたデータを分解し、「並び替えのためのカラム」と「変動前の順位帯ごとのキーワード数を分母としたときの、変動後の順位帯ごとのキーワード数の割合」を追加します。
またグラフ上での並び順を整理するために、DataFrameのソートも行います。
melt_df = (
pivot_df.melt(id_vars=["previous_position_label"], variable_name="current_position_label", value_name="count")
.with_columns(
percent = pl.col("count") / pl.col("count").sum().over("previous_position_label"),
previous_position_order = pl.col("previous_position_label").replace(position_labels, default=None),
current_position_order = pl.col("current_position_label").replace(position_labels, default=None),
)
.sort(["previous_position_order", "current_position_order"], descending=[True, False])
)手順⑩:グラフを表示する
最後に以下のコードを実行すれば、順位帯ごとの変動がグラフ化されます。
hv.extension('bokeh')
plot = melt_df.hvplot.barh(
"previous_position_label",
by="current_position_label",
hover_cols=["keyword", "percent"],
xlabel="Previous_position",
ylabel="Current position count",
width=900,
height=500,
stacked=False,
alpha=0.7
)
plot
またグラフにマウスカーソルを合わせると以下のように、分類ごとのキーワード数(count)や、割合(percent)が表示されます。
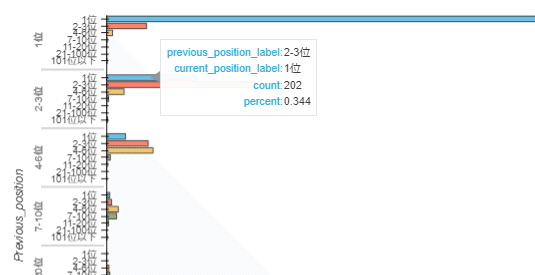
例えば「変動前2位~3位」の行を見ると、
1位に上昇したのは、202キーワード(34.4%)
2-3位をキープしているのは、340キーワード(57.9%)
4位に下降したのは、39キーワード(6.6%)
といったように変動後の順位帯がわかるので、2-3位にいたクエリについてはポジティブな動きがあったことがわかります。
このようなデータは、Excelやスプレッドシートでは面倒なので、Pythonを活用するメリットを受けられるかなと思います。
おまけ:積み上げグラフにするには
最後のグラフ化のコードにある"stacked"というパラメータをTrueに指定すると、積み上げの棒グラフで表示することもできます。
グラフが大きめに表示されることと、順位帯ごとのキーワード総数がわかりやすいので、適宜使い分けてください。
hv.extension('bokeh')
plot = melt_df.hvplot.barh(
"previous_position_label",
by="current_position_label",
hover_cols=["keyword", "percent"],
xlabel="Previous_position",
ylabel="Current position count",
width=900,
height=500,
stacked=True,
alpha=0.7
)
plot
まとめ
コードの量はやや多めではありますが、Google Colab上にノートブックさえ作っておけば、次から準備が必要なのはAhrefsのCSVだけになります。
このnoteのコードと、以前noteに書いたPythonと正規表現を使ったURLの分類を合わせれば、ページカテゴリごとに順位変動をグラフ化することも可能なので、コアアルゴリズムアップデートの分析等に役立てていただけますと幸いです。
この記事が気に入ったらサポートをしてみませんか?